DM1: MeanFlow with Dispersive Regularization for 1-Step Robotic Manipulation
作者: Guowei Zou, Haitao Wang, Hejun Wu, Yukun Qian, Yuhang Wang, Weibing Li
分类: cs.RO, cs.AI
发布日期: 2025-10-09
备注: Website with code: https://guowei-zou.github.io/dm1/
💡 一句话要点
DM1:通过分散正则化的MeanFlow实现单步机器人操作,解决表示崩溃问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 Flow模型 表示学习 分散正则化 单步控制
📋 核心要点
- 现有基于Flow的机器人操作策略存在表示崩溃问题,无法区分相似的视觉表示,导致精确操作任务失败。
- DM1通过在MeanFlow中引入分散正则化,鼓励训练批次间的多样化表示,从而防止表示崩溃,同时保持单步推理效率。
- 实验表明,DM1在推理速度和成功率方面均优于现有方法,并在真实机器人部署中表现出良好的迁移能力。
📝 摘要(中文)
本文提出DM1(具有分散正则化的MeanFlow,用于单步机器人操作),这是一种新颖的Flow Matching框架,它将分散正则化集成到MeanFlow中,以防止表示崩溃,同时保持单步效率。DM1在不同的中间嵌入层采用多种分散正则化变体,鼓励跨训练批次的多样化表示,而无需引入额外的网络模块或专门的训练程序。在RoboMimic基准测试上的实验表明,DM1实现了20-40倍的更快推理速度(0.07秒 vs. 2-3.5秒),并将成功率提高了10-20个百分点,其中Lift任务的成功率达到99%,而基线为85%。在Franka Panda机器人上的真实部署进一步验证了DM1可以有效地从模拟转移到物理世界。据我们所知,这是第一项利用表示正则化使基于Flow的策略在机器人操作中实现强大性能的工作,为高效和鲁棒的操作建立了一种简单而强大的方法。
🔬 方法详解
问题定义:现有的基于Flow的机器人操作策略在学习多模态动作分布时,容易出现表示崩溃的问题。这意味着模型无法区分相似的视觉输入,导致在需要精细控制的操作任务中表现不佳。现有方法虽然能够生成动作,但精度和鲁棒性不足,限制了其在实际机器人应用中的潜力。
核心思路:DM1的核心思路是在MeanFlow框架中引入分散正则化,以鼓励模型学习更具区分性的表示。通过在不同的中间嵌入层应用多种分散正则化变体,DM1促使模型在训练过程中产生更多样化的特征表示,从而避免表示崩溃。这种方法旨在提高模型对视觉输入的敏感度,使其能够更准确地预测所需的动作。
技术框架:DM1基于MeanFlow框架,这是一个单步动作生成模型。其主要流程包括:首先,将视觉输入编码为嵌入向量;然后,通过一系列Flow层将该嵌入向量转换为动作分布;最后,从该分布中采样得到最终的动作。DM1的关键在于在Flow层的中间嵌入层中引入分散正则化。
关键创新:DM1最重要的技术创新点在于将分散正则化应用于Flow-based的机器人操作策略中。与现有方法相比,DM1不需要额外的网络模块或专门的训练程序,即可有效地防止表示崩溃,提高模型的精度和鲁棒性。这是首次将表示正则化成功应用于基于Flow的机器人操作策略中。
关键设计:DM1的关键设计包括:1) 在多个中间嵌入层应用分散正则化,以确保不同层次的特征表示都具有多样性;2) 使用多种分散正则化变体,以进一步增强表示的多样性;3) 通过调整正则化系数来平衡表示的多样性和模型的性能。损失函数包括Flow Matching损失和分散正则化损失,通过联合优化这两个损失来训练模型。
🖼️ 关键图片
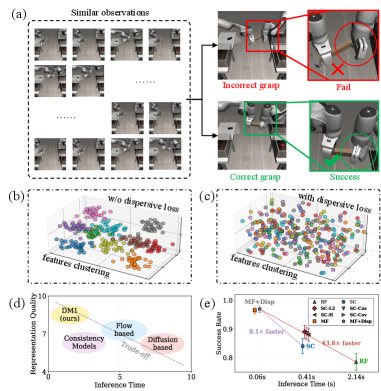
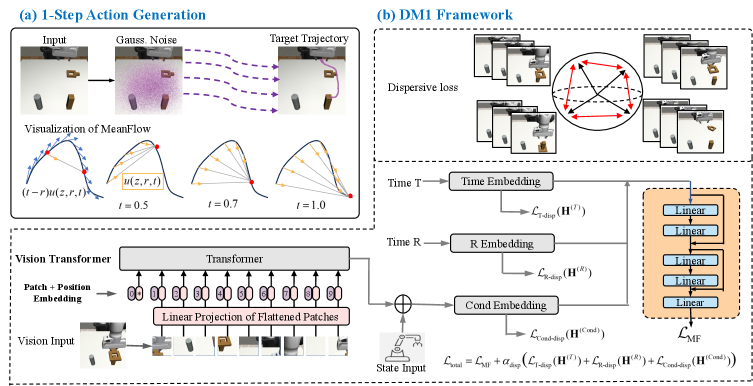
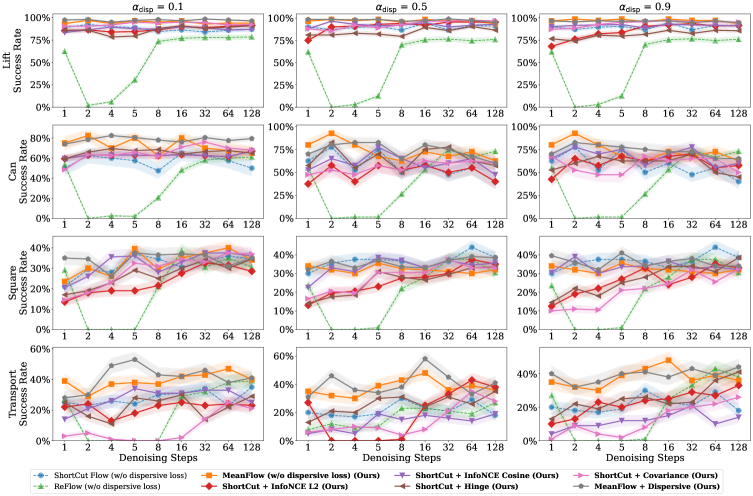
📊 实验亮点
DM1在RoboMimic基准测试中表现出色,推理速度比现有方法快20-40倍(0.07秒 vs. 2-3.5秒),成功率提高了10-20个百分点。在Lift任务中,DM1的成功率达到了99%,而基线方法仅为85%。此外,DM1在Franka Panda机器人上的真实部署也验证了其良好的迁移能力,表明该方法具有很强的实用价值。
🎯 应用场景
DM1具有广泛的应用前景,可用于各种机器人操作任务,例如物体抓取、装配、导航等。该方法能够提高机器人在复杂环境中的操作精度和鲁棒性,使其能够更好地适应不同的任务需求。此外,DM1还可以应用于其他需要学习多模态动作分布的领域,例如自动驾驶、游戏AI等。未来,DM1有望成为机器人操作领域的重要技术,推动机器人技术的进一步发展。
📄 摘要(原文)
The ability to learn multi-modal action distributions is indispensable for robotic manipulation policies to perform precise and robust control. Flow-based generative models have recently emerged as a promising solution to learning distributions of actions, offering one-step action generation and thus achieving much higher sampling efficiency compared to diffusion-based methods. However, existing flow-based policies suffer from representation collapse, the inability to distinguish similar visual representations, leading to failures in precise manipulation tasks. We propose DM1 (MeanFlow with Dispersive Regularization for One-Step Robotic Manipulation), a novel flow matching framework that integrates dispersive regularization into MeanFlow to prevent collapse while maintaining one-step efficiency. DM1 employs multiple dispersive regularization variants across different intermediate embedding layers, encouraging diverse representations across training batches without introducing additional network modules or specialized training procedures. Experiments on RoboMimic benchmarks show that DM1 achieves 20-40 times faster inference (0.07s vs. 2-3.5s) and improves success rates by 10-20 percentage points, with the Lift task reaching 99% success over 85% of the baseline. Real-robot deployment on a Franka Panda further validates that DM1 transfers effectively from simulation to the physical world. To the best of our knowledge, this is the first work to leverage representation regularization to enable flow-based policies to achieve strong performance in robotic manipulation, establishing a simple yet powerful approach for efficient and robust manipulation.