Avi: Action from Volumetric Inference
作者: Harris Song, Long Le
分类: cs.RO
发布日期: 2025-10-07
备注: NeurIPS 2025 Workshop on Embodied World Models for Decision Making. URL: https://avi-3drobot.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Avi:通过体素推理实现机器人动作生成,解决传统方法泛化性不足的问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人动作生成 3D视觉 语言引导 空间推理 多模态学习
📋 核心要点
- 现有VLA模型依赖2D视觉输入和端到端策略学习,泛化性和鲁棒性不足。
- Avi利用3D点云和语言引导的场景理解,通过几何变换计算动作,无需训练动作token。
- 实验结果表明,该方法对遮挡、相机姿态变化和视点变化具有鲁棒性,展现了3D视觉-语言推理的潜力。
📝 摘要(中文)
本文提出了一种新颖的3D视觉-语言-动作(VLA)架构Avi,它将机器人动作生成重新定义为3D感知和空间推理问题,而不是低层次的策略学习。与主要基于2D视觉输入并在特定任务的动作策略上进行端到端训练的现有VLA模型不同,Avi利用3D点云和语言引导的场景理解,通过经典几何变换来计算动作。最值得注意的是,Avi不依赖于先前动作token的训练,而是构建于3D多模态大型语言模型(MLLM)之上,以生成下一个点云并通过经典变换显式计算动作。这种方法实现了对遮挡、相机姿态变化和视点变化具有鲁棒性的通用行为。通过将机器人决策过程视为3D表示上的结构化推理任务,Avi弥合了高级语言指令和低级驱动之间的差距,而无需不透明的策略学习。初步结果突出了3D视觉-语言推理作为可扩展、鲁棒机器人系统基础的潜力。
🔬 方法详解
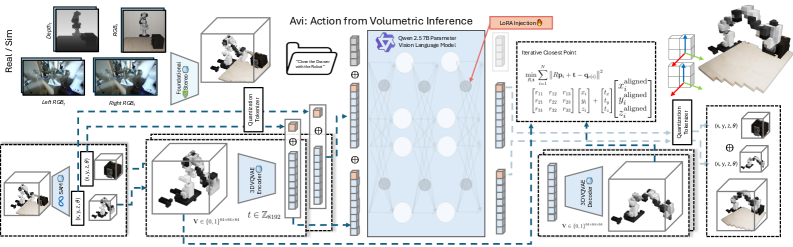
问题定义:现有VLA模型主要依赖2D视觉信息,通过端到端的方式学习特定任务的动作策略。这种方法泛化能力较弱,难以应对遮挡、视角变化等复杂场景,并且策略学习过程通常是不透明的,难以解释和调试。因此,需要一种更具通用性和鲁棒性的机器人动作生成方法。
核心思路:Avi的核心思路是将机器人动作生成问题转化为3D感知和空间推理问题。通过利用3D点云作为输入,结合语言引导的场景理解,模型能够更好地理解环境的几何结构和语义信息。然后,通过经典的几何变换,可以直接计算出所需的动作,避免了复杂的策略学习过程。
技术框架:Avi的整体架构包含以下几个主要模块:1) 3D场景感知模块:负责从3D点云中提取场景特征,并结合语言指令进行场景理解。2) 3D多模态大型语言模型(MLLM):用于生成下一个目标点云,该点云代表了执行动作后的预期场景状态。3) 动作计算模块:通过比较当前点云和目标点云,利用经典几何变换计算出所需的机器人动作。
关键创新:Avi最重要的创新在于它将机器人动作生成问题转化为一个基于3D表示的结构化推理任务。与传统的策略学习方法不同,Avi不依赖于先前动作token的训练,而是直接通过几何变换计算动作。这种方法使得模型具有更好的泛化能力和鲁棒性,并且更容易解释和调试。
关键设计:Avi的关键设计包括:1) 使用3D点云作为输入,能够更全面地捕捉场景的几何信息。2) 利用3D MLLM生成目标点云,实现对未来场景状态的预测。3) 通过经典几何变换计算动作,避免了复杂的策略学习过程。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文的初步结果表明,Avi在应对遮挡、相机姿态变化和视点变化方面表现出良好的鲁棒性。由于缺乏具体的性能数据和对比基线,无法进行更详细的量化分析。但该方法为基于3D视觉-语言推理的机器人系统提供了一个有潜力的方向。
🎯 应用场景
Avi的潜在应用领域包括:智能仓储、自动驾驶、家庭服务机器人等。该研究的实际价值在于提供了一种更通用、更鲁棒的机器人动作生成方法,可以降低机器人开发的成本和难度。未来,该方法有望应用于更复杂的机器人任务,例如多机器人协同、人机协作等。
📄 摘要(原文)
We propose Avi, a novel 3D Vision-Language-Action (VLA) architecture that reframes robotic action generation as a problem of 3D perception and spatial reasoning, rather than low-level policy learning. While existing VLA models primarily operate on 2D visual inputs and are trained end-to-end on task-specific action policies, Avi leverages 3D point clouds and language-grounded scene understanding to compute actions through classical geometric transformations. Most notably, Avi does not train on previous action tokens, rather, we build upon a 3D Multi-modal Large Language Model (MLLM) to generate the next point cloud and explicitly calculate the actions through classical transformations. This approach enables generalizable behaviors that are robust to occlusions, camera pose variations, and changes in viewpoint. By treating the robotic decision-making process as a structured reasoning task over 3D representations, Avi bridges the gap between high-level language instructions and low-level actuation without requiring opaque policy learning. Our preliminary results highlight the potential of 3D vision-language reasoning as a foundation for scalable, robust robotic systems. Check it out at https://avi-3drobot.github.io/.