StaMo: Unsupervised Learning of Generalizable Robot Motion from Compact State Representation
作者: Mingyu Liu, Jiuhe Shu, Hui Chen, Zeju Li, Canyu Zhao, Jiange Yang, Shenyuan Gao, Hao Chen, Chunhua Shen
分类: cs.RO, cs.CV
发布日期: 2025-10-06
💡 一句话要点
StaMo:利用紧凑状态表示无监督学习通用机器人运动
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人运动学习 无监督学习 状态表示 扩散Transformer 潜在动作
📋 核心要点
- 现有机器人学习方法难以在状态表示的表达性和紧凑性之间取得平衡,限制了世界建模和决策效率。
- StaMo利用轻量级编码器和预训练的扩散Transformer解码器,学习高度压缩的双token状态表示,无需显式监督。
- 实验表明,StaMo在LIBERO和真实世界任务中显著提升性能,并能有效扩展到多种数据源,包括真实机器人数据。
📝 摘要(中文)
具身智能的一个根本挑战是开发富有表现力且紧凑的状态表示,以实现高效的世界建模和决策。然而,现有方法通常无法达到这种平衡,导致表示要么过于冗余,要么缺乏任务关键信息。我们提出了一种无监督方法,该方法使用轻量级编码器和预训练的扩散Transformer (DiT)解码器学习高度压缩的双token状态表示,利用其强大的生成先验。我们的表示是高效的、可解释的,并且可以无缝集成到现有的基于VLA的模型中,在LIBERO上提高了14.3%的性能,在真实世界任务成功率上提高了30%,且推理开销最小。更重要的是,我们发现这些token之间的差异,通过潜在插值获得,自然地充当了一种高效的潜在动作,可以进一步解码为可执行的机器人动作。这种涌现的能力表明,我们的表示在没有显式监督的情况下捕获了结构化动力学。我们将我们的方法命名为StaMo,因为它能够从静态图像编码的紧凑状态表示中学习通用的机器人运动,挑战了对复杂架构和视频数据学习潜在动作的普遍依赖。由此产生的潜在动作也增强了策略协同训练,优于先前的方法10.4%,并提高了可解释性。此外,我们的方法可以有效地扩展到不同的数据源,包括真实世界的机器人数据、模拟和人类自我中心视频。
🔬 方法详解
问题定义:现有机器人学习方法在状态表示方面存在不足,要么过于冗余,包含大量不相关信息,导致计算效率低下;要么缺乏任务关键信息,影响决策的准确性。因此,如何在保证信息完整性的前提下,学习到紧凑且富有表现力的状态表示,是当前机器人学习领域面临的一个重要挑战。
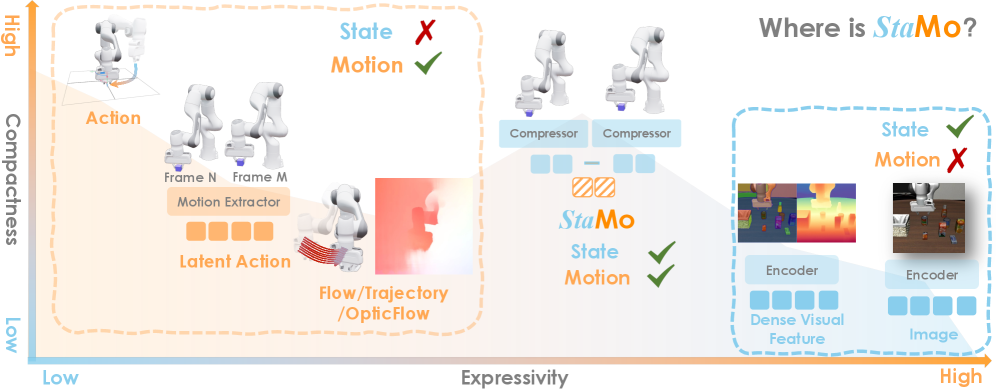
核心思路:StaMo的核心思路是利用预训练的扩散Transformer (DiT) 的强大生成能力,结合轻量级的编码器,将状态信息压缩成两个token。这两个token能够捕捉状态的关键信息,并且它们之间的差异可以作为潜在动作,从而实现无监督学习机器人运动。这种方法避免了对复杂架构和视频数据的依赖,提高了学习效率和泛化能力。
技术框架:StaMo的整体框架包括以下几个主要模块:1) 轻量级编码器:将原始状态(例如,图像)编码成两个token;2) 预训练的扩散Transformer (DiT) 解码器:利用DiT的生成能力,将两个token解码成可执行的机器人动作;3) 潜在动作提取模块:通过计算两个token之间的差异,得到潜在动作表示。整个流程是无监督的,不需要显式的动作标签。
关键创新:StaMo最重要的技术创新点在于,它能够从静态图像中学习到通用的机器人运动,而无需依赖复杂的架构和视频数据。此外,通过两个token之间的差异,StaMo能够提取出有效的潜在动作,这是一种涌现的能力,表明该方法能够捕捉到结构化的动力学信息。这种方法挑战了当前机器人学习领域对复杂架构和视频数据的普遍依赖。
关键设计:StaMo的关键设计包括:1) 使用轻量级的编码器,以保证计算效率;2) 利用预训练的扩散Transformer (DiT) 解码器,以获得强大的生成能力;3) 通过计算两个token之间的差异,提取潜在动作;4) 采用无监督的学习方式,避免了对动作标签的依赖。具体的损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
StaMo在LIBERO数据集上取得了14.3%的性能提升,在真实世界任务中成功率提高了30%。与现有方法相比,StaMo在策略协同训练中表现更优,提升了10.4%,并提高了可解释性。此外,StaMo能够有效扩展到不同的数据源,包括真实世界的机器人数据、模拟和人类自我中心视频。
🎯 应用场景
StaMo具有广泛的应用前景,可应用于各种机器人任务,例如导航、操作和人机协作。该方法能够提高机器人的自主性和适应性,使其能够更好地适应复杂和动态的环境。此外,StaMo还可以应用于虚拟现实、游戏和动画等领域,以生成更逼真和自然的运动。
📄 摘要(原文)
A fundamental challenge in embodied intelligence is developing expressive and compact state representations for efficient world modeling and decision making. However, existing methods often fail to achieve this balance, yielding representations that are either overly redundant or lacking in task-critical information. We propose an unsupervised approach that learns a highly compressed two-token state representation using a lightweight encoder and a pre-trained Diffusion Transformer (DiT) decoder, capitalizing on its strong generative prior. Our representation is efficient, interpretable, and integrates seamlessly into existing VLA-based models, improving performance by 14.3% on LIBERO and 30% in real-world task success with minimal inference overhead. More importantly, we find that the difference between these tokens, obtained via latent interpolation, naturally serves as a highly effective latent action, which can be further decoded into executable robot actions. This emergent capability reveals that our representation captures structured dynamics without explicit supervision. We name our method StaMo for its ability to learn generalizable robotic Motion from compact State representation, which is encoded from static images, challenging the prevalent dependence to learning latent action on complex architectures and video data. The resulting latent actions also enhance policy co-training, outperforming prior methods by 10.4% with improved interpretability. Moreover, our approach scales effectively across diverse data sources, including real-world robot data, simulation, and human egocentric video.