Diffusing Trajectory Optimization Problems for Recovery During Multi-Finger Manipulation
作者: Abhinav Kumar, Fan Yang, Sergio Aguilera Marinovic, Soshi Iba, Rana Soltani Zarrin, Dmitry Berenson
分类: cs.RO
发布日期: 2025-10-08
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于扩散模型的轨迹优化方法,用于多指灵巧操作中的恢复行为
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多指灵巧操作 轨迹优化 扩散模型 恢复行为 接触交互
📋 核心要点
- 多指操作易受扰动影响,现有方法难以有效恢复,尤其是在需要复杂接触交互的场景。
- 利用扩散模型学习任务状态分布,检测异常状态并生成恢复轨迹优化问题的参数。
- 实验表明,该方法在螺丝刀拧紧任务中恢复成功率显著提升,避免了灾难性失败。
📝 摘要(中文)
多指手逐渐成为执行精细操作任务(包括工具使用)的强大平台。然而,环境扰动或执行错误会阻碍任务性能,因此需要恢复行为以使正常任务执行能够恢复。本文利用扩散模型的最新进展,构建了一个框架,该框架能够自主识别何时需要恢复,并优化富含接触的轨迹以进行恢复。我们使用在任务上训练的扩散模型来估计状态何时不利于任务执行,将其定义为一种异常检测问题。然后,我们使用扩散采样将这些状态投影到分布内,并使用轨迹优化来规划富含接触的恢复轨迹。我们还提出了一种新颖的基于扩散的方法,该方法提炼了这一过程,以有效地扩散恢复轨迹优化问题的完整参数化,包括约束、目标状态和初始化,从而节省了在线执行期间的时间。我们将我们的方法与强化学习基线和其他不明确规划接触交互的方法进行了比较,包括在硬件螺丝刀拧紧任务中,我们表明使用我们的方法进行恢复可将任务性能提高 96%,并且我们的方法是唯一一种在不导致灾难性任务失败的情况下尝试恢复的评估方法。视频可在 https://dtourrecovery.github.io/ 找到。
🔬 方法详解
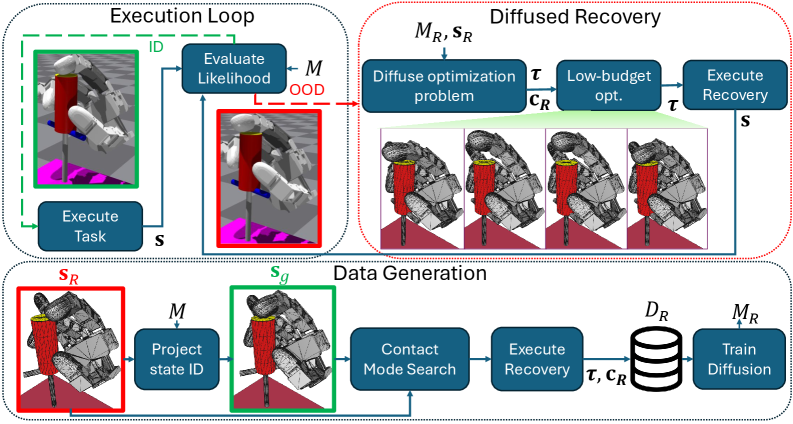
问题定义:论文旨在解决多指灵巧操作中,由于环境扰动或执行错误导致任务失败后,如何快速有效地进行恢复的问题。现有方法,如强化学习,训练成本高昂,泛化性差;而传统轨迹优化方法难以处理复杂的接触交互,容易导致灾难性失败。
核心思路:论文的核心思路是利用扩散模型学习任务的正常状态分布,将恢复问题转化为一个异常检测和状态修正问题。当检测到当前状态偏离正常分布时,使用扩散模型将状态投影回正常分布,并以此为基础进行轨迹优化,生成恢复轨迹。这种方法能够有效地处理复杂的接触交互,并提高恢复的成功率。
技术框架:整体框架包含以下几个主要模块:1) 扩散模型训练:使用任务数据训练扩散模型,学习任务的正常状态分布。2) 异常检测:使用训练好的扩散模型检测当前状态是否偏离正常分布。3) 状态修正:如果检测到异常状态,使用扩散采样将状态投影回正常分布。4) 轨迹优化:以修正后的状态为起点,使用轨迹优化方法生成恢复轨迹。5) 扩散参数化:使用扩散模型直接生成轨迹优化问题的参数,包括约束、目标状态和初始化。
关键创新:论文的关键创新在于将扩散模型应用于多指灵巧操作的恢复问题,并提出了一种新颖的扩散参数化方法。传统的轨迹优化方法需要手动设计目标函数和约束,而扩散参数化方法可以直接从数据中学习这些参数,从而简化了轨迹优化过程,并提高了恢复的效率。
关键设计:扩散模型采用标准的去噪扩散概率模型(DDPM)结构,损失函数为均方误差。轨迹优化采用序列二次规划(SQP)算法。扩散参数化方法使用一个额外的扩散模型,该模型以当前状态为条件,生成轨迹优化问题的参数。关键参数包括扩散模型的噪声schedule、采样步数和轨迹优化算法的参数。
🖼️ 关键图片


📊 实验亮点
在硬件螺丝刀拧紧任务中,该方法相较于强化学习基线和其他不规划接触交互的方法,任务性能提高了 96%。更重要的是,该方法是唯一一种能够在不导致灾难性任务失败的情况下尝试恢复的方法,表明其具有更强的鲁棒性和可靠性。
🎯 应用场景
该研究成果可应用于各种需要精细操作的机器人任务中,例如医疗手术机器人、工业装配机器人和服务机器人。通过提高机器人的鲁棒性和容错性,使其能够在复杂和不确定的环境中稳定可靠地工作。此外,该方法还可以扩展到其他类型的机器人系统,例如无人机和自动驾驶汽车。
📄 摘要(原文)
Multi-fingered hands are emerging as powerful platforms for performing fine manipulation tasks, including tool use. However, environmental perturbations or execution errors can impede task performance, motivating the use of recovery behaviors that enable normal task execution to resume. In this work, we take advantage of recent advances in diffusion models to construct a framework that autonomously identifies when recovery is necessary and optimizes contact-rich trajectories to recover. We use a diffusion model trained on the task to estimate when states are not conducive to task execution, framed as an out-of-distribution detection problem. We then use diffusion sampling to project these states in-distribution and use trajectory optimization to plan contact-rich recovery trajectories. We also propose a novel diffusion-based approach that distills this process to efficiently diffuse the full parameterization, including constraints, goal state, and initialization, of the recovery trajectory optimization problem, saving time during online execution. We compare our method to a reinforcement learning baseline and other methods that do not explicitly plan contact interactions, including on a hardware screwdriver-turning task where we show that recovering using our method improves task performance by 96% and that ours is the only method evaluated that can attempt recovery without causing catastrophic task failure. Videos can be found at https://dtourrecovery.github.io/.