VBM-NET: Visual Base Pose Learning for Mobile Manipulation using Equivariant TransporterNet and GNNs
作者: Lakshadeep Naik, Adam Fischer, Daniel Duberg, Danica Kragic
分类: cs.RO
发布日期: 2025-10-05
💡 一句话要点
VBM-NET:利用等变TransporterNet和GNN学习移动操作的视觉基座位姿
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 移动操作 基座位姿选择 等变TransporterNet 图神经网络 强化学习 视觉伺服 sim-to-real
📋 核心要点
- 移动操作中,选择最佳移动基座位姿对于成功抓取物体至关重要,传统方法依赖精确的状态信息,如物体位姿和环境模型。
- VBM-NET利用俯视正交投影,结合等变TransporterNet学习候选位姿,并用图神经网络和强化学习选择最优位姿。
- 实验表明,VBM-NET在计算时间上优于经典方法,并成功实现了从模拟到真实环境的迁移。
📝 摘要(中文)
本文研究了直接从场景的俯视正交投影中进行基座位姿规划的问题,这种投影提供了场景的全局概览并保留了空间结构。我们提出了VBM-NET,一种基于学习的方法,用于使用此类俯视正交投影选择基座位姿。我们使用等变TransporterNet来利用空间对称性并有效地学习用于抓取的候选基座位姿。此外,我们使用图神经网络来表示数量可变的候选基座位姿,并使用强化学习来确定它们之间的最佳基座位姿。我们表明,VBM-NET可以在明显更少的计算时间内产生与经典方法相当的解决方案。此外,我们通过成功地将模拟中训练的策略部署到真实世界的移动操作中来验证sim-to-real迁移。
🔬 方法详解
问题定义:论文旨在解决移动操作中,如何从视觉输入(俯视正交投影)高效、准确地选择最佳移动基座位姿的问题。现有方法通常依赖于精确的物体位姿和环境模型,这在实际应用中难以保证。此外,传统规划方法计算量大,难以满足实时性要求。
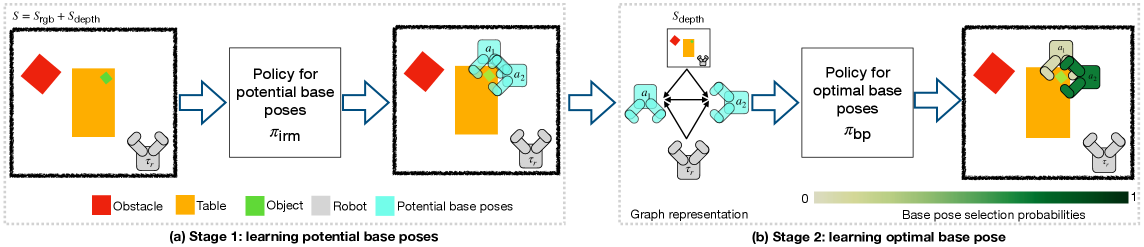
核心思路:论文的核心思路是利用深度学习直接从视觉输入中学习基座位姿选择策略。通过俯视正交投影获取场景的全局信息,并利用等变TransporterNet学习候选位姿,从而避免了对精确状态信息的依赖。使用图神经网络处理数量可变的候选位姿,并结合强化学习选择最优位姿,实现了高效的位姿选择。
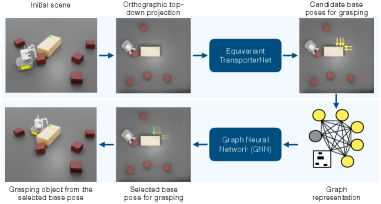
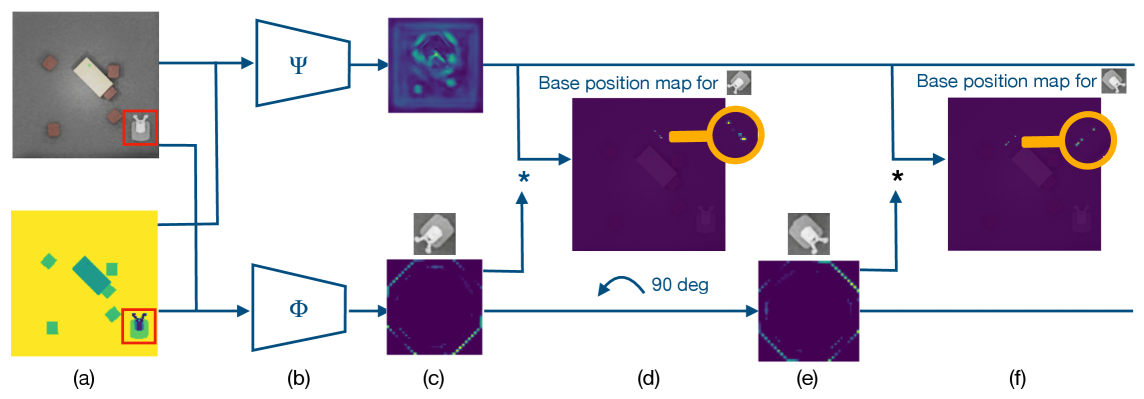
技术框架:VBM-NET的整体框架包含以下几个主要模块:1) 输入表示:使用俯视正交投影作为场景的视觉输入。2) 等变TransporterNet:用于学习候选基座位姿,利用空间对称性提高学习效率。3) 图神经网络 (GNN):用于表示和处理数量可变的候选位姿,每个节点代表一个候选位姿。4) 强化学习 (RL):用于在GNN输出的候选位姿中选择最优位姿,训练目标是最大化抓取成功率。
关键创新:论文的关键创新在于:1) 直接从视觉输入学习基座位姿选择策略,避免了对精确状态信息的依赖。2) 利用等变TransporterNet学习候选位姿,提高了学习效率和泛化能力。3) 使用图神经网络处理数量可变的候选位姿,能够灵活适应不同的场景。4) 结合强化学习选择最优位姿,实现了端到端的优化。
关键设计:TransporterNet采用等变卷积,保证网络输出对输入变换的等变性。GNN使用消息传递机制,节点特征包含位姿信息,边特征表示位姿之间的关系。强化学习使用Actor-Critic算法,Actor网络输出位姿选择概率,Critic网络评估当前状态的价值。损失函数包括TransporterNet的位姿预测损失和强化学习的奖励函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VBM-NET在基座位姿选择任务中取得了与经典方法相当的性能,但计算时间显著减少。此外,通过sim-to-real迁移实验,验证了VBM-NET在真实环境中的有效性。具体而言,VBM-NET在模拟环境训练的策略成功部署到真实机器人上,实现了稳定的抓取操作。
🎯 应用场景
该研究成果可应用于各种移动操作任务,例如仓库拣选、家庭服务机器人、医疗辅助机器人等。通过视觉输入直接学习基座位姿选择策略,可以提高机器人的自主性和适应性,降低对环境建模和状态估计的依赖,从而实现更鲁棒、更高效的移动操作。
📄 摘要(原文)
In Mobile Manipulation, selecting an optimal mobile base pose is essential for successful object grasping. Previous works have addressed this problem either through classical planning methods or by learning state-based policies. They assume access to reliable state information, such as the precise object poses and environment models. In this work, we study base pose planning directly from top-down orthographic projections of the scene, which provide a global overview of the scene while preserving spatial structure. We propose VBM-NET, a learning-based method for base pose selection using such top-down orthographic projections. We use equivariant TransporterNet to exploit spatial symmetries and efficiently learn candidate base poses for grasping. Further, we use graph neural networks to represent a varying number of candidate base poses and use Reinforcement Learning to determine the optimal base pose among them. We show that VBM-NET can produce comparable solutions to the classical methods in significantly less computation time. Furthermore, we validate sim-to-real transfer by successfully deploying a policy trained in simulation to real-world mobile manipulation.