HyperVLA: Efficient Inference in Vision-Language-Action Models via Hypernetworks
作者: Zheng Xiong, Kang Li, Zilin Wang, Matthew Jackson, Jakob Foerster, Shimon Whiteson
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-06
🔗 代码/项目: GITHUB
💡 一句话要点
HyperVLA:通过超网络实现视觉-语言-动作模型的高效推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 超网络 高效推理 机器人学习 多任务学习
📋 核心要点
- 现有视觉-语言-动作模型(VLA)推理成本高昂,限制了其在实际机器人应用中的部署。
- HyperVLA利用超网络(HN)生成特定任务的轻量级策略,仅激活少量参数,降低推理计算量。
- 实验表明,HyperVLA在保持或提升性能的同时,显著降低了推理成本,参数量减少90倍,速度提升120倍。
📝 摘要(中文)
视觉-语言-动作(VLA)模型建立在具有强大泛化能力的语言和视觉基础模型之上,并在大规模机器人数据上进行训练,最近已成为学习通用机器人策略的一种有前途的方法。然而,现有VLA的一个关键缺点是其极高的推理成本。在本文中,我们提出了HyperVLA来解决这个问题。与在训练和推理过程中激活整个模型的现有单体VLA不同,HyperVLA使用一种新颖的基于超网络(HN)的架构,该架构在推理过程中仅激活一个小的特定于任务的策略,同时仍然保留容纳各种多任务行为所需的高模型容量。成功训练基于HN的VLA并非易事,因此HyperVLA包含几个关键的算法设计特性,以提高其性能,包括正确利用来自现有视觉基础模型的先验知识、HN归一化和动作生成策略。与单体VLA相比,HyperVLA在零样本泛化和少样本自适应方面实现了相似甚至更高的成功率,同时显著降低了推理成本。与最先进的VLA模型OpenVLA相比,HyperVLA在测试时减少了90倍的激活参数数量,并将推理速度提高了120倍。代码已在https://github.com/MasterXiong/HyperVLA上公开。
🔬 方法详解
问题定义:现有视觉-语言-动作模型(VLA)在推理时需要激活整个模型,计算量巨大,难以满足实时性要求高的机器人应用场景。痛点在于模型参数冗余,无法根据任务自适应地调整计算资源分配。
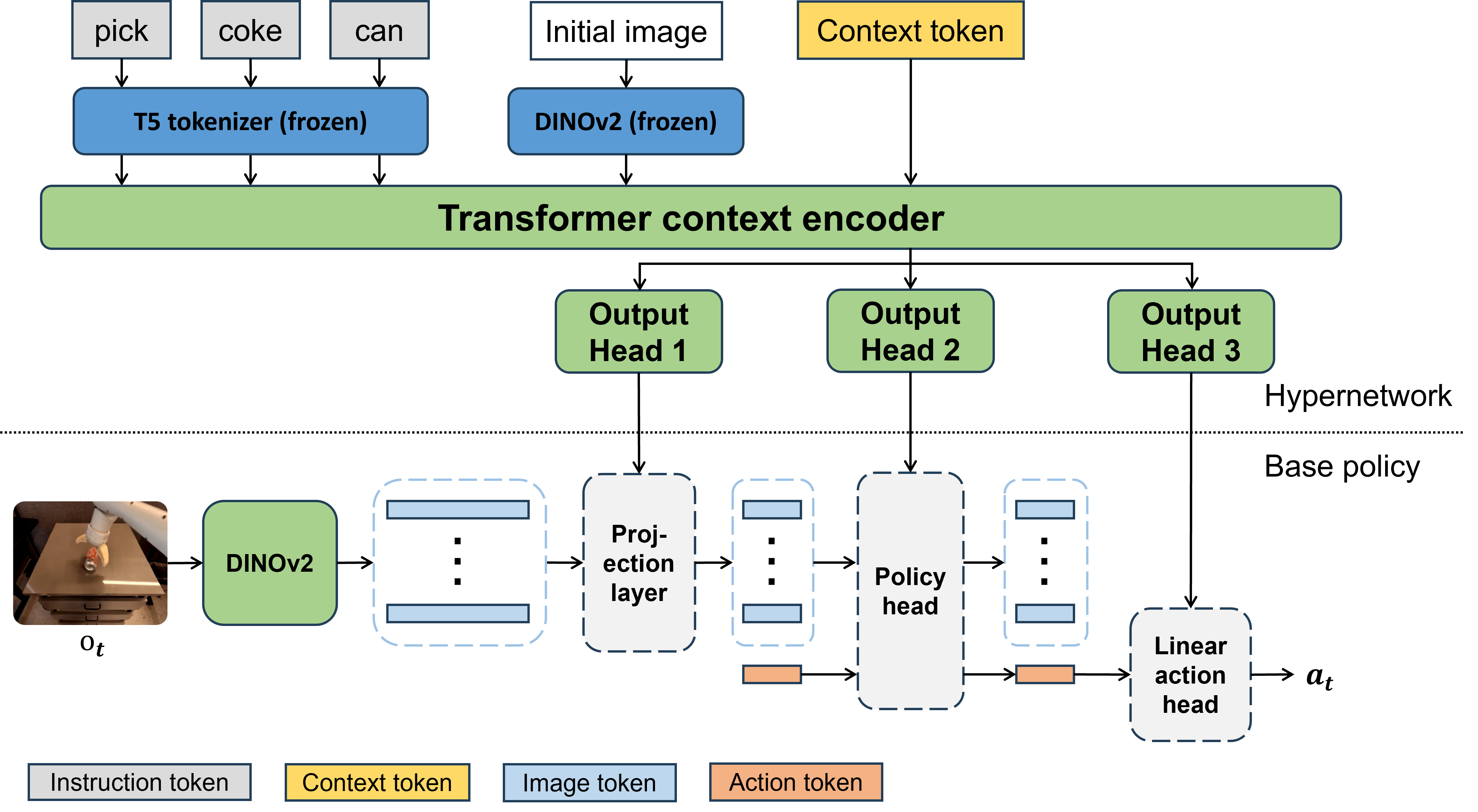
核心思路:HyperVLA的核心思路是利用超网络(Hypernetwork)动态生成特定任务的策略网络参数。超网络接收任务描述作为输入,输出一个小型策略网络的权重,从而避免了激活整个大型VLA模型,显著降低了推理计算量。这样既能保持VLA模型强大的多任务处理能力,又能实现高效的推理。
技术框架:HyperVLA包含以下主要模块:1) 视觉和语言编码器:用于提取视觉和语言特征。2) 超网络:根据视觉和语言特征生成特定任务的策略网络权重。3) 策略网络:接收状态信息,输出动作指令。训练过程包括:1) 使用大规模机器人数据训练VLA模型。2) 训练超网络,使其能够根据任务描述生成合适的策略网络权重。推理过程包括:1) 使用视觉和语言编码器提取任务描述特征。2) 使用超网络生成策略网络权重。3) 使用策略网络根据当前状态输出动作指令。
关键创新:HyperVLA的关键创新在于使用超网络动态生成策略网络权重,从而实现了VLA模型的高效推理。与传统的单体VLA模型相比,HyperVLA在推理时仅激活少量参数,显著降低了计算量。此外,论文还提出了HN归一化和动作生成策略等技术,进一步提高了模型的性能。
关键设计:HyperVLA的关键设计包括:1) 利用预训练的视觉基础模型作为视觉编码器,加速训练过程。2) 使用HN归一化技术,提高超网络的训练稳定性。3) 设计了一种动作生成策略,确保生成的动作指令符合机器人的运动学约束。损失函数包括模仿学习损失和正则化损失,用于训练超网络和策略网络。
🖼️ 关键图片

📊 实验亮点
HyperVLA在多个机器人任务上进行了实验,结果表明,与最先进的VLA模型OpenVLA相比,HyperVLA在测试时减少了90倍的激活参数数量,并将推理速度提高了120倍。同时,HyperVLA在零样本泛化和少样本自适应方面实现了相似甚至更高的成功率,证明了其在降低推理成本的同时,保持了良好的性能。
🎯 应用场景
HyperVLA适用于各种需要快速响应和低计算成本的机器人应用场景,例如家庭服务机器人、工业自动化机器人和无人驾驶车辆。通过降低VLA模型的推理成本,HyperVLA可以使这些机器人能够更高效、更可靠地执行各种复杂任务,并有望推动通用机器人技术的发展。
📄 摘要(原文)
Built upon language and vision foundation models with strong generalization ability and trained on large-scale robotic data, Vision-Language-Action (VLA) models have recently emerged as a promising approach to learning generalist robotic policies. However, a key drawback of existing VLAs is their extremely high inference costs. In this paper, we propose HyperVLA to address this problem. Unlike existing monolithic VLAs that activate the whole model during both training and inference, HyperVLA uses a novel hypernetwork (HN)-based architecture that activates only a small task-specific policy during inference, while still retaining the high model capacity needed to accommodate diverse multi-task behaviors during training. Successfully training an HN-based VLA is nontrivial so HyperVLA contains several key algorithm design features that improve its performance, including properly utilizing the prior knowledge from existing vision foundation models, HN normalization, and an action generation strategy. Compared to monolithic VLAs, HyperVLA achieves a similar or even higher success rate for both zero-shot generalization and few-shot adaptation, while significantly reducing inference costs. Compared to OpenVLA, a state-of-the-art VLA model, HyperVLA reduces the number of activated parameters at test time by $90\times$, and accelerates inference speed by $120\times$. Code is publicly available at https://github.com/MasterXiong/HyperVLA