DREAMer-VXS: A Latent World Model for Sample-Efficient AGV Exploration in Stochastic, Unobserved Environments
作者: Agniprabha Chakraborty
分类: cs.RO
发布日期: 2025-10-06
💡 一句话要点
DREAMer-VXS:用于随机、未观测环境中AGV高效探索的潜变量世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶车辆 强化学习 世界模型 自主探索 深度学习
📋 核心要点
- 传统无模型强化学习算法在样本效率和脆弱性方面存在不足,阻碍了其在现实机器人应用中的推广。
- DREAMer-VXS通过学习一个世界模型,使AGV能够在想象的潜在轨迹中进行规划,从而解决样本效率问题。
- 实验表明,DREAMer-VXS比现有方法学习速度更快,泛化能力更强,并且在探索效率和鲁棒性方面有显著提升。
📝 摘要(中文)
本文提出DREAMer-VXS,一个基于模型的自动驾驶车辆(AGV)探索框架,它学习从想象的潜在轨迹中进行规划。该方法的核心是从部分和高维LiDAR观测中学习一个全面的世界模型。该世界模型由卷积变分自编码器(VAE)和循环状态空间模型(RSSM)组成,前者学习环境结构的紧凑表示,后者模拟复杂的时序动态。通过利用该学习模型作为高速模拟器,智能体几乎完全在想象中训练其导航策略。这种方法将策略学习与真实世界交互分离,与最先进的无模型SAC基线相比,达到专家级性能所需的交互减少了90%。智能体的行为由actor-critic策略指导,该策略使用复合奖励函数进行优化,该函数平衡了任务目标和内在的好奇心奖励,从而促进了对未知空间的系统探索。通过广泛的模拟实验证明,DREAMer-VXS不仅学习速度快几个数量级,而且开发出更通用和鲁棒的策略,在未见环境中探索效率提高了45%,并且对动态障碍具有更强的适应能力。
🔬 方法详解
问题定义:现有基于强化学习的AGV探索方法通常需要大量的真实环境交互,样本效率低下,难以适应未知的随机环境。此外,高维LiDAR数据处理也是一个挑战。这些痛点限制了AGV在复杂和动态环境中的实际应用。
核心思路:DREAMer-VXS的核心在于学习一个能够准确模拟环境动态的潜变量世界模型。通过在学习到的世界模型中进行策略训练,可以显著减少对真实环境的依赖,提高样本效率。同时,利用内在好奇心奖励鼓励智能体探索未知区域,提升探索效率和策略的泛化能力。
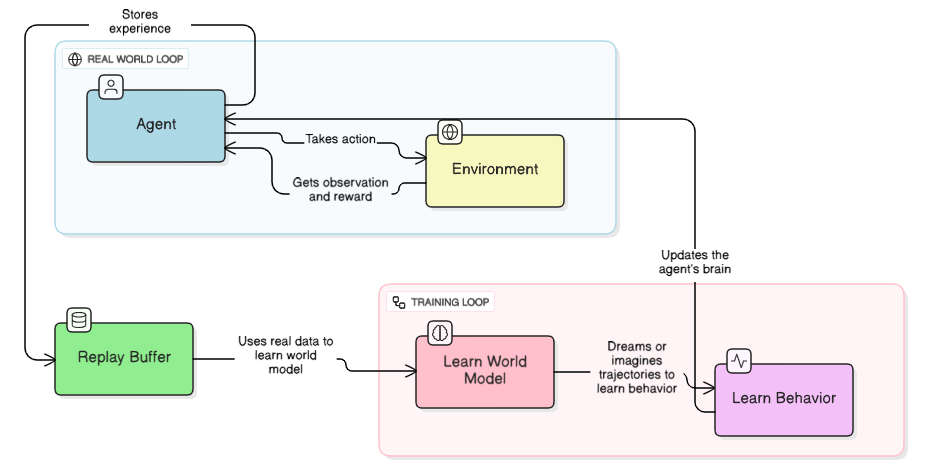
技术框架:DREAMer-VXS框架包含以下主要模块:1) 卷积变分自编码器(VAE):用于从高维LiDAR数据中学习环境的紧凑潜在表示。2) 循环状态空间模型(RSSM):用于建模环境的动态变化,预测未来状态。3) Actor-Critic策略:在学习到的世界模型中训练,用于指导AGV的导航行为。4) 复合奖励函数:结合任务目标和内在好奇心奖励,引导智能体进行高效探索。
关键创新:DREAMer-VXS的关键创新在于将世界模型学习与策略学习解耦。通过学习一个准确的世界模型,智能体可以在想象的环境中进行策略训练,从而显著减少对真实环境的依赖。此外,结合内在好奇心奖励,可以鼓励智能体探索未知区域,提高探索效率和策略的泛化能力。与传统的端到端强化学习方法相比,DREAMer-VXS具有更高的样本效率和更好的泛化能力。
关键设计:VAE使用卷积神经网络提取LiDAR数据的空间特征,并将其编码为低维潜在向量。RSSM使用循环神经网络建模潜在状态的时序动态。Actor-Critic策略使用深度神经网络实现,并通过策略梯度方法进行优化。复合奖励函数包括任务相关的奖励(例如,到达目标点)和内在好奇心奖励(例如,访问新的状态)。内在好奇心奖励的设计鼓励智能体探索未知的状态空间,避免陷入局部最优。
🖼️ 关键图片
📊 实验亮点
DREAMer-VXS在模拟环境中取得了显著的性能提升。与最先进的无模型SAC基线相比,DREAMer-VXS达到专家级性能所需的交互减少了90%。在未见环境中,DREAMer-VXS的探索效率提高了45%,并且对动态障碍具有更强的适应能力。这些结果表明,DREAMer-VXS是一种高效、通用和鲁棒的AGV探索方法。
🎯 应用场景
DREAMer-VXS具有广泛的应用前景,例如:仓库自动化、物流配送、矿区勘探、灾后救援等。该方法可以显著降低AGV在未知和动态环境中部署的成本和风险,提高其自主性和适应性。未来,可以将DREAMer-VXS扩展到更复杂的机器人系统,例如无人机和水下机器人,以解决更多实际问题。
📄 摘要(原文)
The paradigm of learning-based robotics holds immense promise, yet its translation to real-world applications is critically hindered by the sample inefficiency and brittleness of conventional model-free reinforcement learning algorithms. In this work, we address these challenges by introducing DREAMer-VXS, a model-based framework for Autonomous Ground Vehicle (AGV) exploration that learns to plan from imagined latent trajectories. Our approach centers on learning a comprehensive world model from partial and high-dimensional LiDAR observations. This world model is composed of a Convolutional Variational Autoencoder (VAE), which learns a compact representation of the environment's structure, and a Recurrent State-Space Model (RSSM), which models complex temporal dynamics. By leveraging this learned model as a high-speed simulator, the agent can train its navigation policy almost entirely in imagination. This methodology decouples policy learning from real-world interaction, culminating in a 90% reduction in required environmental interactions to achieve expert-level performance when compared to state-of-the-art model-free SAC baselines. The agent's behavior is guided by an actor-critic policy optimized with a composite reward function that balances task objectives with an intrinsic curiosity bonus, promoting systematic exploration of unknown spaces. We demonstrate through extensive simulated experiments that DREAMer-VXS not only learns orders of magnitude faster but also develops more generalizable and robust policies, achieving a 45% increase in exploration efficiency in unseen environments and superior resilience to dynamic obstacles.