Sampling Strategies for Robust Universal Quadrupedal Locomotion Policies
作者: David Rytz, Kim Tien Ly, Ioannis Havoutis
分类: cs.RO
发布日期: 2025-10-08
💡 一句话要点
提出基于配置采样的通用四足机器人鲁棒运动策略,实现零样本迁移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 运动控制 鲁棒性 参数随机化
📋 核心要点
- 现有四足机器人运动策略难以泛化到不同物理参数和控制增益的机器人,限制了其通用性和实际应用。
- 通过对机器人物理参数和关节PD增益进行采样,训练单个强化学习策略,使其能够适应多种配置,提高策略的鲁棒性。
- 实验表明,该方法在仿真中对多种四足机器人有效,并成功零样本部署到ANYmal机器人上,验证了其在现实世界的可行性。
📝 摘要(中文)
本研究关注配置变化的采样策略,旨在为四足机器人生成鲁棒的通用运动策略。我们研究了物理机器人参数和关节比例-微分(PD)增益的采样对训练单个强化学习策略的影响,该策略可以泛化到多个参数配置。比较了三种基本的关节增益采样策略:(1)使用质量到增益的线性函数和多项式函数映射的参数采样,(2)基于性能的自适应滤波,以及(3)均匀随机采样。我们通过使用标称先验和参考模型来偏置配置,从而提高了策略的鲁棒性。所有训练都在RaiSim上进行,在各种不同的四足机器人上进行了仿真测试,并使用ANYmal四足机器人进行了零样本硬件部署。与多个基线实现相比,我们的结果表明,需要显著的关节控制器增益随机化才能鲁棒地弥合仿真到现实的差距。
🔬 方法详解
问题定义:现有四足机器人运动控制方法通常针对特定机器人和环境进行设计,难以适应不同物理参数(如质量、惯性)和控制增益的机器人。这限制了策略的通用性和鲁棒性,阻碍了其在现实世界中的广泛应用。现有方法在仿真到现实的迁移过程中,由于仿真环境与真实环境的差异,性能会显著下降。
核心思路:该论文的核心思路是通过在训练过程中对机器人物理参数和关节PD增益进行随机采样,使强化学习策略能够学习到对这些变化的鲁棒性。通过暴露策略于各种不同的配置,使其能够更好地泛化到未知的机器人和环境。此外,使用标称先验和参考模型来偏置采样,可以引导策略学习更合理的行为。
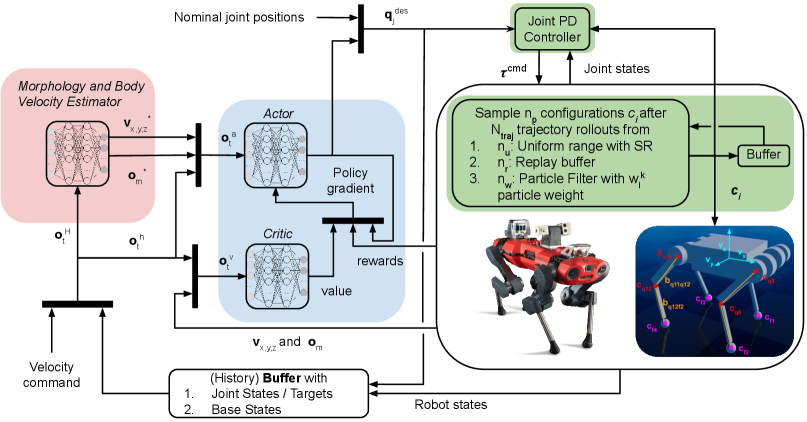
技术框架:该研究使用强化学习框架训练四足机器人的运动策略。整体流程包括:1) 定义机器人和环境的仿真模型;2) 设计奖励函数,鼓励机器人完成特定任务(如前进、转弯);3) 使用强化学习算法(如PPO)训练策略;4) 在训练过程中,对机器人物理参数和关节PD增益进行随机采样;5) 使用标称先验和参考模型来偏置采样;6) 在仿真环境中评估策略的性能;7) 将训练好的策略零样本部署到真实机器人上。
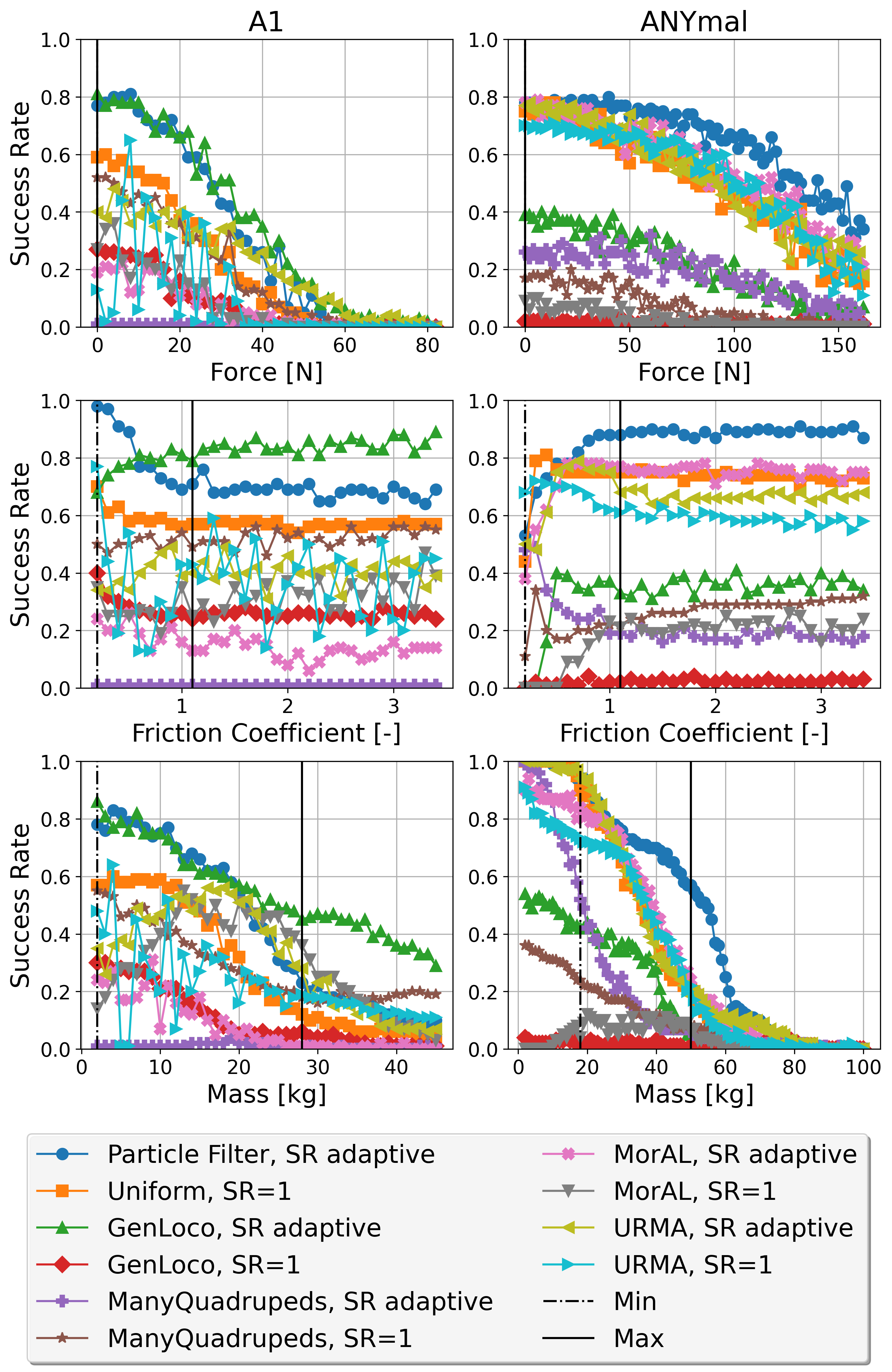
关键创新:该论文的关键创新在于提出了有效的关节增益采样策略,包括线性/多项式映射、基于性能的自适应滤波和均匀随机采样。通过对比实验,证明了显著的关节控制器增益随机化对于鲁棒地弥合仿真到现实的差距至关重要。此外,使用标称先验和参考模型来偏置采样,进一步提高了策略的鲁棒性。
关键设计:论文比较了三种关节增益采样策略:1) 线性/多项式映射:使用质量到增益的函数映射来确定增益的范围;2) 基于性能的自适应滤波:根据策略在训练过程中的性能动态调整增益的采样范围;3) 均匀随机采样:在预定义的范围内随机采样增益。此外,使用标称先验来偏置采样,鼓励策略学习接近标称配置的行为。参考模型用于提供运动轨迹的指导,帮助策略更快地收敛。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的方法在仿真中对多种四足机器人有效,并且成功地将训练好的策略零样本部署到ANYmal机器人上。与基线方法相比,该方法能够显著提高策略的鲁棒性和泛化能力。结果强调了关节控制器增益随机化对于弥合仿真到现实差距的重要性。
🎯 应用场景
该研究成果可应用于各种四足机器人的运动控制,尤其是在需要适应不同机器人和环境的场景中。例如,在搜救、巡检、物流等领域,四足机器人需要在复杂地形和未知环境中稳定行走。该方法可以提高机器人的自主性和适应性,降低人工干预的需求,具有重要的实际应用价值。
📄 摘要(原文)
This work focuses on sampling strategies of configuration variations for generating robust universal locomotion policies for quadrupedal robots. We investigate the effects of sampling physical robot parameters and joint proportional-derivative gains to enable training a single reinforcement learning policy that generalizes to multiple parameter configurations. Three fundamental joint gain sampling strategies are compared: parameter sampling with (1) linear and polynomial function mappings of mass-to-gains, (2) performance-based adaptive filtering, and (3) uniform random sampling. We improve the robustness of the policy by biasing the configurations using nominal priors and reference models. All training was conducted on RaiSim, tested in simulation on a range of diverse quadrupeds, and zero-shot deployed onto hardware using the ANYmal quadruped robot. Compared to multiple baseline implementations, our results demonstrate the need for significant joint controller gains randomization for robust closing of the sim-to-real gap.