Evaluation of a Robust Control System in Real-World Cable-Driven Parallel Robots
作者: Damir Nurtdinov, Aliaksei Korshuk, Alexei Kornaev, Alexander Maloletov
分类: cs.RO
发布日期: 2025-10-09
💡 一句话要点
评估TRPO控制方法以提升电缆驱动并联机器人性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 电缆驱动并联机器人 控制系统 强化学习 信任区域策略优化 鲁棒性 动态环境 PID控制器 性能评估
📋 核心要点
- 现有的控制方法在电缆驱动并联机器人中面临欠约束和时间离散的挑战,导致控制精度不足。
- 论文提出使用信任区域策略优化(TRPO)算法,以提高在复杂和动态环境中的控制稳定性和鲁棒性。
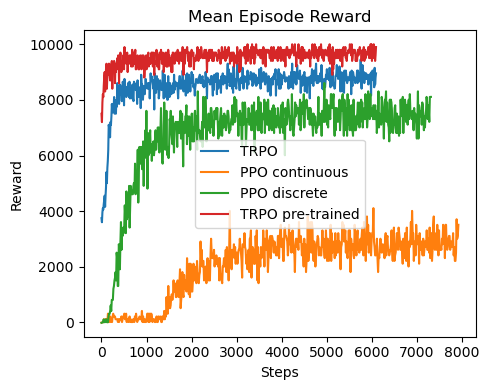
- 实验结果显示,TRPO在多种轨迹下的均方根误差最低,且在较大控制更新间隔下依然保持良好性能。
📝 摘要(中文)
本研究评估了经典与现代控制方法在实际电缆驱动并联机器人(CDPRs)中的表现,重点关注在有限时间离散下的欠约束系统。通过对比经典PID控制器与现代强化学习算法(如深度确定性策略梯度DDPG、近端策略优化PPO和信任区域策略优化TRPO),结果表明TRPO在不同轨迹下实现了最低的均方根误差(RMS),并在控制更新间隔较大时表现出良好的鲁棒性。TRPO在探索与利用之间的平衡能力使其在噪声较大的实际环境中实现稳定控制,降低了对高频传感器反馈和计算需求的依赖。这些发现突显了TRPO作为复杂机器人控制任务的鲁棒解决方案的潜力,具有在动态环境和未来传感器融合或混合控制策略中的应用前景。
🔬 方法详解
问题定义:本研究旨在解决电缆驱动并联机器人(CDPRs)在实际应用中面临的控制精度不足和鲁棒性差的问题,尤其是在欠约束和有限时间离散的情况下。现有的经典PID控制器在动态环境中表现不佳,难以满足高频控制需求。
核心思路:论文提出采用信任区域策略优化(TRPO)算法,旨在通过强化学习方法实现更为稳定和鲁棒的控制。TRPO能够在探索与利用之间找到平衡,从而在复杂环境中减少对高频传感器反馈的依赖。
技术框架:研究首先对比了经典PID控制器与TRPO等现代强化学习算法的性能,构建了一个包含多种控制策略的实验框架。主要模块包括环境建模、控制策略训练和性能评估。
关键创新:TRPO算法的引入是本研究的核心创新点,其通过优化策略的信任区域,显著提高了控制的稳定性和鲁棒性。这一方法与传统控制策略相比,能够更好地适应动态变化的环境。
关键设计:在实验中,TRPO的参数设置经过精心调整,包括学习率、折扣因子和策略更新频率等。此外,损失函数的设计也考虑了控制精度和稳定性之间的权衡,确保算法在实际应用中的有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TRPO算法在多种轨迹下实现了最低的均方根误差(RMS),相较于经典PID控制器,性能提升显著,尤其在控制更新间隔较大时,TRPO展现出更强的鲁棒性和稳定性。这些结果为复杂机器人控制任务提供了新的解决方案。
🎯 应用场景
该研究的成果可广泛应用于电缆驱动并联机器人在动态环境中的控制任务,如自动化制造、物流运输和服务机器人等领域。TRPO算法的鲁棒性和稳定性使其在未来的传感器融合和混合控制策略中具有重要的应用潜力,能够提升机器人在复杂环境中的适应能力。
📄 摘要(原文)
This study evaluates the performance of classical and modern control methods for real-world Cable-Driven Parallel Robots (CDPRs), focusing on underconstrained systems with limited time discretization. A comparative analysis is conducted between classical PID controllers and modern reinforcement learning algorithms, including Deep Deterministic Policy Gradient (DDPG), Proximal Policy Optimization (PPO), and Trust Region Policy Optimization (TRPO). The results demonstrate that TRPO outperforms other methods, achieving the lowest root mean square (RMS) errors across various trajectories and exhibiting robustness to larger time intervals between control updates. TRPO's ability to balance exploration and exploitation enables stable control in noisy, real-world environments, reducing reliance on high-frequency sensor feedback and computational demands. These findings highlight TRPO's potential as a robust solution for complex robotic control tasks, with implications for dynamic environments and future applications in sensor fusion or hybrid control strategies.