VCoT-Grasp: Grasp Foundation Models with Visual Chain-of-Thought Reasoning for Language-driven Grasp Generation
作者: Haoran Zhang, Shuanghao Bai, Wanqi Zhou, Yuedi Zhang, Qi Zhang, Pengxiang Ding, Cheng Chi, Donglin Wang, Badong Chen
分类: cs.RO, cs.AI
发布日期: 2025-10-07
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出VCoT-Grasp,利用视觉链式推理增强语言驱动的抓取生成能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人抓取 视觉链式推理 语言驱动 抓取生成 基础模型
📋 核心要点
- 现有语言驱动的抓取方法缺乏足够的推理和泛化能力,且过度依赖对象语义,限制了在复杂环境下的应用。
- VCoT-Grasp通过引入视觉链式推理,增强模型对视觉信息的理解,实现更强的推理和泛化能力。
- 实验表明,VCoT-Grasp在抓取成功率上显著提升,并能有效推广到未见过的物体和复杂环境中。
📝 摘要(中文)
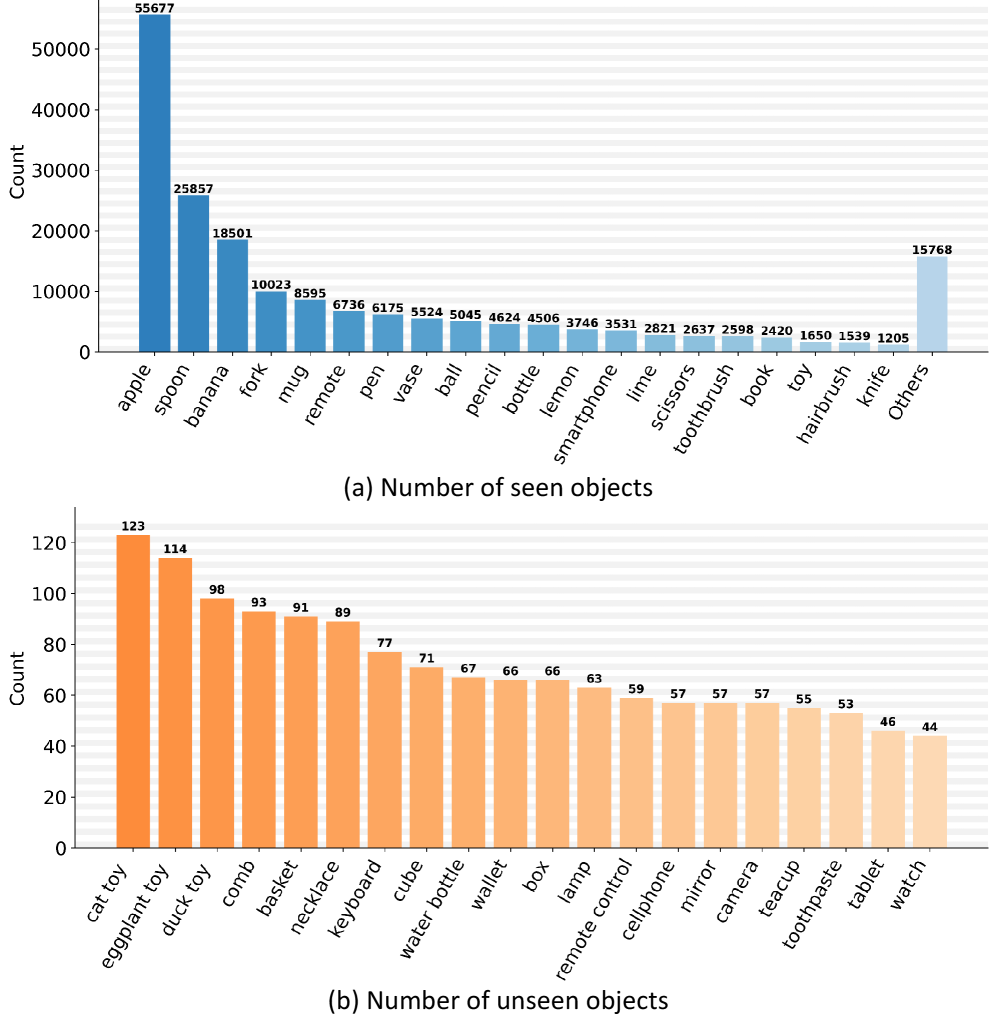
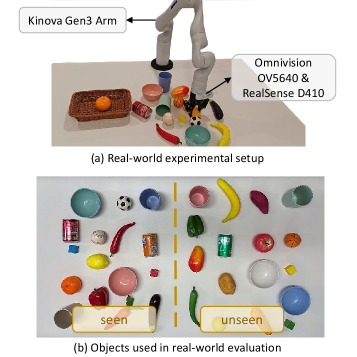
机器人抓取是机器人操作中最基本的任务之一,抓取检测/生成一直是广泛研究的主题。最近,语言驱动的抓取生成因其具有实际的交互能力而成为一个有前景的方向。然而,大多数现有方法要么缺乏足够的推理和泛化能力,要么依赖于复杂的模块化流程。此外,当前的抓取基础模型倾向于过度强调对话和对象语义,导致性能下降并限制为单对象抓取。为了在杂乱的环境中保持强大的推理能力和泛化能力,我们提出了VCoT-Grasp,一个端到端的抓取基础模型,它结合了视觉链式推理来增强抓取生成的视觉理解。VCoT-Grasp采用多轮处理范式,动态地关注视觉输入,同时提供可解释的推理轨迹。对于训练,我们改进并引入了一个大规模数据集VCoT-GraspSet,包含16.7万张合成图像和超过136万个抓取,以及400多张真实图像和超过1200个抓取,并标注了中间边界框。在VCoT-GraspSet和真实机器人上的大量实验表明,我们的方法显著提高了抓取成功率,并有效地推广到未见过的物体、背景和干扰物。
🔬 方法详解
问题定义:论文旨在解决语言驱动的机器人抓取任务中,现有方法在复杂场景下推理能力不足、泛化性差的问题。现有方法往往过度依赖于对话和物体语义,忽略了场景中其他视觉信息的推理,导致抓取性能下降,尤其是在存在干扰物或未见过的物体时。
核心思路:论文的核心思路是引入视觉链式推理(Visual Chain-of-Thought, VCoT),模仿人类逐步推理的过程,让模型在抓取决策前,先对场景进行多轮分析,提取关键视觉信息,从而提升抓取的准确性和鲁棒性。通过这种方式,模型可以更好地理解场景,并做出更合理的抓取决策。
技术框架:VCoT-Grasp是一个端到端的抓取基础模型,其整体架构包含以下几个主要模块:1) 视觉输入模块:接收场景的图像信息;2) 视觉链式推理模块:通过多轮交互,逐步提取场景中的关键视觉信息,例如目标物体的位置、形状、周围环境等;3) 抓取生成模块:基于视觉链式推理的结果,生成抓取姿态;4) 抓取执行模块:将生成的抓取姿态发送给机器人执行。整个流程是端到端可训练的。
关键创新:论文最关键的创新点在于将视觉链式推理引入到抓取任务中。与以往直接从图像生成抓取姿态的方法不同,VCoT-Grasp通过多轮推理,逐步提取关键视觉信息,从而提升了模型对场景的理解能力和抓取的准确性。此外,论文还构建了一个大规模的抓取数据集VCoT-GraspSet,为模型的训练提供了充足的数据支持。
关键设计:VCoT-Grasp采用多轮处理范式,每一轮推理都基于前一轮的结果和当前的视觉输入。具体来说,模型会根据当前的状态,选择关注图像的特定区域,并提取相应的特征。然后,模型会根据提取的特征,更新其内部状态,并生成下一轮的关注区域。这个过程会持续进行,直到模型对场景有了充分的理解。损失函数的设计也至关重要,需要平衡抓取姿态的准确性和推理过程的合理性。具体的网络结构未知,但可以推测使用了Transformer或类似的注意力机制来实现多轮推理。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VCoT-Grasp在VCoT-GraspSet和真实机器人上的抓取成功率显著优于现有方法。具体来说,VCoT-Grasp在未见过的物体、背景和干扰物上的泛化能力更强,能够有效地应对复杂场景。具体的性能提升数据未知,但摘要中明确指出是“显著提高”。
🎯 应用场景
VCoT-Grasp在机器人操作领域具有广泛的应用前景,例如智能仓储、自动化生产线、家庭服务机器人等。该技术可以使机器人更好地理解复杂环境,并执行更精确的抓取任务,从而提高生产效率和服务质量。未来,该技术还可以应用于医疗、救援等领域,帮助机器人完成更复杂、更危险的任务。
📄 摘要(原文)
Robotic grasping is one of the most fundamental tasks in robotic manipulation, and grasp detection/generation has long been the subject of extensive research. Recently, language-driven grasp generation has emerged as a promising direction due to its practical interaction capabilities. However, most existing approaches either lack sufficient reasoning and generalization capabilities or depend on complex modular pipelines. Moreover, current grasp foundation models tend to overemphasize dialog and object semantics, resulting in inferior performance and restriction to single-object grasping. To maintain strong reasoning ability and generalization in cluttered environments, we propose VCoT-Grasp, an end-to-end grasp foundation model that incorporates visual chain-of-thought reasoning to enhance visual understanding for grasp generation. VCoT-Grasp adopts a multi-turn processing paradigm that dynamically focuses on visual inputs while providing interpretable reasoning traces. For training, we refine and introduce a large-scale dataset, VCoT-GraspSet, comprising 167K synthetic images with over 1.36M grasps, as well as 400+ real-world images with more than 1.2K grasps, annotated with intermediate bounding boxes. Extensive experiments on both VCoT-GraspSet and real robot demonstrate that our method significantly improves grasp success rates and generalizes effectively to unseen objects, backgrounds, and distractors. More details can be found at https://zhanghr2001.github.io/VCoT-Grasp.github.io.