Bring the Apple, Not the Sofa: Impact of Irrelevant Context in Embodied AI Commands on VLA Models
作者: Daria Pugacheva, Andrey Moskalenko, Denis Shepelev, Andrey Kuznetsov, Vlad Shakhuro, Elena Tutubalina
分类: cs.RO
发布日期: 2025-10-08
💡 一句话要点
提出LLM过滤框架以提升VLA模型在噪声指令下的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言行动 具身人工智能 自然语言处理 鲁棒性 指令噪声 LLM过滤 人机交互
📋 核心要点
- 现有VLA模型在真实场景中对自然语言变异的鲁棒性不足,尤其是在指令噪声影响下表现不佳。
- 论文提出了一种基于LLM的过滤框架,旨在从噪声输入中提取核心指令,从而提升模型的鲁棒性。
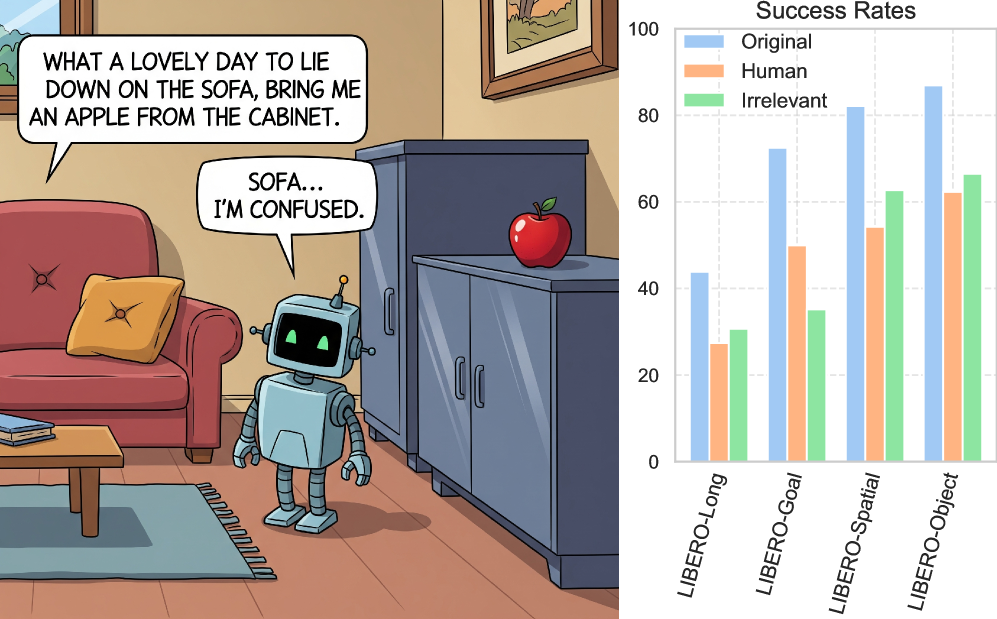
- 实验结果表明,模型在噪声条件下的性能可恢复至98.5%,显著提升了对无关上下文和人类释义的适应能力。
📝 摘要(中文)
视觉语言行动(VLA)模型在具身人工智能中广泛应用,能够解读和执行语言指令。然而,它们在真实场景中对自然语言变异的鲁棒性尚未得到充分研究。本研究系统性地评估了最先进的VLA模型在语言扰动下的表现,特别是人类生成的释义和无关上下文的影响。研究发现,随着上下文长度的增加,模型性能持续下降。随机上下文的相对鲁棒性较高,性能下降在10%以内,而语义和词汇相似的上下文则导致约50%的质量下降。为此,提出了一种基于LLM的过滤框架,从噪声输入中提取核心指令,使模型在噪声条件下恢复高达98.5%的原始性能。
🔬 方法详解
问题定义:本研究旨在解决VLA模型在面对自然语言指令噪声时的鲁棒性问题。现有方法在处理人类生成的释义和无关上下文时,性能显著下降,尤其是当上下文长度增加时。
核心思路:论文提出的核心思路是利用LLM技术构建一个过滤框架,从噪声输入中提取出核心指令,以减少无关上下文对模型性能的影响。这样的设计旨在提高模型在复杂语言环境中的适应能力。
技术框架:整体架构包括输入噪声指令、LLM过滤模块和VLA模型执行模块。首先,输入的指令经过LLM过滤,提取出核心命令,然后将这些命令传递给VLA模型进行执行。
关键创新:最重要的技术创新在于提出了一种有效的LLM过滤机制,能够显著提升模型在噪声条件下的表现。这一方法与传统的直接输入处理方式有本质区别,强调了上下文的影响。
关键设计:在设计中,LLM过滤模块的参数设置经过精细调整,以确保提取的核心指令尽可能保留原意。同时,损失函数的选择也考虑了上下文对模型输出的影响,以优化模型的整体性能。
🖼️ 关键图片


📊 实验亮点
实验结果显示,随着上下文长度的增加,模型性能持续下降,而随机上下文的性能下降仅为10%。相比之下,语义和词汇相似的上下文导致约50%的性能下降。通过引入LLM过滤框架,模型在噪声条件下的性能恢复率高达98.5%。
🎯 应用场景
该研究的潜在应用领域包括服务机器人、智能家居和人机交互等场景。在这些领域,机器人需要理解并执行复杂的自然语言指令,提升其在真实环境中的适应能力和执行效率,具有重要的实际价值和未来影响。
📄 摘要(原文)
Vision Language Action (VLA) models are widely used in Embodied AI, enabling robots to interpret and execute language instructions. However, their robustness to natural language variability in real-world scenarios has not been thoroughly investigated. In this work, we present a novel systematic study of the robustness of state-of-the-art VLA models under linguistic perturbations. Specifically, we evaluate model performance under two types of instruction noise: (1) human-generated paraphrasing and (2) the addition of irrelevant context. We further categorize irrelevant contexts into two groups according to their length and their semantic and lexical proximity to robot commands. In this study, we observe consistent performance degradation as context size expands. We also demonstrate that the model can exhibit relative robustness to random context, with a performance drop within 10%, while semantically and lexically similar context of the same length can trigger a quality decline of around 50%. Human paraphrases of instructions lead to a drop of nearly 20%. To mitigate this, we propose an LLM-based filtering framework that extracts core commands from noisy inputs. Incorporating our filtering step allows models to recover up to 98.5% of their original performance under noisy conditions.