DPL: Depth-only Perceptive Humanoid Locomotion via Realistic Depth Synthesis and Cross-Attention Terrain Reconstruction
作者: Jingkai Sun, Gang Han, Pihai Sun, Wen Zhao, Jiahang Cao, Jiaxu Wang, Yijie Guo, Qiang Zhang
分类: cs.RO
发布日期: 2025-10-08 (更新: 2025-10-10)
💡 一句话要点
提出DPL框架,通过深度信息实现类人机器人在复杂地形上的稳健运动
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 类人机器人 深度感知 地形重建 强化学习 交叉注意力 深度图像合成 运动控制
📋 核心要点
- 现有基于深度图像的端到端学习方法,存在训练效率低和深度感知的模拟到真实差距大的问题。
- 该论文提出一种结合地形感知运动策略、交叉注意力Transformer和逼真深度图像合成的框架。
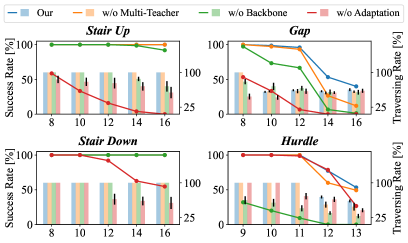
- 实验表明,该框架在全尺寸类人机器人上实现了敏捷和自适应的运动,地形重建误差降低超过30%。
📝 摘要(中文)
本文提出了一种新颖的框架,用于实现仅依赖深度信息的类人机器人感知运动。该框架紧密结合了三个关键组件:(1)具有盲骨干的地形感知运动策略,利用预训练的基于高程图的感知来指导强化学习,同时最大限度地减少视觉输入;(2)多模态交叉注意力Transformer,从嘈杂的深度图像中重建结构化的地形表示;(3)逼真的深度图像合成方法,采用自遮挡感知光线投射和噪声感知建模来合成逼真的深度观测,从而将地形重建误差降低30%以上。这种组合能够在有限的数据和硬件资源下实现高效的策略训练,同时保留泛化所需的关键地形特征。我们在全尺寸类人机器人上验证了该框架,展示了其在各种具有挑战性的地形上的敏捷和自适应运动能力。
🔬 方法详解
问题定义:现有类人机器人地形感知运动方法主要依赖于深度图像的端到端学习或高程图。前者训练效率低,且存在模拟到真实的鸿沟;后者依赖于多个视觉传感器和定位系统,导致延迟和鲁棒性降低。因此,需要一种更高效、更鲁棒的,仅依赖深度信息的类人机器人运动控制方法。
核心思路:该论文的核心思路是利用逼真的深度图像合成技术,结合预训练的地形感知运动策略和多模态交叉注意力Transformer,从而实现仅依赖深度信息的类人机器人在复杂地形上的稳健运动。通过逼真的深度图像合成,减少模拟到真实的差距;通过预训练的策略,提高训练效率;通过Transformer,从噪声深度图像中重建地形。
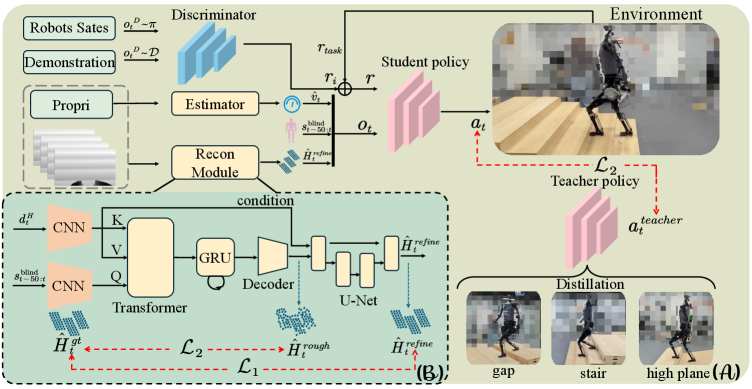
技术框架:该框架包含三个主要模块:(1)地形感知运动策略(Terrain-Aware Locomotion Policy with a Blind Backbone):利用预训练的基于高程图的策略作为先验知识,指导强化学习,减少对视觉信息的依赖。(2)多模态交叉注意力Transformer(Multi-Modality Cross-Attention Transformer):从噪声深度图像中重建结构化的地形表示,提高地形感知的准确性。(3)逼真的深度图像合成方法(Realistic Depth Images Synthetic Method):通过自遮挡感知光线投射和噪声感知建模,生成逼真的深度图像,缩小模拟和真实环境之间的差距。
关键创新:该论文的关键创新在于:(1)将预训练的高程图策略与深度图像输入相结合,减少了对大量视觉数据的需求。(2)提出了多模态交叉注意力Transformer,用于从噪声深度图像中重建地形,提高了地形感知的鲁棒性。(3)开发了逼真的深度图像合成方法,有效缩小了模拟和真实环境之间的差距,提高了策略的泛化能力。
关键设计:在深度图像合成方面,考虑了自遮挡效应,并对深度图像中的噪声进行了建模,以提高合成图像的真实性。Transformer网络采用了交叉注意力机制,融合了深度图像和预训练策略的信息,从而更准确地重建地形。损失函数的设计旨在最小化重建地形与真实地形之间的差异,并鼓励策略学习到稳健的运动控制。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架能够有效地从噪声深度图像中重建地形,并将地形重建误差降低了30%以上。在全尺寸类人机器人上的实验验证了该框架在各种复杂地形上的敏捷和自适应运动能力。与传统的基于高程图的方法相比,该方法在降低传感器依赖和提高鲁棒性方面具有显著优势。
🎯 应用场景
该研究成果可应用于搜救机器人、巡检机器人、以及其他需要在复杂地形中进行作业的机器人。通过仅依赖深度信息,降低了对昂贵传感器的依赖,提高了机器人的自主性和适应性,使其能够在更广泛的环境中执行任务。未来,该技术有望应用于外太空探索、灾后救援等领域。
📄 摘要(原文)
Recent advancements in legged robot perceptive locomotion have shown promising progress. However, terrain-aware humanoid locomotion remains largely constrained to two paradigms: depth image-based end-to-end learning and elevation map-based methods. The former suffers from limited training efficiency and a significant sim-to-real gap in depth perception, while the latter depends heavily on multiple vision sensors and localization systems, resulting in latency and reduced robustness. To overcome these challenges, we propose a novel framework that tightly integrates three key components: (1) Terrain-Aware Locomotion Policy with a Blind Backbone, which leverages pre-trained elevation map-based perception to guide reinforcement learning with minimal visual input; (2) Multi-Modality Cross-Attention Transformer, which reconstructs structured terrain representations from noisy depth images; (3) Realistic Depth Images Synthetic Method, which employs self-occlusion-aware ray casting and noise-aware modeling to synthesize realistic depth observations, achieving over 30\% reduction in terrain reconstruction error. This combination enables efficient policy training with limited data and hardware resources, while preserving critical terrain features essential for generalization. We validate our framework on a full-sized humanoid robot, demonstrating agile and adaptive locomotion across diverse and challenging terrains.