Cross-Embodiment Dexterous Hand Articulation Generation via Morphology-Aware Learning
作者: Heng Zhang, Kevin Yuchen Ma, Mike Zheng Shou, Weisi Lin, Yan Wu
分类: cs.RO, cs.AI
发布日期: 2025-10-07
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于形态感知学习的跨体态灵巧手关节生成方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting)
关键词: 灵巧抓取 跨体态 形态感知 关节生成 机器人技术 机器学习 运动学损失
📋 核心要点
- 现有的灵巧抓取方法在高维关节控制和优化效率上存在显著挑战,限制了其在不同手型上的应用。
- 本文提出了一种基于形态嵌入和特征抓取的端到端框架,能够有效生成跨体态的抓取策略。
- 在仿真实验中,模型在未见物体上实现了91.9%的抓取成功率,并在少量适应下达到85.6%的成功率,显示出良好的泛化能力。
📝 摘要(中文)
灵巧抓取多指手仍然面临高维关节和优化管道成本的挑战。现有的端到端方法需要在特定手的大规模数据集上训练,限制了其跨不同体态的泛化能力。本文提出了一种基于特征抓取的端到端框架,用于跨体态抓取生成。通过手的形态描述,我们推导出形态嵌入和特征抓取集。在此基础上,结合物体点云和腕部姿态,一个幅度预测器在低维空间中回归关节系数,并解码为完整的关节动作。关节学习通过运动学感知关节损失(KAL)进行监督,强调与指尖相关的运动并注入形态特定结构。在对三种灵巧手的未见物体进行仿真时,我们的模型实现了91.9%的平均抓取成功率,推理时间少于0.4秒。通过对未见手的少量适应,仿真中在未见物体上取得85.6%的成功率,实际实验中该少量适应手的成功率为87%。
🔬 方法详解
问题定义:本文旨在解决灵巧手抓取中的高维关节控制和优化管道成本问题。现有方法依赖于特定手的大规模数据集,导致泛化能力不足。
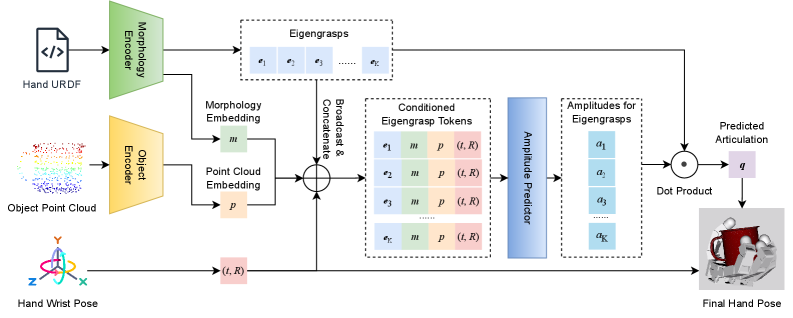
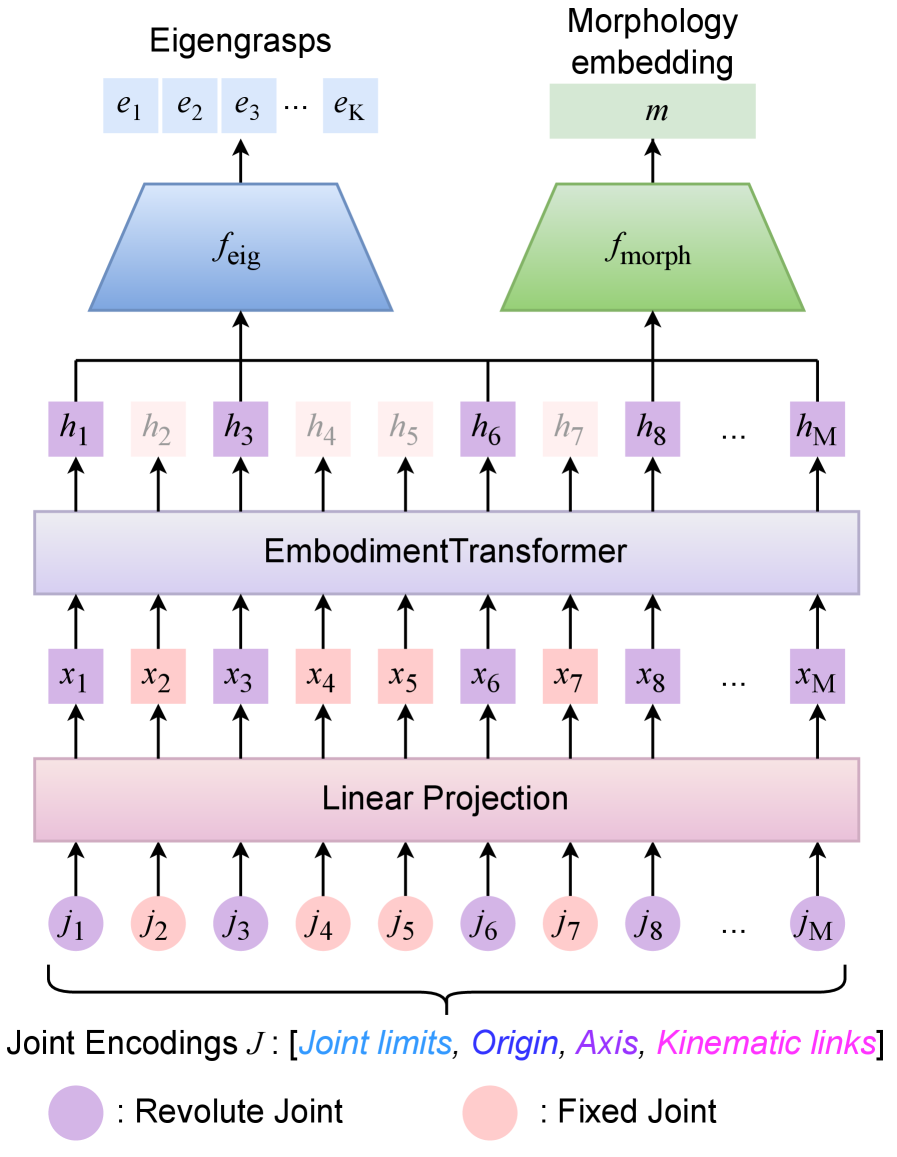
核心思路:提出基于形态感知的特征抓取框架,通过手的形态描述生成形态嵌入和特征抓取集,从而实现跨体态的抓取生成。
技术框架:整体架构包括形态嵌入生成、特征抓取集构建、幅度预测器和关节解码模块。输入包括物体点云和腕部姿态,输出为完整的关节动作。
关键创新:引入运动学感知关节损失(KAL),强调与指尖相关的运动,并注入形态特定的结构,显著提升了抓取成功率和泛化能力。
关键设计:模型通过低维空间回归关节系数,使用特定损失函数来优化关节学习,确保抓取动作的有效性和准确性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,模型在未见物体上的平均抓取成功率达到91.9%,推理时间低于0.4秒。通过少量适应,模型在未见手上的成功率为85.6%,实际实验中达到87%的成功率,展现出优越的泛化能力和适应性。
🎯 应用场景
该研究可广泛应用于机器人抓取、智能家居、医疗辅助等领域,提升机器手在复杂环境中的操作能力。未来,随着技术的进步,该方法有望在更多实际场景中实现灵活应用,推动人机协作的发展。
📄 摘要(原文)
Dexterous grasping with multi-fingered hands remains challenging due to high-dimensional articulations and the cost of optimization-based pipelines. Existing end-to-end methods require training on large-scale datasets for specific hands, limiting their ability to generalize across different embodiments. We propose an eigengrasp-based, end-to-end framework for cross-embodiment grasp generation. From a hand's morphology description, we derive a morphology embedding and an eigengrasp set. Conditioned on these, together with the object point cloud and wrist pose, an amplitude predictor regresses articulation coefficients in a low-dimensional space, which are decoded into full joint articulations. Articulation learning is supervised with a Kinematic-Aware Articulation Loss (KAL) that emphasizes fingertip-relevant motions and injects morphology-specific structure. In simulation on unseen objects across three dexterous hands, our model attains a 91.9% average grasp success rate with less than 0.4 seconds inference per grasp. With few-shot adaptation to an unseen hand, it achieves 85.6% success on unseen objects in simulation, and real-world experiments on this few-shot generalized hand achieve an 87% success rate. The code and additional materials will be made available upon publication on our project website https://connor-zh.github.io/cross_embodiment_dexterous_grasping.