VER: Vision Expert Transformer for Robot Learning via Foundation Distillation and Dynamic Routing
作者: Yixiao Wang, Mingxiao Huo, Zhixuan Liang, Yushi Du, Lingfeng Sun, Haotian Lin, Jinghuan Shang, Chensheng Peng, Mohit Bansal, Mingyu Ding, Masayoshi Tomizuka
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-06
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出VER,通过专家蒸馏和动态路由实现机器人学习的视觉知识迁移。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 视觉基础模型 知识蒸馏 动态路由 Transformer 参数高效微调 专家系统
📋 核心要点
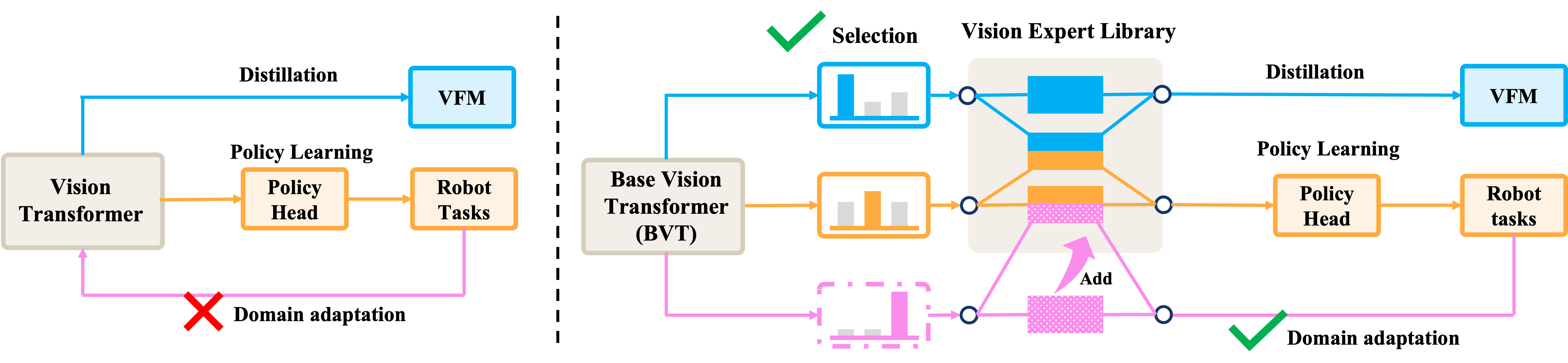
- 现有视觉基础模型在特定领域表现出色,但缺乏跨任务的通用性,直接蒸馏多个模型又缺乏灵活性。
- VER通过预训练的视觉专家库和轻量级路由网络,动态选择任务相关的专家,实现高效的知识迁移。
- 实验表明,VER在多个机器人任务上取得了SOTA性能,并能有效关注任务关键区域。
📝 摘要(中文)
本文提出了一种用于机器人学习的视觉专家Transformer(VER)。VER通过知识蒸馏将多个视觉基础模型(VFMs)提炼成一个视觉专家库。在微调阶段,仅需训练一个轻量级的路由网络(参数量小于0.4%),即可动态地从预训练的专家库中选择与任务相关的专家,用于下游机器人任务。此外,本文还引入了带有课程Top-K退火的Patchwise专家路由,以提高动态专家选择的灵活性和精确性。VER还支持参数高效的微调,以实现专家利用率的可扩展性和自适应的机器人领域知识集成。在17个不同的机器人任务和多个策略头上的实验表明,VER取得了最先进的性能。VER减少了任务无关区域(例如背景)中的大范数异常值,并集中于任务关键区域。
🔬 方法详解
问题定义:现有方法在将视觉基础模型应用于机器人学习时,存在两个主要问题。一是单个视觉基础模型通常只擅长特定领域,难以泛化到各种机器人任务。二是直接将多个视觉基础模型蒸馏成统一的表示,缺乏灵活性,难以适应新的机器人领域知识,并且需要昂贵的完全重新训练。
核心思路:VER的核心思路是构建一个视觉专家库,其中每个专家都擅长不同的视觉特征。然后,通过一个轻量级的路由网络,根据当前任务的需求,动态地选择合适的专家组合。这种方法既能利用多个视觉基础模型的优势,又能保持模型的灵活性和可扩展性。
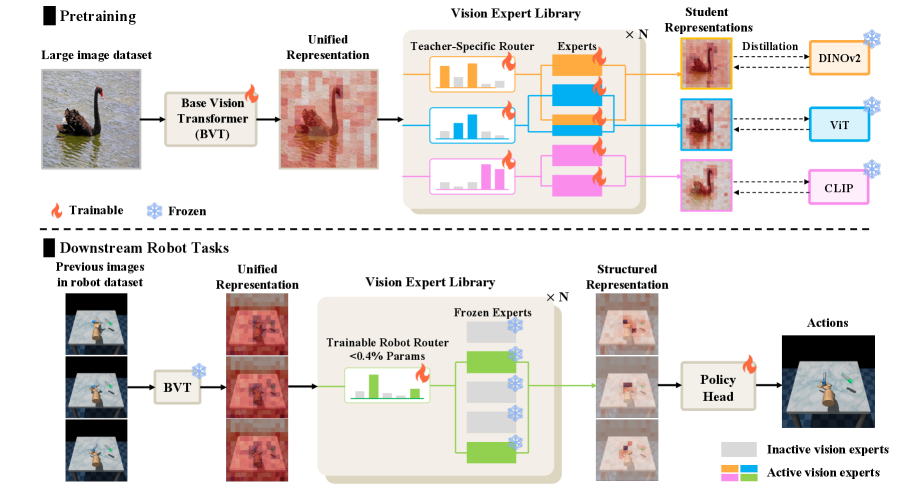
技术框架:VER的整体框架包括三个主要阶段:1) 视觉专家库构建:使用知识蒸馏技术,将多个预训练的视觉基础模型(VFMs)的知识迁移到一个共享的视觉专家库中。每个专家负责提取不同的视觉特征。2) 动态专家路由:设计一个轻量级的路由网络,根据输入的图像和任务信息,动态地选择合适的专家组合。路由网络的输出是每个专家的权重,用于加权融合各个专家的特征。3) 参数高效微调:为了适应新的机器人领域知识,采用参数高效的微调方法,只更新路由网络的参数,而保持视觉专家库的参数不变。
关键创新:VER的关键创新在于动态专家路由机制。与传统的静态特征选择方法相比,动态专家路由能够根据任务的需求,自适应地选择合适的专家组合,从而提高模型的泛化能力和适应性。此外,Patchwise Expert Routing with Curriculum Top-K Annealing进一步提升了专家选择的精度和灵活性。
关键设计:Patchwise Expert Routing将图像划分为多个patch,并为每个patch选择不同的专家组合。Curriculum Top-K Annealing是一种课程学习策略,在训练初期,允许路由网络选择更多的专家,以探索不同的特征组合;随着训练的进行,逐渐减少选择的专家数量,以提高模型的精度。路由网络通常是一个小型Transformer网络,输入是图像patch的嵌入表示,输出是每个专家的权重。损失函数包括路由损失和策略损失,路由损失用于鼓励路由网络选择合适的专家,策略损失用于优化机器人策略。
🖼️ 关键图片

📊 实验亮点
VER在17个不同的机器人任务上取得了state-of-the-art的性能。例如,在某些任务上,VER的性能比之前的最佳方法提高了10%以上。实验还表明,VER能够有效地减少任务无关区域(如背景)中的噪声,并集中关注任务关键区域。此外,VER的参数量非常小,只有不到0.4%的参数需要微调,这使得VER具有很高的效率和可扩展性。
🎯 应用场景
VER具有广泛的应用前景,可应用于各种机器人学习任务,如物体抓取、导航、操作等。通过利用预训练的视觉知识,VER可以显著提高机器人的学习效率和泛化能力。此外,VER还可以应用于其他视觉任务,如图像分类、目标检测等,通过动态选择不同的视觉专家,提高模型的性能。
📄 摘要(原文)
Pretrained vision foundation models (VFMs) advance robotic learning via rich visual representations, yet individual VFMs typically excel only in specific domains, limiting generality across tasks. Distilling multiple VFMs into a unified representation for policy can mitigate this limitation but often yields inflexible task-specific feature selection and requires costly full re-training to incorporate robot-domain knowledge. We propose VER, a Vision Expert transformer for Robot learning. During pretraining, VER distills multiple VFMs into a vision expert library. It then fine-tunes only a lightweight routing network (fewer than 0.4% of parameters) to dynamically select task-relevant experts from the pretrained library for downstream robot tasks. We further introduce Patchwise Expert Routing with Curriculum Top-K Annealing to improve both flexibility and precision of dynamic expert selection. Moreover, VER supports parameter-efficient finetuning for scalable expert utilization and adaptive robot-domain knowledge integration. Across 17 diverse robotic tasks and multiple policy heads, VER achieves state-of-the-art performance. We find that VER reduces large-norm outliers in task-irrelevant regions (e.g., background) and concentrates on task-critical regions. Visualizations and codes can be found in https://yixiaowang7.github.io/ver_page/.