Safe Obstacle-Free Guidance of Space Manipulators in Debris Removal Missions via Deep Reinforcement Learning
作者: Vincent Lam, Robin Chhabra
分类: cs.RO
发布日期: 2025-10-08
💡 一句话要点
提出基于TD3的深度强化学习方法,用于空间机械臂安全无碰撞的轨迹规划,助力碎片移除任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 空间机械臂 碎片移除 深度强化学习 TD3算法 轨迹规划
📋 核心要点
- 现有空间机械臂在碎片移除任务中面临轨迹规划挑战,尤其是在避碰和精确跟踪方面。
- 论文提出基于TD3的深度强化学习方法,结合多评论家网络和优先经验回放,实现安全轨迹规划。
- 在Matlab/Simulink环境中,七自由度KUKA LBR iiwa机械臂的仿真结果验证了该框架的有效性。
📝 摘要(中文)
本研究旨在开发一种用于空间机械臂的无模型工作空间轨迹规划器,该规划器使用双延迟深度确定性策略梯度(TD3)智能体,以实现安全可靠的碎片捕获。采用具有奇异性避免和可操作性增强的局部控制策略,以确保稳定执行。机械臂必须同时跟踪非合作目标上的捕获点,避免自碰撞,并防止与目标发生意外接触。为了应对这些挑战,我们提出了一种基于课程的多评论家网络,其中一个评论家强调精确跟踪,另一个评论家强制执行避碰。还使用优先经验回放缓冲区来加速收敛并提高策略鲁棒性。该框架在Matlab/Simulink中模拟的安装在自由浮动基座上的七自由度KUKA LBR iiwa上进行了评估,展示了用于碎片移除任务的安全且自适应的轨迹生成。
🔬 方法详解
问题定义:空间碎片移除任务中,机械臂需要精确跟踪非合作目标上的捕获点,同时避免自碰撞和与目标的意外接触。传统方法在处理复杂环境和动态变化时,难以保证安全性和鲁棒性,且常常需要精确的动力学模型。
核心思路:利用深度强化学习的无模型特性,通过TD3算法训练智能体,使其能够自主学习安全且高效的轨迹规划策略。通过多评论家网络分别评估跟踪精度和避碰效果,并使用优先经验回放加速学习过程,提高策略的鲁棒性。
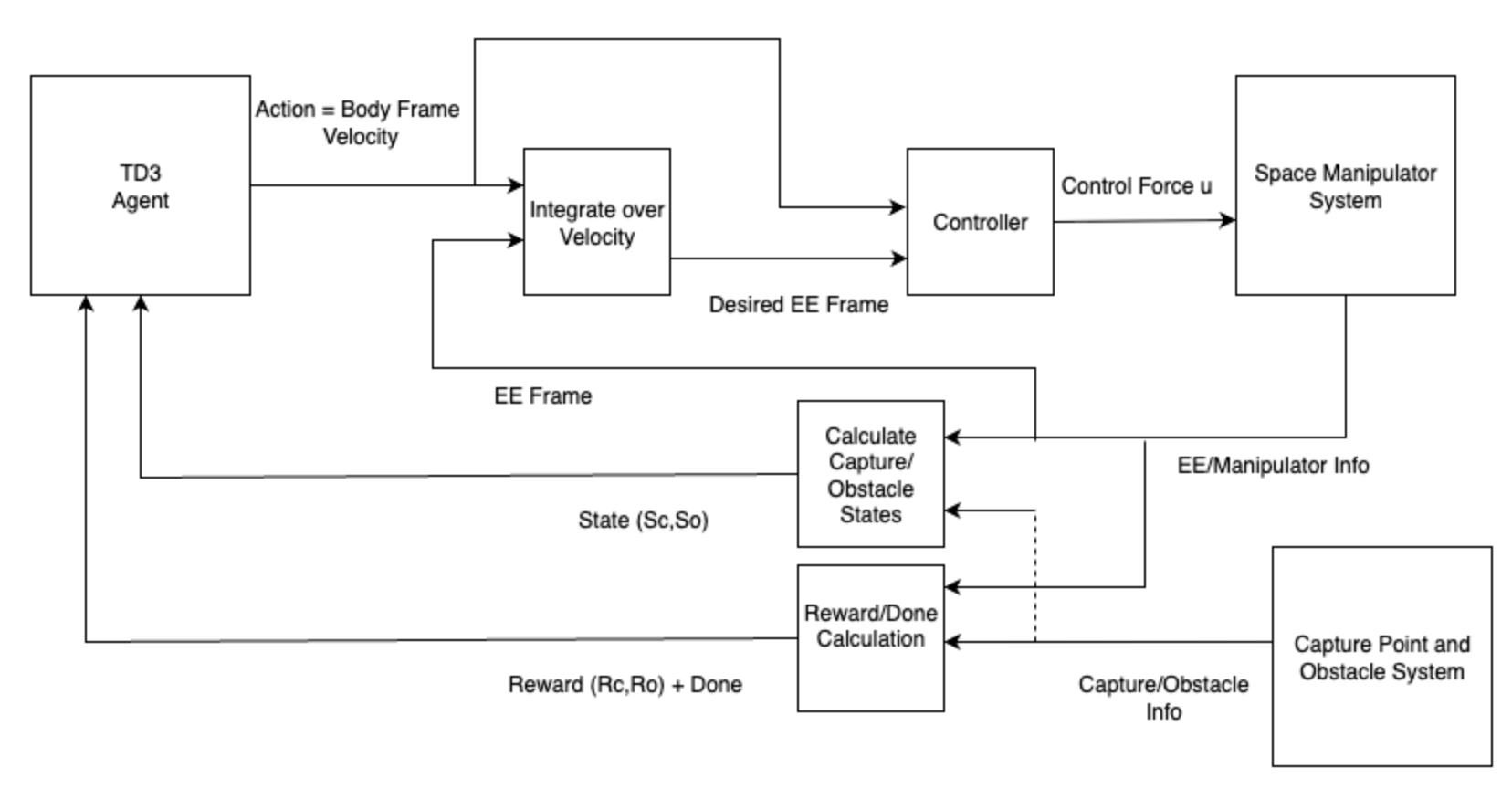
技术框架:该框架包含三个主要部分:环境模拟器(Matlab/Simulink中的KUKA LBR iiwa机械臂模型)、TD3智能体和局部控制器。TD3智能体根据环境状态输出机械臂的关节速度指令,局部控制器执行这些指令,同时进行奇异性避免和可操作性增强,确保机械臂运动的平稳性。环境模拟器提供状态反馈和奖励信号,用于训练TD3智能体。
关键创新:该方法的核心创新在于使用多评论家网络,分别关注跟踪精度和避碰。这种设计允许智能体在学习过程中同时优化这两个目标,避免了单一奖励函数可能导致的局部最优解。此外,优先经验回放机制能够更有效地利用有价值的经验,加速学习过程。
关键设计:TD3智能体的网络结构包括Actor网络和两个Critic网络。Actor网络输出确定性的动作(关节速度指令),Critic网络评估Actor网络输出的动作的价值。奖励函数的设计至关重要,需要平衡跟踪精度、避碰和运动平滑性。优先经验回放缓冲区根据经验的重要性进行采样,更有利于学习到关键的策略。
🖼️ 关键图片


📊 实验亮点
该研究在Matlab/Simulink环境中对七自由度KUKA LBR iiwa机械臂进行了仿真实验,验证了所提出框架的有效性。实验结果表明,该方法能够生成安全且自适应的轨迹,成功避免了自碰撞和与目标的意外接触,同时实现了对目标捕获点的精确跟踪。通过优先经验回放,加速了学习过程,提高了策略的鲁棒性。
🎯 应用场景
该研究成果可应用于空间碎片移除、卫星在轨服务、空间站维护等领域。通过深度强化学习,机械臂能够自主适应复杂多变的空间环境,安全可靠地完成目标任务,降低任务风险和成本,提高空间任务的效率和智能化水平。未来可进一步扩展到其他类型的空间机器人和任务场景。
📄 摘要(原文)
The objective of this study is to develop a model-free workspace trajectory planner for space manipulators using a Twin Delayed Deep Deterministic Policy Gradient (TD3) agent to enable safe and reliable debris capture. A local control strategy with singularity avoidance and manipulability enhancement is employed to ensure stable execution. The manipulator must simultaneously track a capture point on a non-cooperative target, avoid self-collisions, and prevent unintended contact with the target. To address these challenges, we propose a curriculum-based multi-critic network where one critic emphasizes accurate tracking and the other enforces collision avoidance. A prioritized experience replay buffer is also used to accelerate convergence and improve policy robustness. The framework is evaluated on a simulated seven-degree-of-freedom KUKA LBR iiwa mounted on a free-floating base in Matlab/Simulink, demonstrating safe and adaptive trajectory generation for debris removal missions.