IntentionVLA: Generalizable and Efficient Embodied Intention Reasoning for Human-Robot Interaction
作者: Yandu Chen, Kefan Gu, Yuqing Wen, Yucheng Zhao, Tiancai Wang, Liqiang Nie
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-09
💡 一句话要点
IntentionVLA:面向人机交互的可泛化高效具身意图推理框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 意图推理 具身智能 视觉语言动作模型 课程学习 机器人控制 预训练模型
📋 核心要点
- 现有VLA模型缺乏推理能力,无法处理复杂人机交互中隐式的意图推理。
- IntentionVLA通过课程学习范式和高效推理机制,提升模型对人类意图的理解和执行能力。
- 实验表明,IntentionVLA在多种任务上显著优于现有方法,尤其在零样本人机交互中表现出色。
📝 摘要(中文)
Vision-Language-Action (VLA) 模型利用预训练的视觉-语言模型 (VLM) 将感知与机器人控制相结合,为通用具身智能提供了一条有希望的途径。然而,当前最先进的 VLA 主要在与具身场景相关性有限的多模态任务上进行预训练,然后进行微调以将显式指令映射到动作。因此,由于缺乏推理密集型预训练和推理引导的操作,这些模型无法执行复杂、真实世界交互所需的隐式人类意图推理。为了克服这些限制,我们提出了 IntentionVLA,这是一个具有课程学习范式和高效推理机制的 VLA 框架。我们提出的方法首先利用精心设计的推理数据,结合意图推断、空间定位和紧凑的具身推理,赋予模型推理和感知能力。在随后的微调阶段,IntentionVLA 采用紧凑的推理输出作为动作生成的上下文指导,从而在间接指令下实现快速推理。实验结果表明,IntentionVLA 显著优于 π0,在直接指令下的成功率提高了 18%,在意图指令下比 ECoT 高出 28%。在分布外意图任务中,IntentionVLA 的成功率是所有基线的两倍以上,并进一步实现了 40% 成功率的零样本人机交互。这些结果表明 IntentionVLA 是下一代人机交互 (HRI) 系统的一个有希望的范例。
🔬 方法详解
问题定义:现有VLA模型主要依赖于显式指令到动作的映射,缺乏对人类隐式意图的推理能力。这限制了它们在复杂、真实的人机交互场景中的应用,因为人类通常不会给出非常明确的指令,而是通过行为暗示意图。现有方法缺乏推理密集型预训练和推理引导的操作,导致性能不佳。
核心思路:IntentionVLA的核心思路是通过课程学习的方式,首先让模型学习推理能力,然后利用推理结果指导动作生成。这种方法将意图推理作为动作生成的前提,使得模型能够理解人类的隐式意图,并做出相应的动作。通过将推理和动作生成解耦,可以提高模型的泛化能力和效率。
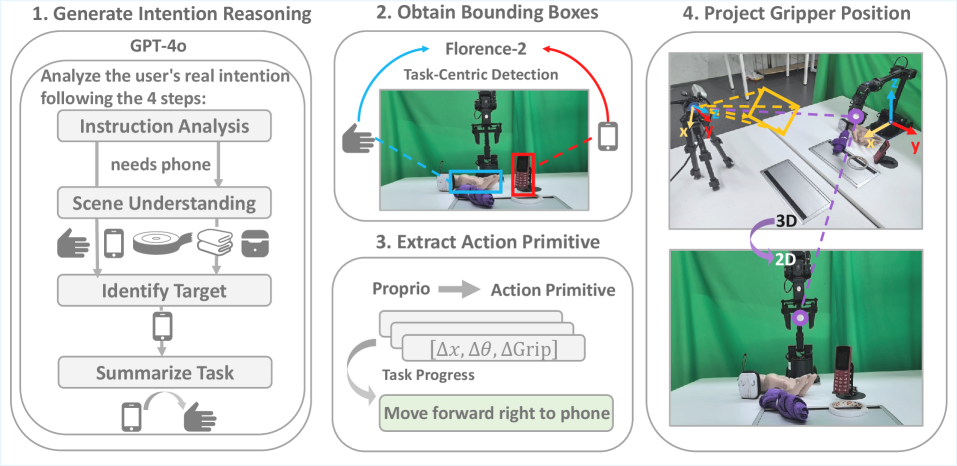
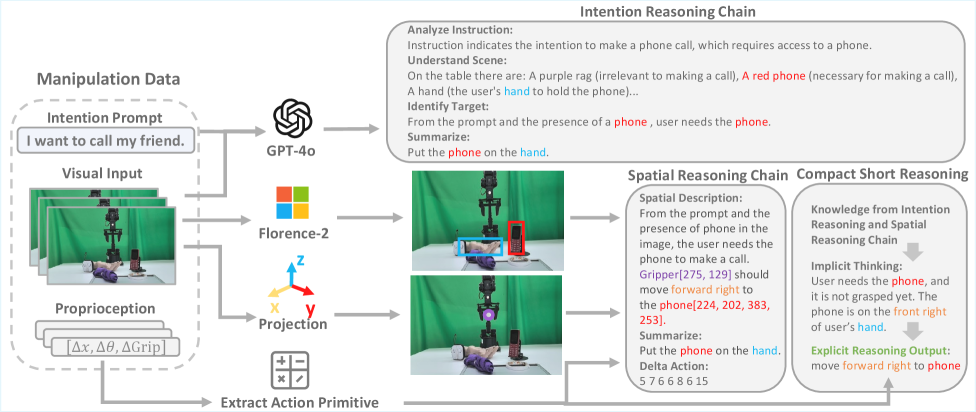
技术框架:IntentionVLA框架包含预训练和微调两个阶段。在预训练阶段,模型学习意图推断、空间定位和具身推理等任务。在微调阶段,模型利用预训练阶段学到的推理能力,将推理结果作为上下文信息,指导动作生成。整体流程是:输入视觉和语言信息,经过意图推理模块得到推理结果,然后将推理结果和原始输入一起输入到动作生成模块,最终生成机器人动作。
关键创新:IntentionVLA的关键创新在于引入了课程学习范式,并设计了专门用于意图推理的预训练数据。通过这种方式,模型能够学习到更强的推理能力,从而更好地理解人类的隐式意图。此外,IntentionVLA还采用了高效的推理机制,使得模型能够在间接指令下快速推理。
关键设计:IntentionVLA的关键设计包括:1) 精心设计的推理数据集,包含意图推断、空间定位和具身推理等任务;2) 课程学习策略,先训练推理能力,再训练动作生成能力;3) 使用紧凑的推理输出作为动作生成的上下文信息,提高推理效率;4) 损失函数的设计,可能包括意图推理的损失和动作生成的损失,具体细节未知。
🖼️ 关键图片

📊 实验亮点
IntentionVLA在直接指令下的成功率比π0高18%,在意图指令下比ECoT高28%。在分布外意图任务中,IntentionVLA的成功率是所有基线的两倍以上。此外,IntentionVLA还实现了40%成功率的零样本人机交互,展示了其强大的泛化能力。
🎯 应用场景
IntentionVLA在人机协作、智能家居、辅助机器人等领域具有广泛的应用前景。它可以使机器人能够理解人类的意图,从而更好地为人类服务。例如,在智能家居中,机器人可以根据人类的行为推断其需求,并自动完成相应的任务。在辅助机器人领域,机器人可以帮助残疾人完成日常生活中的各种活动。
📄 摘要(原文)
Vision-Language-Action (VLA) models leverage pretrained vision-language models (VLMs) to couple perception with robotic control, offering a promising path toward general-purpose embodied intelligence. However, current SOTA VLAs are primarily pretrained on multimodal tasks with limited relevance to embodied scenarios, and then finetuned to map explicit instructions to actions. Consequently, due to the lack of reasoning-intensive pretraining and reasoning-guided manipulation, these models are unable to perform implicit human intention reasoning required for complex, real-world interactions. To overcome these limitations, we propose \textbf{IntentionVLA}, a VLA framework with a curriculum training paradigm and an efficient inference mechanism. Our proposed method first leverages carefully designed reasoning data that combine intention inference, spatial grounding, and compact embodied reasoning, endowing the model with both reasoning and perception capabilities. In the following finetuning stage, IntentionVLA employs the compact reasoning outputs as contextual guidance for action generation, enabling fast inference under indirect instructions. Experimental results show that IntentionVLA substantially outperforms $π_0$, achieving 18\% higher success rates with direct instructions and 28\% higher than ECoT under intention instructions. On out-of-distribution intention tasks, IntentionVLA achieves over twice the success rate of all baselines, and further enables zero-shot human-robot interaction with 40\% success rate. These results highlight IntentionVLA as a promising paradigm for next-generation human-robot interaction (HRI) systems.