DeLTa: Demonstration and Language-Guided Novel Transparent Object Manipulation
作者: Taeyeop Lee, Gyuree Kang, Bowen Wen, Youngho Kim, Seunghyeok Back, In So Kweon, David Hyunchul Shim, Kuk-Jin Yoon
分类: cs.RO, cs.CV
发布日期: 2025-10-07
备注: Project page: https://sites.google.com/view/DeLTa25/
💡 一句话要点
DeLTa:基于单次演示和语言引导的新型透明物体操作框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 透明物体操作 机器人操作 视觉-语言规划 单次演示学习 6D姿态估计
📋 核心要点
- 现有透明物体操作研究主要集中在短时程任务和基本抓取,缺乏对新物体的泛化能力和精确的长时程操作能力。
- DeLTa框架通过单次演示学习,结合深度估计、6D姿态估计和视觉-语言规划,实现对新型透明物体的精确操作。
- 实验结果表明,DeLTa在长时程透明物体操作任务中显著优于现有方法,展示了其优越的性能。
📝 摘要(中文)
本文提出DeLTa,一种新颖的透明物体操作框架,它结合了深度估计、6D姿态估计和视觉-语言规划,用于在自然语言指令引导下精确地进行透明物体的长时程操作。该方法的一个关键优势是其单次演示方法,可以将6D轨迹推广到新的透明物体,而无需类别级别的先验知识或额外的训练。此外,本文还提出了一个任务规划器,用于优化VLM生成的计划,以适应单臂、眼在手机器人进行长时程物体操作任务的约束。通过全面的评估,证明了该方法显著优于现有的透明物体操作方法,尤其是在需要精确操作能力的长时程场景中。
🔬 方法详解
问题定义:现有的透明物体操作方法在处理长时程任务和泛化到新型物体时存在局限性。它们通常需要大量的训练数据或类别级别的先验知识,难以适应真实世界中复杂多变的场景。此外,精确的长时程操作能力也是一个挑战,尤其是在单臂机器人平台上。
核心思路:DeLTa的核心思路是利用单次演示学习,将人类的示范轨迹推广到新的透明物体上。通过结合深度估计、6D姿态估计和视觉-语言规划,DeLTa能够理解自然语言指令,并生成相应的机器人操作计划。这种方法避免了对大量训练数据的依赖,提高了泛化能力和操作精度。
技术框架:DeLTa框架主要包含三个模块:深度估计模块、6D姿态估计模块和视觉-语言规划模块。首先,深度估计模块用于获取场景的深度信息,克服透明物体的视觉挑战。然后,6D姿态估计模块用于估计透明物体的精确姿态。最后,视觉-语言规划模块根据自然语言指令生成机器人操作计划,并通过任务规划器进行优化,以适应单臂机器人的约束。
关键创新:DeLTa的关键创新在于其单次演示学习方法和视觉-语言规划的结合。单次演示学习使得DeLTa能够快速适应新的透明物体,而无需额外的训练。视觉-语言规划则使得DeLTa能够理解自然语言指令,并生成相应的机器人操作计划。此外,任务规划器的引入进一步提高了操作的精度和鲁棒性。
关键设计:DeLTa的关键设计包括:(1) 使用先进的深度估计网络来处理透明物体的深度信息;(2) 采用基于点云的6D姿态估计方法,提高姿态估计的精度;(3) 利用预训练的视觉-语言模型(VLM)生成初步的操作计划,并通过任务规划器进行优化。任务规划器考虑了单臂机器人的运动学约束和环境的几何约束,确保操作计划的可行性和安全性。
🖼️ 关键图片
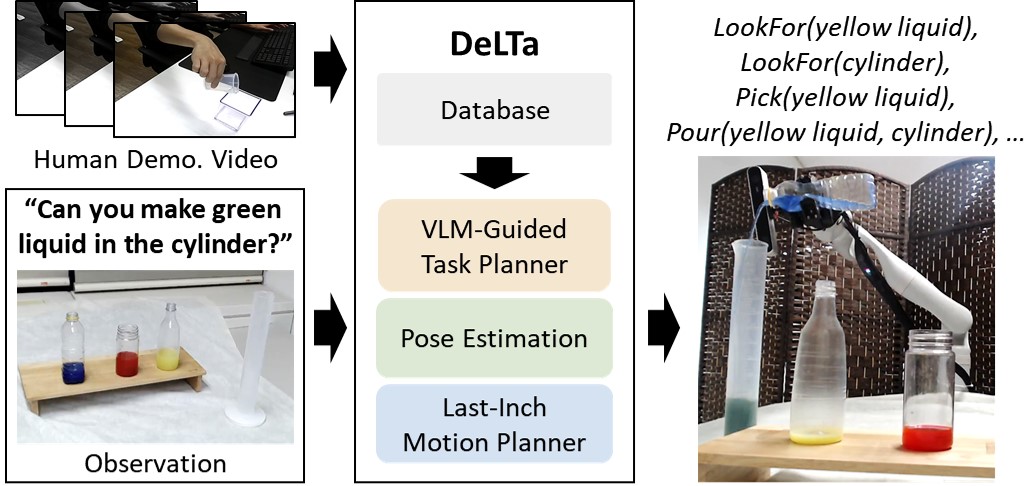
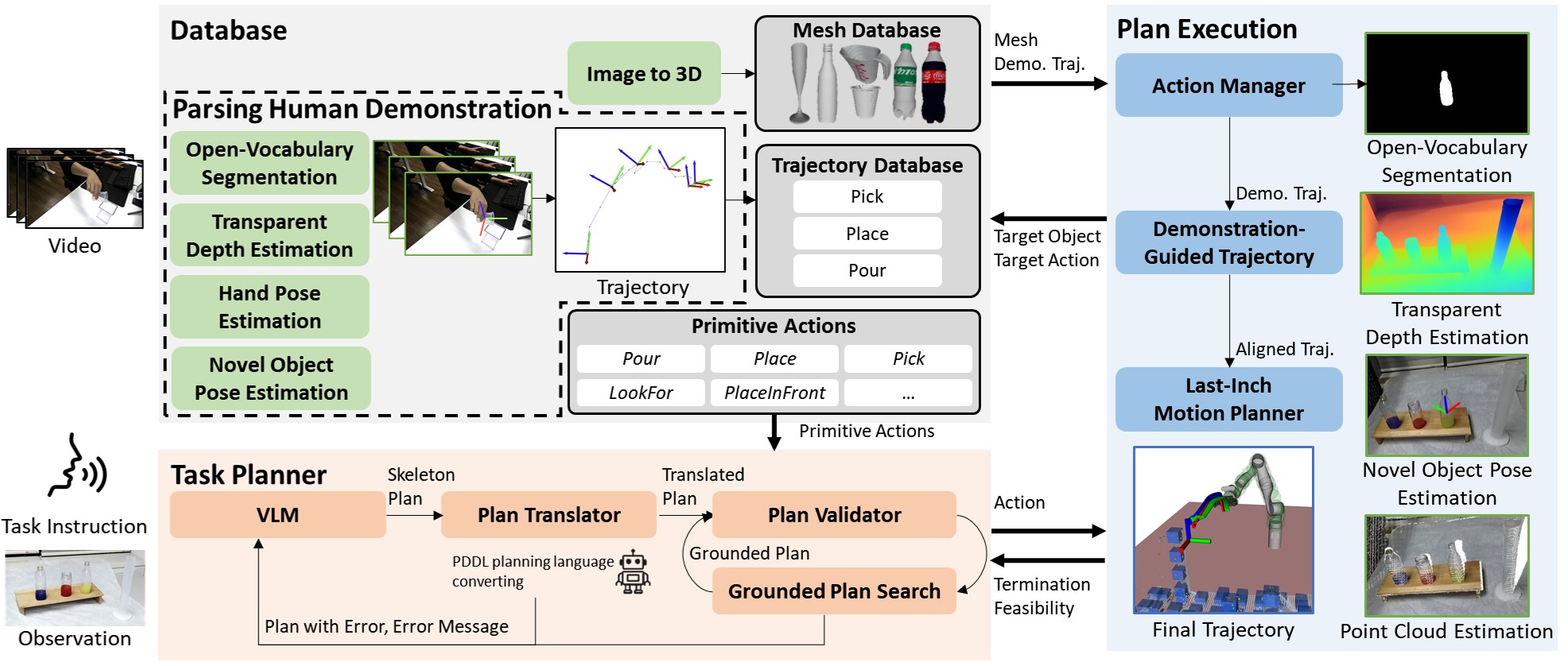

📊 实验亮点
实验结果表明,DeLTa在长时程透明物体操作任务中显著优于现有的方法。具体来说,DeLTa在操作成功率方面取得了显著的提升,尤其是在需要精确操作的复杂任务中。此外,DeLTa的泛化能力也得到了验证,能够成功地操作各种新型的透明物体。
🎯 应用场景
DeLTa在自动化装配、医疗手术、家庭服务等领域具有广泛的应用前景。例如,在自动化装配中,DeLTa可以用于精确地组装透明的电子元件。在医疗手术中,DeLTa可以辅助医生进行精细的手术操作。在家庭服务中,DeLTa可以帮助人们完成各种复杂的家务任务,提高生活质量。
📄 摘要(原文)
Despite the prevalence of transparent object interactions in human everyday life, transparent robotic manipulation research remains limited to short-horizon tasks and basic grasping capabilities.Although some methods have partially addressed these issues, most of them have limitations in generalizability to novel objects and are insufficient for precise long-horizon robot manipulation. To address this limitation, we propose DeLTa (Demonstration and Language-Guided Novel Transparent Object Manipulation), a novel framework that integrates depth estimation, 6D pose estimation, and vision-language planning for precise long-horizon manipulation of transparent objects guided by natural task instructions. A key advantage of our method is its single-demonstration approach, which generalizes 6D trajectories to novel transparent objects without requiring category-level priors or additional training. Additionally, we present a task planner that refines the VLM-generated plan to account for the constraints of a single-arm, eye-in-hand robot for long-horizon object manipulation tasks. Through comprehensive evaluation, we demonstrate that our method significantly outperforms existing transparent object manipulation approaches, particularly in long-horizon scenarios requiring precise manipulation capabilities. Project page: https://sites.google.com/view/DeLTa25/