Seeing the Bigger Picture: 3D Latent Mapping for Mobile Manipulation Policy Learning
作者: Sunghwan Kim, Woojeh Chung, Zhirui Dai, Dwait Bhatt, Arth Shukla, Hao Su, Yulun Tian, Nikolay Atanasov
分类: cs.RO
发布日期: 2025-10-04
备注: Project website can be found at https://existentialrobotics.org/sbp_page/
💡 一句话要点
提出基于3D隐空间地图的移动操作策略学习方法,增强空间和时间推理能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 移动操作 3D隐空间地图 策略学习 多视角融合 长时程记忆
📋 核心要点
- 现有移动操作策略依赖图像,缺乏全局空间和时间推理能力,限制了复杂任务的完成。
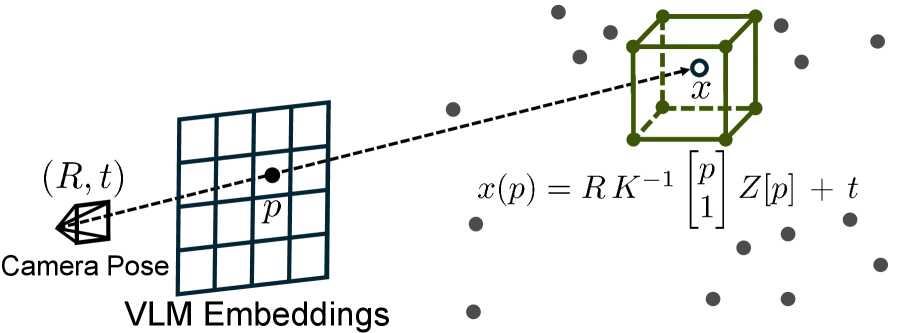
- SBP方法构建3D隐空间地图,融合多视角观测,扩展感知范围,并利用预训练解码器在线优化地图特征。
- 实验表明,SBP在场景理解和长时程记忆方面优于图像策略,顺序操作任务成功率提升25%。
📝 摘要(中文)
本文提出了一种名为“Seeing the Bigger Picture (SBP)”的端到端策略学习方法,该方法直接作用于3D隐空间特征地图,从而使移动操作策略能够实现比仅依赖图像的策略更强的空间和时间推理能力。SBP方法将多视角观测增量式地融合到场景特定的隐空间特征网格中,从而扩展了机器人当前视野之外的感知范围,并聚合了长时程的观测信息。一个预训练的、场景无关的解码器从这些特征中重建目标嵌入,并支持在任务执行期间在线优化地图特征。策略将隐空间地图视为状态变量,并利用通过3D特征聚合器获得的全局上下文信息,可以通过行为克隆或强化学习进行训练。在场景级移动操作和顺序桌面操作任务上的评估表明,SBP能够 (i) 在场景中进行全局推理,(ii) 将地图用作长时程记忆,并且 (iii) 在同分布和新场景中均优于基于图像的策略,例如,顺序操作任务的成功率提高了25%。
🔬 方法详解
问题定义:现有基于图像的移动操作策略在处理需要全局场景理解和长时程记忆的任务时表现不足。它们难以整合来自不同视角的观测信息,并且缺乏对过去状态的有效记忆,导致在复杂环境中难以进行有效的规划和控制。
核心思路:本文的核心思路是构建一个3D隐空间地图,将多视角观测融合到该地图中,从而扩展机器人的感知范围,并提供对场景的全局理解。通过将地图视为状态变量,策略可以利用来自地图的全局上下文信息进行决策,从而实现更强的空间和时间推理能力。
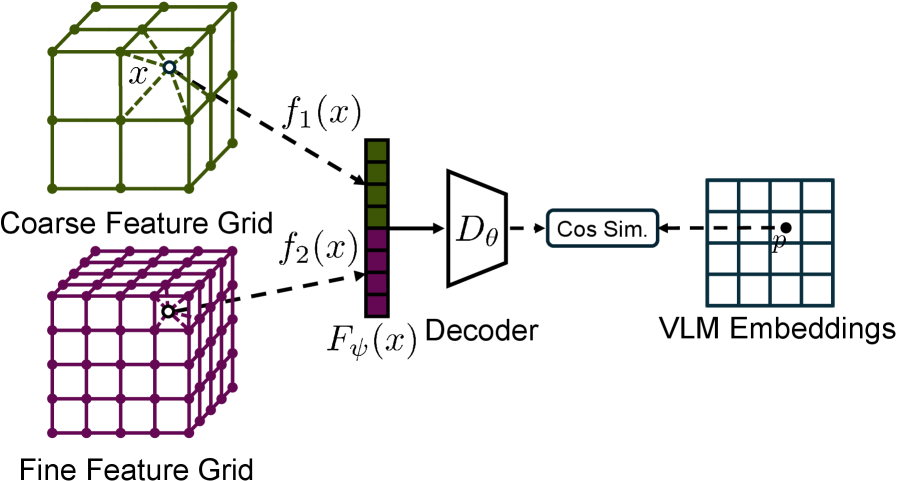
技术框架:SBP方法包含以下主要模块:1) 多视角观测模块,用于获取来自不同视角的图像信息;2) 隐空间特征提取模块,用于将图像信息转换为隐空间特征;3) 3D隐空间地图构建模块,用于将多视角观测融合到3D地图中;4) 预训练解码器,用于从地图特征中重建目标嵌入,并支持在线优化;5) 策略学习模块,用于训练基于隐空间地图的移动操作策略。整体流程是:机器人通过多视角观测获取图像信息,提取隐空间特征,构建3D地图,策略根据地图信息进行决策,控制机器人执行动作。
关键创新:最重要的技术创新点在于将3D隐空间地图作为策略的状态变量。与传统的基于图像的策略相比,SBP方法能够利用地图提供的全局上下文信息,实现更强的空间和时间推理能力。此外,使用预训练的场景无关解码器进行在线优化,提高了地图的适应性和泛化能力。
关键设计:论文使用了预训练的视觉编码器(例如,VAE或对比学习模型)来提取图像的隐空间特征。3D地图采用体素网格表示,每个体素存储一个隐空间特征向量。多视角观测通过投影变换融合到地图中。解码器使用卷积神经网络进行训练,目标是重建目标嵌入。策略网络可以使用MLP或Transformer等结构,输入是地图特征,输出是机器人的动作。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SBP方法在场景级移动操作和顺序桌面操作任务上均优于基于图像的策略。在顺序操作任务中,SBP的成功率比基于图像的策略提高了25%。此外,SBP方法在新场景中也表现出良好的泛化能力,表明其具有较强的鲁棒性和适应性。
🎯 应用场景
该研究成果可应用于各种移动操作任务,例如家庭服务机器人、仓库自动化、灾难救援等。通过增强机器人的空间和时间推理能力,可以使其在复杂环境中更有效地完成任务,提高工作效率和安全性。未来,该方法可以扩展到更复杂的环境和任务,例如多机器人协作、动态环境等。
📄 摘要(原文)
In this paper, we demonstrate that mobile manipulation policies utilizing a 3D latent map achieve stronger spatial and temporal reasoning than policies relying solely on images. We introduce Seeing the Bigger Picture (SBP), an end-to-end policy learning approach that operates directly on a 3D map of latent features. In SBP, the map extends perception beyond the robot's current field of view and aggregates observations over long horizons. Our mapping approach incrementally fuses multiview observations into a grid of scene-specific latent features. A pre-trained, scene-agnostic decoder reconstructs target embeddings from these features and enables online optimization of the map features during task execution. A policy, trainable with behavior cloning or reinforcement learning, treats the latent map as a state variable and uses global context from the map obtained via a 3D feature aggregator. We evaluate SBP on scene-level mobile manipulation and sequential tabletop manipulation tasks. Our experiments demonstrate that SBP (i) reasons globally over the scene, (ii) leverages the map as long-horizon memory, and (iii) outperforms image-based policies in both in-distribution and novel scenes, e.g., improving the success rate by 25% for the sequential manipulation task.