USIM and U0: A Vision-Language-Action Dataset and Model for General Underwater Robots
作者: Junwen Gu, Zhiheng Wu, Pengxuan Si, Shuang Qiu, Yukai Feng, Luoyang Sun, Laien Luo, Lianyi Yu, Jian Wang, Zhengxing Wu
分类: cs.RO
发布日期: 2025-10-09 (更新: 2025-10-15)
备注: Project Page: https://vincentgu2000.github.io/u0project/
💡 一句话要点
提出USIM水下视觉-语言-动作数据集和U0模型,用于通用水下机器人任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 水下机器人 视觉-语言-动作 多模态融合 模拟数据集 感知焦点增强
📋 核心要点
- 水下机器人缺乏大规模高质量数据集,限制了其在复杂环境下的自主多任务能力。
- 提出USIM数据集和U0模型,通过模拟数据和多模态融合提升水下机器人的感知和操作能力。
- 实验表明,U0模型在多种水下任务中表现出色,尤其在移动操作任务中显著优于基线方法。
📝 摘要(中文)
水下环境对机器人操作提出了独特的挑战,包括复杂的水动力学、有限的可见性和受限的通信。尽管数据驱动的方法已经推动了陆地机器人的具身智能,并实现了特定任务的自主水下机器人,但开发能够自主执行多项任务的水下智能仍然极具挑战性,因为大规模、高质量的水下数据集仍然稀缺。为了解决这些限制,我们引入了USIM,这是一个基于模拟的多任务视觉-语言-动作(VLA)数据集,用于水下机器人。USIM包含来自1852条轨迹的超过561K帧,总计约15.6小时的BlueROV2交互,涵盖9个不同场景中的20个任务,范围从视觉导航到移动操作。在此数据集的基础上,我们提出了U0,一个用于通用水下机器人的VLA模型,它通过多模态融合集成了双目视觉和其他传感器模态,并进一步结合了一个基于卷积-注意力的感知焦点增强模块(CAP),以提高空间理解和移动操作能力。在检查、避障、扫描和动态跟踪等任务中,该框架实现了80%的成功率,而在具有挑战性的移动操作任务中,与基线方法相比,到目标的距离减少了21.2%,证明了其有效性。USIM和U0表明,VLA模型可以有效地应用于水下机器人应用,为可扩展的数据集构建、改进的任务自主性和智能通用水下机器人的实际实现奠定基础。
🔬 方法详解
问题定义:现有水下机器人研究面临缺乏大规模、高质量数据集的挑战,这限制了数据驱动方法在水下环境中的应用。特别是对于需要视觉、语言和动作相结合的复杂任务,如水下检查、目标抓取等,现有方法难以实现通用性和鲁棒性。现有方法在水下环境下的感知能力不足,难以应对水下光照变化、水体浑浊等问题。
核心思路:论文的核心思路是利用模拟环境生成大规模的视觉-语言-动作(VLA)数据集USIM,并在此基础上训练一个通用的水下机器人模型U0。通过模拟数据降低数据获取成本,并利用多模态融合和感知焦点增强模块提升模型在水下环境中的感知和操作能力。
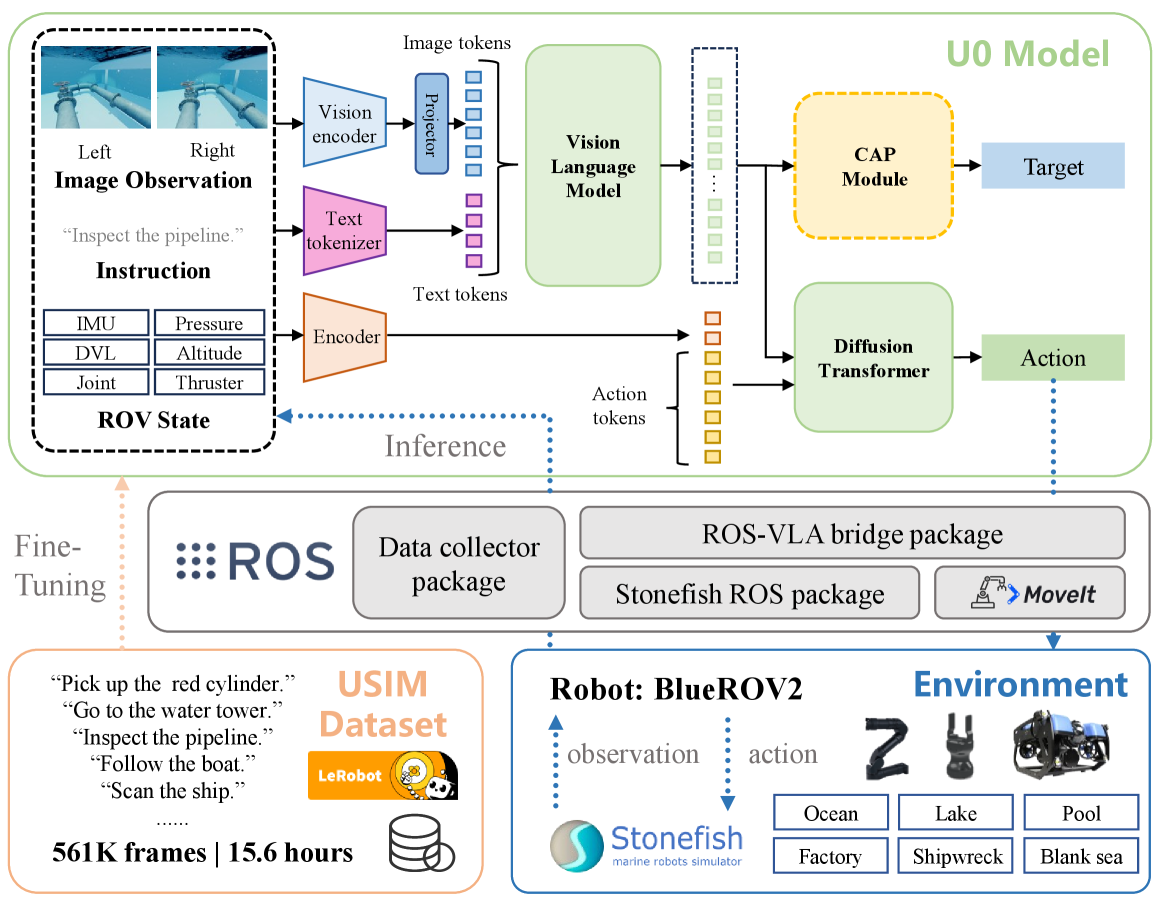
技术框架:U0模型的技术框架主要包括以下几个部分:1) 多模态输入:模型接收双目视觉图像、IMU数据等多种传感器数据作为输入。2) 多模态融合:利用多模态融合技术将不同模态的数据进行整合,以获得更全面的环境信息。3) 感知焦点增强模块(CAP):该模块利用卷积和注意力机制,增强模型对关键区域的感知能力,提高空间理解和移动操作的精度。4) 动作预测:模型根据融合后的环境信息,预测机器人的动作指令。
关键创新:论文的关键创新在于:1) 提出了大规模的模拟水下VLA数据集USIM,为水下机器人研究提供了数据基础。2) 设计了感知焦点增强模块(CAP),有效提升了模型在水下环境中的感知能力和操作精度。3) 提出了一个通用的水下机器人模型U0,能够处理多种水下任务。
关键设计:USIM数据集包含20个任务,涵盖视觉导航、移动操作等多种类型。U0模型采用多模态融合策略,将双目视觉、IMU等传感器数据进行整合。CAP模块采用卷积和注意力机制,具体结构未知(原文未详细描述)。损失函数未知(原文未详细描述)。
🖼️ 关键图片


📊 实验亮点
U0模型在多种水下任务中取得了显著的性能提升。在检查、避障、扫描和动态跟踪等任务中,成功率达到80%。在具有挑战性的移动操作任务中,与基线方法相比,到目标的距离减少了21.2%。这些结果表明,USIM数据集和U0模型能够有效提升水下机器人的自主性和智能化水平。
🎯 应用场景
该研究成果可应用于水下基础设施巡检、水下搜救、海洋资源勘探、水下环境监测等领域。通过提高水下机器人的自主性和智能化水平,可以降低水下作业的成本和风险,并拓展水下机器人的应用范围。未来,该研究可以进一步推广到其他复杂环境下的机器人应用,如深海、太空等。
📄 摘要(原文)
Underwater environments present unique challenges for robotic operation, including complex hydrodynamics, limited visibility, and constrained communication. Although data-driven approaches have advanced embodied intelligence in terrestrial robots and enabled task-specific autonomous underwater robots, developing underwater intelligence capable of autonomously performing multiple tasks remains highly challenging, as large-scale, high-quality underwater datasets are still scarce. To address these limitations, we introduce USIM, a simulation-based multi-task Vision-Language-Action (VLA) dataset for underwater robots. USIM comprises over 561K frames from 1,852 trajectories, totaling approximately 15.6 hours of BlueROV2 interactions across 20 tasks in 9 diverse scenarios, ranging from visual navigation to mobile manipulation. Building upon this dataset, we propose U0, a VLA model for general underwater robots, which integrates binocular vision and other sensor modalities through multimodal fusion, and further incorporates a convolution-attention-based perception focus enhancement module (CAP) to improve spatial understanding and mobile manipulation. Across tasks such as inspection, obstacle avoidance, scanning, and dynamic tracking, the framework achieves a success rate of 80%, while in challenging mobile manipulation tasks, it reduces the distance to the target by 21.2% compared with baseline methods, demonstrating its effectiveness. USIM and U0 show that VLA models can be effectively applied to underwater robotic applications, providing a foundation for scalable dataset construction, improved task autonomy, and the practical realization of intelligent general underwater robots.