TIGeR: Tool-Integrated Geometric Reasoning in Vision-Language Models for Robotics
作者: Yi Han, Cheng Chi, Enshen Zhou, Shanyu Rong, Jingkun An, Pengwei Wang, Zhongyuan Wang, Lu Sheng, Shanghang Zhang
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-08 (更新: 2025-10-09)
备注: 9 pages, 6 figures
💡 一句话要点
TIGeR:通过工具集成几何推理,提升视觉-语言模型在机器人领域的精度
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉-语言模型 机器人操作 几何推理 工具集成 代码生成
📋 核心要点
- 现有视觉-语言模型在机器人几何推理中精度不足,无法满足实际操作的厘米级要求。
- TIGeR框架通过集成外部工具,使模型能够进行精确的几何计算,而非依赖内部神经网络。
- TIGeR在几何推理基准测试和真实机器人操作中均表现出色,达到厘米级精度。
📝 摘要(中文)
视觉-语言模型(VLMs)在空间推理方面表现出卓越的能力,但本质上仍受限于定性精度,缺乏真实世界机器人所需的计算精度。现有方法未能利用深度传感器和相机校准提供的度量线索,而是将几何问题简化为模式识别任务,无法提供机器人操作所需的厘米级精度。我们提出了TIGeR(工具集成几何推理),这是一个新颖的框架,通过使VLMs能够生成和执行精确的几何计算,从而将VLMs从感知估计器转变为几何计算机。TIGeR不试图将复杂的几何操作内置于神经网络中,而是使模型能够识别几何推理需求,合成适当的计算代码,并调用专门的库进行精确计算。为了支持这种范式,我们引入了TIGeR-300K,这是一个全面的、面向工具调用的数据集,涵盖点变换、姿态估计和空间兼容性验证,包含工具调用序列和中间计算。通过结合监督微调(SFT)和强化微调(RFT)的两阶段训练流程,以及我们提出的分层奖励设计,TIGeR在几何推理基准测试中实现了SOTA性能,并在真实世界的机器人操作任务中展示了厘米级的精度。
🔬 方法详解
问题定义:现有视觉-语言模型在机器人操作中,无法精确处理几何问题,缺乏对深度信息和相机参数的有效利用,导致精度不足,难以满足实际操作需求。现有方法将几何问题简化为模式识别,忽略了精确的几何计算。
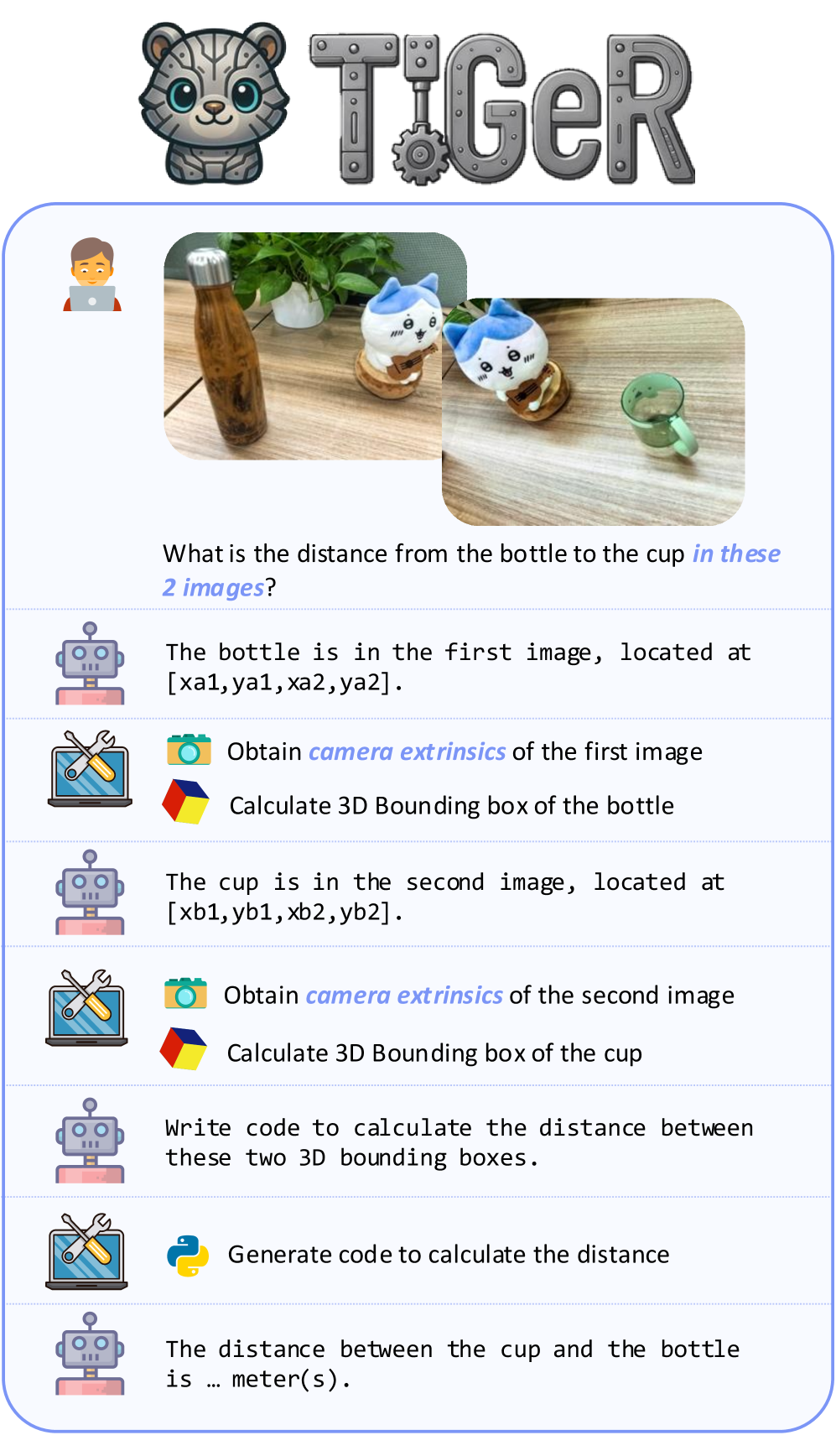
核心思路:TIGeR的核心思想是将视觉-语言模型与外部几何计算工具集成,使其能够识别几何推理需求,并生成相应的代码来调用这些工具进行精确计算。这种方法避免了将复杂的几何运算内置于神经网络中,从而提高了精度和可解释性。
技术框架:TIGeR框架包含以下主要阶段:1) 几何推理需求识别:视觉-语言模型分析输入,判断是否需要进行几何计算。2) 代码生成:根据推理需求,生成调用外部工具的计算代码。3) 工具调用与计算:执行生成的代码,利用外部工具进行精确的几何计算。4) 结果整合:将计算结果整合到视觉-语言模型的输出中。
关键创新:TIGeR的关键创新在于将视觉-语言模型与外部几何计算工具解耦,通过代码生成的方式实现二者的集成。这种方法使得模型能够利用外部工具的精确计算能力,从而显著提高几何推理的精度。此外,TIGeR-300K数据集的构建也为模型的训练提供了重要支撑。
关键设计:TIGeR使用两阶段训练流程:首先进行监督微调(SFT),使模型学习生成正确的代码;然后进行强化微调(RFT),利用分层奖励设计,鼓励模型生成更高效、更精确的代码。分层奖励包括:1) 任务完成奖励;2) 代码效率奖励;3) 几何精度奖励。此外,TIGeR-300K数据集包含了多种几何推理任务,如点变换、姿态估计和空间兼容性验证,覆盖了机器人操作中常见的几何计算需求。
🖼️ 关键图片


📊 实验亮点
TIGeR在几何推理基准测试中取得了SOTA性能,并在真实世界的机器人操作任务中展示了厘米级的精度。与现有方法相比,TIGeR能够更精确地处理几何问题,从而显著提高了机器人的操作性能。TIGeR-300K数据集的构建也为相关研究提供了宝贵的数据资源。
🎯 应用场景
TIGeR框架可应用于各种机器人操作任务,如物体抓取、放置、装配等。通过提高机器人对环境几何信息的理解和处理能力,可以显著提升机器人的操作精度和鲁棒性。该研究的潜在应用领域包括工业自动化、医疗机器人、家庭服务机器人等,有望推动机器人技术在实际场景中的广泛应用。
📄 摘要(原文)
Vision-Language Models (VLMs) have shown remarkable capabilities in spatial reasoning, yet they remain fundamentally limited to qualitative precision and lack the computational precision required for real-world robotics. Current approaches fail to leverage metric cues from depth sensors and camera calibration, instead reducing geometric problems to pattern recognition tasks that cannot deliver the centimeter-level accuracy essential for robotic manipulation. We present TIGeR (Tool-Integrated Geometric Reasoning), a novel framework that transforms VLMs from perceptual estimators to geometric computers by enabling them to generate and execute precise geometric computations through external tools. Rather than attempting to internalize complex geometric operations within neural networks, TIGeR empowers models to recognize geometric reasoning requirements, synthesize appropriate computational code, and invoke specialized libraries for exact calculations. To support this paradigm, we introduce TIGeR-300K, a comprehensive tool-invocation-oriented dataset covering point transformations, pose estimation, and spatial compatibility verification, complete with tool invocation sequences and intermediate computations. Through a two-stage training pipeline combining supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT) with our proposed hierarchical reward design, TIGeR achieves SOTA performance on geometric reasoning benchmarks while demonstrating centimeter-level precision in real-world robotic manipulation tasks.