SITCOM: Scaling Inference-Time COMpute for VLAs
作者: Ayudh Saxena, Harsh Shah, Sandeep Routray, Rishi Rajesh Shah, Esha Pahwa
分类: cs.RO
发布日期: 2025-10-05
备注: Accepted at the NeurIPS 2025 Workshop on Space in Vision, Language, and Embodied AI (SpaVLE). *Equal contribution
💡 一句话要点
SITCOM:通过扩展推理时计算能力提升VLA模型在机器人任务中的性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人控制 模型预测控制 长时程规划 动力学模型
📋 核心要点
- 现有VLA模型在机器人控制中面临挑战,缺乏前瞻能力,易受误差累积影响,难以进行长时程规划。
- SITCOM框架通过引入基于模型的rollout和奖励驱动的轨迹选择,增强VLA模型,使其具备长时程规划能力。
- 实验表明,SITCOM结合奖励函数,能显著提升SIMPLER环境中机器人任务的完成率,从48%提升至72%。
📝 摘要(中文)
由于标注数据的高成本、对未见环境的泛化能力有限以及长时程规划的困难,学习鲁棒的机器人控制策略仍然是一个主要的挑战。视觉-语言-动作(VLA)模型通过将自然语言指令转化为单步控制命令,提供了一个有希望的解决方案,但它们通常缺乏前瞻机制,并且在动态任务中容易出现误差累积。我们提出了SITCOM,一个通过基于模型的rollout和基于奖励的轨迹选择来增强预训练VLA模型的框架,其灵感来自模型预测控制算法。SITCOM利用学习到的动力学模型来模拟多步动作rollout,从而选择最佳候选计划用于真实世界的执行,将一次性VLA转化为鲁棒的长时程规划器。我们开发了一个高效的基于Transformer的动力学模型,该模型在大型BridgeV2数据上进行训练,并在SIMPLER环境中进行微调,以弥合Real2Sim差距,并使用来自模拟器的奖励对候选rollout进行评分。通过在SIMPLER环境中的多个任务和设置中进行的全面评估,我们证明了SITCOM与良好的奖励函数相结合,可以使用训练的动力学模型将任务完成率从48%显著提高到72%。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人控制任务中,尤其是长时程任务中表现不佳。主要痛点在于缺乏前瞻性规划能力,容易受到单步决策误差累积的影响,导致任务失败。此外,真实世界数据的收集成本高昂,限制了模型的训练和泛化能力。
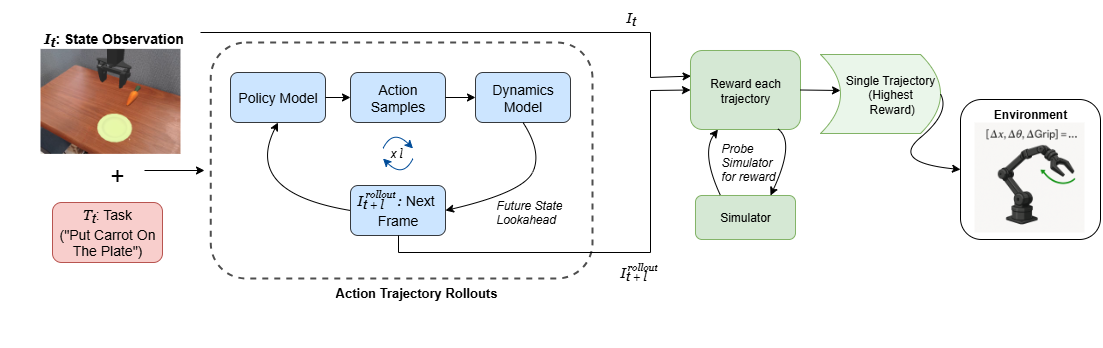
核心思路:SITCOM的核心思路是借鉴模型预测控制(MPC)的思想,通过学习一个动力学模型来预测未来状态,并基于此进行多步动作rollout。然后,利用奖励函数对rollout的轨迹进行评估,选择最优的动作序列执行。这样可以将单步VLA模型转化为具有长时程规划能力的控制策略。
技术框架:SITCOM框架主要包含以下几个模块:1) 预训练的VLA模型:用于将自然语言指令转化为单步动作;2) 动力学模型:用于预测给定状态和动作序列下的未来状态;3) rollout模块:基于动力学模型进行多步动作rollout,生成候选轨迹;4) 奖励函数:用于评估候选轨迹的质量;5) 轨迹选择模块:选择奖励最高的轨迹作为最终执行的动作序列。整体流程是,首先使用VLA模型生成初始动作,然后利用动力学模型进行rollout,使用奖励函数评估rollout结果,选择最优轨迹,并重复该过程。
关键创新:SITCOM的关键创新在于将模型预测控制的思想引入到VLA模型中,使其具备了长时程规划能力。通过学习动力学模型和使用奖励函数,SITCOM能够有效地克服单步决策误差累积的问题,提高任务完成率。此外,SITCOM框架具有通用性,可以与任何预训练的VLA模型结合使用。
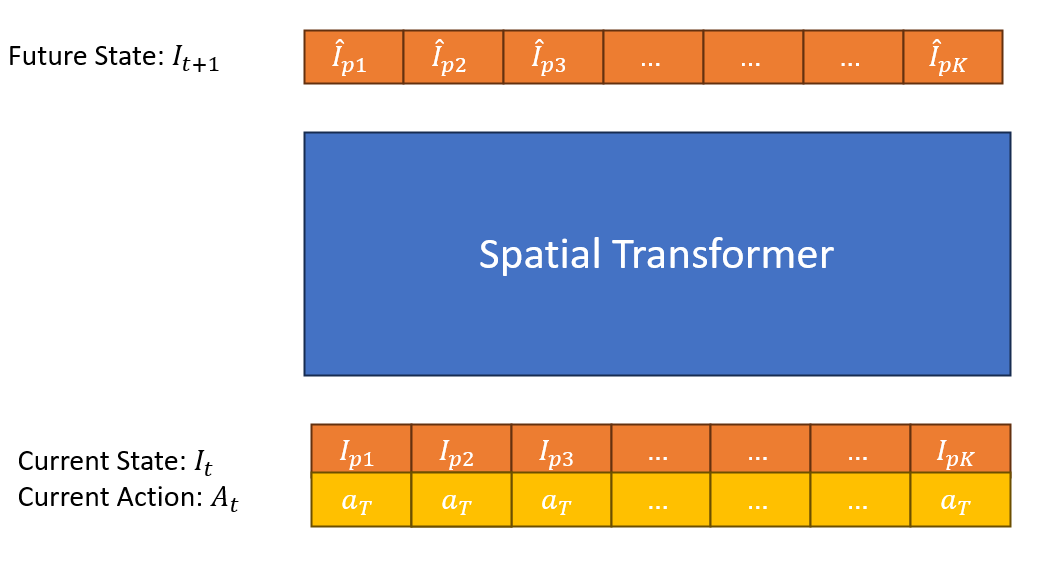
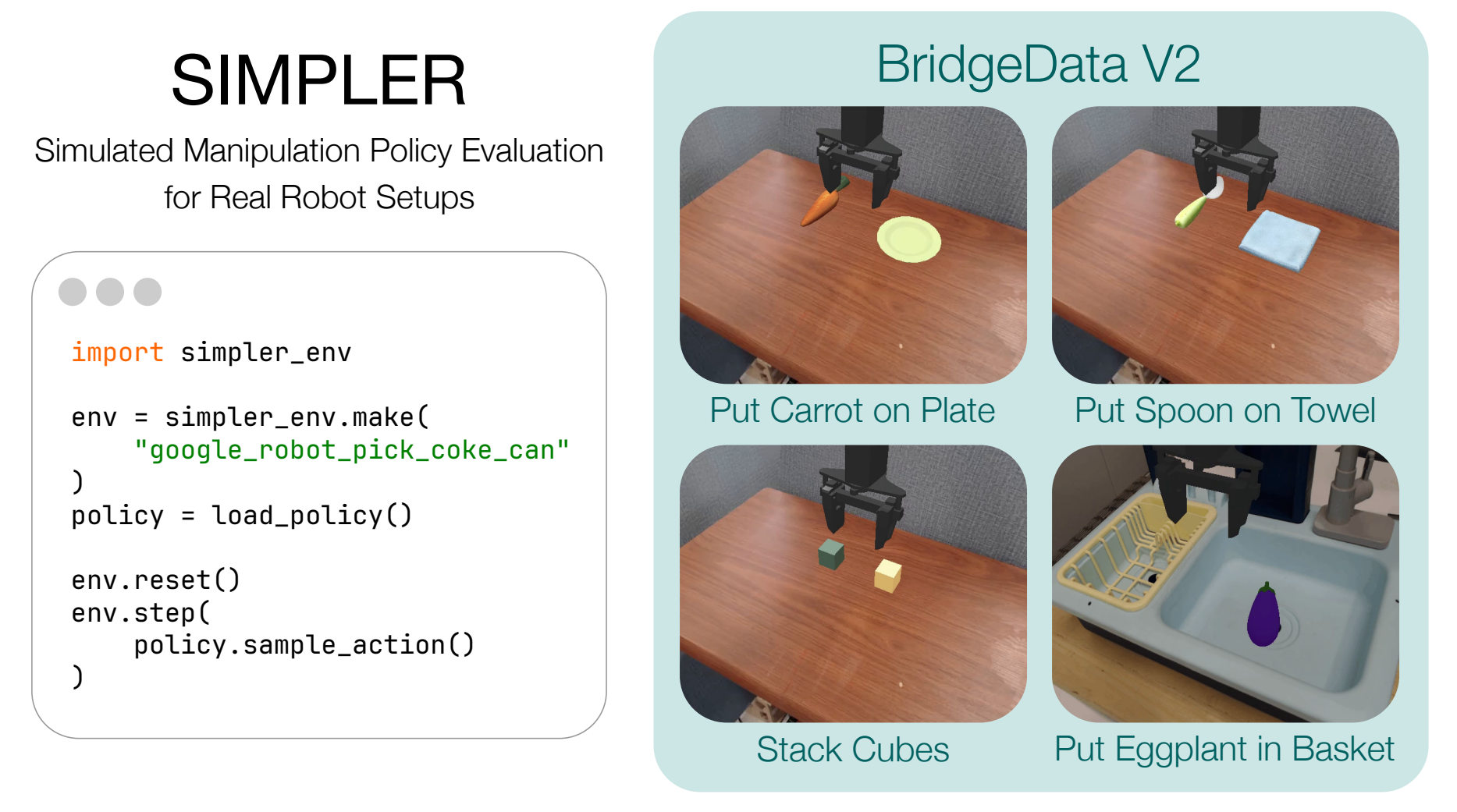
关键设计:动力学模型采用基于Transformer的网络结构,以提高建模能力。该模型在大型BridgeV2数据集上进行预训练,然后在SIMPLER环境中进行微调,以缩小Real2Sim差距。奖励函数的设计至关重要,需要能够准确反映任务目标。在实验中,使用了基于模拟器的奖励函数。Rollout的步数是一个重要的参数,需要根据任务的复杂程度进行调整。未知的是,具体的Transformer结构细节,以及奖励函数的具体形式。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SITCOM框架能够显著提高SIMPLER环境中机器人任务的完成率。在多个任务和设置下,SITCOM与良好的奖励函数相结合,可以将任务完成率从48%提高到72%。这表明SITCOM能够有效地克服单步决策误差累积的问题,提高机器人的鲁棒性和泛化能力。具体的基线模型和对比细节未知。
🎯 应用场景
SITCOM框架具有广泛的应用前景,可以应用于各种需要长时程规划的机器人任务中,例如家庭服务机器人、工业自动化机器人、自动驾驶等。该框架可以帮助机器人更好地理解人类指令,并自主完成复杂的任务。此外,SITCOM还可以应用于虚拟现实、游戏等领域,提高虚拟角色的智能水平。
📄 摘要(原文)
Learning robust robotic control policies remains a major challenge due to the high cost of collecting labeled data, limited generalization to unseen environments, and difficulties in planning over long horizons. While Vision-Language-Action (VLA) models offer a promising solution by grounding natural language instructions into single-step control commands, they often lack mechanisms for lookahead and struggle with compounding errors in dynamic tasks. In this project, we introduce Scaling Inference-Time COMpute for VLAs (SITCOM), a framework that augments any pretrained VLA with model-based rollouts and reward-based trajectory selection, inspired by Model Predictive Control algorithm. SITCOM leverages a learned dynamics model to simulate multi-step action rollouts to select the best candidate plan for real-world execution, transforming one-shot VLAs into robust long-horizon planners. We develop an efficient transformer-based dynamics model trained on large-scale BridgeV2 data and fine-tuned on SIMPLER environments to bridge the Real2Sim gap, and score candidate rollouts using rewards from simulator. Through comprehensive evaluation across multiple tasks and settings in the SIMPLER environment, we demonstrate that SITCOM when combined with a good reward function can significantly improve task completion rate from 48% to 72% using trained dynamics model.