Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications
作者: Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Posner, Yuke Zhu
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-10-08
备注: Accepted to IEEE Access, website: https://vla-survey.github.io
DOI: 10.1109/ACCESS.2025.3609980
💡 一句话要点
VLA模型综述:面向真实机器人应用,整合软硬件,提供实践指导
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人 深度学习 多模态学习 强化学习
📋 核心要点
- 现有机器人学习方法难以在不同任务和环境中泛化,限制了其在真实世界的应用。
- VLA模型通过统一视觉、语言和动作数据,学习通用策略,提升泛化能力。
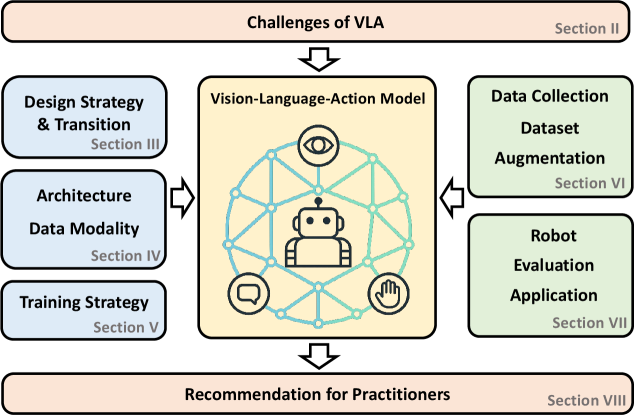
- 该综述全面回顾VLA模型,涵盖软硬件组件、架构演变、学习范式和应用资源。
📝 摘要(中文)
视觉-语言-动作(VLA)模型近年来受到广泛关注,旨在利用大型语言模型(LLM)和视觉-语言模型(VLM)在机器人领域的进展。VLA模型通过大规模统一视觉、语言和动作数据,学习在不同任务、对象、形态和环境中泛化的策略。这种泛化能力有望使机器人能够以最少或无需额外任务特定数据来解决新的下游任务,从而促进更灵活和可扩展的真实世界部署。与以往侧重于动作表示或高层模型架构的综述不同,本文提供了一个全面的、全栈的综述,整合了VLA系统的软件和硬件组件。特别地,本文系统地回顾了VLA,涵盖了它们的策略和架构演变、架构和构建块、模态特定处理技术和学习范式。此外,为了支持VLA在真实机器人应用中的部署,我们还回顾了常用的机器人平台、数据收集策略、公开数据集、数据增强方法和评估基准。通过这份全面的综述,本文旨在为机器人社区在将VLA应用于真实机器人系统时提供实践指导。所有参考文献按训练方法、评估方法、模态和数据集分类,可在我们的项目网站上找到。
🔬 方法详解
问题定义:现有机器人学习方法通常针对特定任务和环境进行优化,缺乏泛化能力,难以适应真实世界复杂多变的场景。此外,传统方法往往将视觉、语言和动作数据割裂开来,未能充分利用多模态信息。
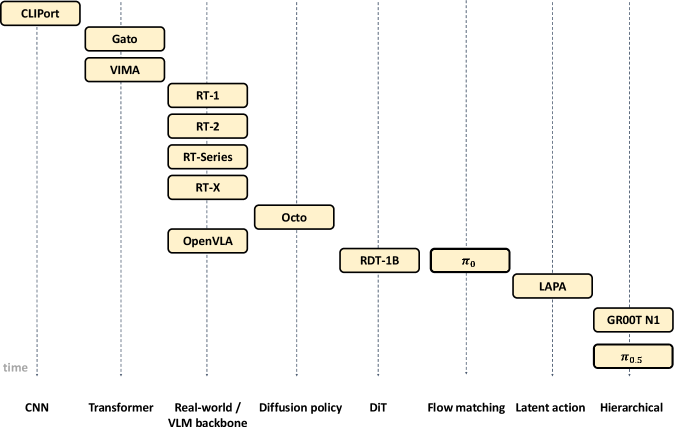
核心思路:VLA模型的核心思路是将视觉、语言和动作数据统一到一个模型中进行学习,从而使机器人能够理解自然语言指令,感知周围环境,并执行相应的动作。通过大规模数据训练,VLA模型能够学习到通用的策略,从而在新的任务和环境中实现泛化。
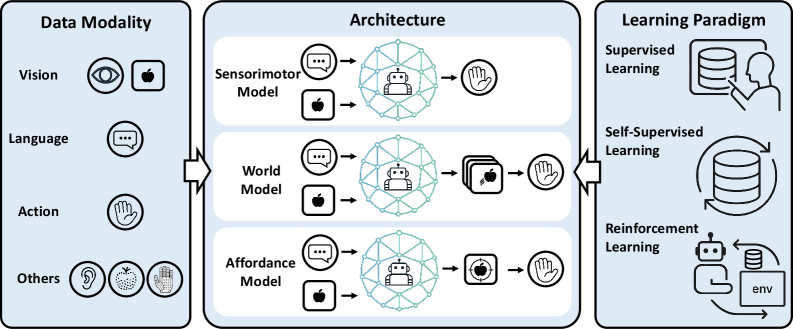
技术框架:VLA模型通常包含以下几个主要模块:1) 视觉编码器,用于提取图像或视频中的视觉特征;2) 语言编码器,用于提取自然语言指令中的语义信息;3) 动作解码器,用于生成机器人的动作序列。这些模块可以通过不同的架构进行组合,例如Transformer、RNN等。此外,VLA模型还需要一个训练框架,用于优化模型的参数。
关键创新:VLA模型最重要的技术创新点在于其能够将视觉、语言和动作数据统一到一个模型中进行学习。这种统一的学习方式使得模型能够更好地理解多模态信息之间的关系,从而提高机器人的泛化能力。与传统方法相比,VLA模型无需针对每个任务进行单独训练,大大降低了开发成本。
关键设计:VLA模型的关键设计包括:1) 模态特定的编码器设计,例如使用卷积神经网络提取视觉特征,使用Transformer提取语言特征;2) 多模态融合策略,例如使用注意力机制将视觉和语言特征进行融合;3) 动作表示方法,例如使用离散动作或连续动作表示机器人的动作;4) 损失函数设计,例如使用交叉熵损失或均方误差损失优化模型参数。
🖼️ 关键图片
📊 实验亮点
该综述全面回顾了VLA模型的研究进展,并对常用的机器人平台、数据收集策略、公开数据集、数据增强方法和评估基准进行了总结。该综述还提供了一个项目网站,其中包含了所有参考文献的分类,方便研究人员查找相关资料。该综述为机器人社区在将VLA应用于真实机器人系统时提供了实践指导。
🎯 应用场景
VLA模型具有广泛的应用前景,例如家庭服务机器人、工业自动化机器人、医疗辅助机器人等。它们可以帮助机器人在复杂环境中执行各种任务,例如物体识别、导航、操作等。VLA模型的实际价值在于提高机器人的智能化水平,降低开发成本,并促进机器人在更多领域的应用。未来,VLA模型有望成为机器人领域的核心技术之一。
📄 摘要(原文)
Amid growing efforts to leverage advances in large language models (LLMs) and vision-language models (VLMs) for robotics, Vision-Language-Action (VLA) models have recently gained significant attention. By unifying vision, language, and action data at scale, which have traditionally been studied separately, VLA models aim to learn policies that generalise across diverse tasks, objects, embodiments, and environments. This generalisation capability is expected to enable robots to solve novel downstream tasks with minimal or no additional task-specific data, facilitating more flexible and scalable real-world deployment. Unlike previous surveys that focus narrowly on action representations or high-level model architectures, this work offers a comprehensive, full-stack review, integrating both software and hardware components of VLA systems. In particular, this paper provides a systematic review of VLAs, covering their strategy and architectural transition, architectures and building blocks, modality-specific processing techniques, and learning paradigms. In addition, to support the deployment of VLAs in real-world robotic applications, we also review commonly used robot platforms, data collection strategies, publicly available datasets, data augmentation methods, and evaluation benchmarks. Throughout this comprehensive survey, this paper aims to offer practical guidance for the robotics community in applying VLAs to real-world robotic systems. All references categorized by training approach, evaluation method, modality, and dataset are available in the table on our project website: https://vla-survey.github.io .