Model-Based Adaptive Precision Control for Tabletop Planar Pushing Under Uncertain Dynamics
作者: Aydin Ahmadi, Baris Akgun
分类: cs.RO
发布日期: 2025-10-04
💡 一句话要点
提出基于模型的自适应精度控制方法,解决不确定动力学下的桌面平面推移任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 平面推移 模型预测控制 循环神经网络 动力学建模 机器人控制
📋 核心要点
- 现有数据驱动的平面推移方法泛化性不足,难以同时处理多种任务,需要针对特定任务进行训练。
- 提出一种基于模型的框架,利用循环神经网络学习对象-环境动力学,并结合MPPI控制器生成自适应动作。
- 实验表明,该方法在精确位置控制、轨迹跟踪和避障方面表现出色,且无需针对不同任务进行重新训练。
📝 摘要(中文)
本文提出了一种基于模型的非抓取桌面推移框架,该框架使用单个学习模型来处理多个任务,无需重新训练。该方法采用基于循环GRU的架构,并添加非线性层,以捕获对象-环境动力学,同时确保稳定性。定制的状态-动作表示使模型能够泛化到不确定的动力学、可变推移长度和不同的任务。在控制方面,我们将学习到的动力学与基于采样的模型预测路径积分(MPPI)控制器集成,该控制器生成自适应的、面向任务的动作。该框架支持侧面切换、可变长度推移以及精确的定位、轨迹跟踪和避障等目标。在模拟环境中进行训练,并进行域随机化以支持从模拟到真实的迁移。通过消融研究评估了该架构,表明预测精度和稳定rollout得到了提高。然后,使用带有无标记跟踪的Franka Panda机器人在模拟和真实世界实验中验证了整个系统。结果表明,在严格的阈值下,精确的定位具有很高的成功率,并且在轨迹跟踪和避障方面表现出色。此外,只需更改控制器的目标函数即可解决多个任务,而无需重新训练。虽然目前的工作重点是单一对象类型,但通过训练更长的推移长度并设计一个平衡的控制器来减少更长horizon目标所需的步数,从而扩展了该框架。
🔬 方法详解
问题定义:论文旨在解决在不确定动力学条件下,如何实现桌面平面推移的精确控制问题。现有数据驱动方法通常针对特定任务进行训练,泛化能力有限,难以适应不同的推移长度和目标。此外,缺乏对动力学不确定性的有效建模,导致控制性能下降。
核心思路:论文的核心思路是利用学习到的动力学模型来预测推移过程中的状态变化,并结合模型预测控制(MPC)方法,生成最优的控制动作。通过循环神经网络(GRU)学习对象与环境的交互动力学,并使用模型预测路径积分(MPPI)控制器进行轨迹优化,从而实现精确的推移控制。
技术框架:整体框架包括三个主要模块:1) 数据收集:在模拟环境中进行随机推移,收集状态-动作数据。2) 动力学模型学习:使用GRU网络学习状态转移函数,预测给定状态和动作下的下一个状态。3) 控制器设计:使用MPPI控制器,根据学习到的动力学模型,生成最优的推移轨迹。该控制器通过采样不同的动作序列,并根据预测的轨迹成本选择最优动作。
关键创新:该论文的关键创新在于:1) 使用单个学习模型来处理多个任务,无需针对不同任务进行重新训练。2) 采用循环神经网络(GRU)来建模对象-环境动力学,能够有效捕捉时间序列依赖关系。3) 结合模型预测路径积分(MPPI)控制器,实现自适应的、面向任务的控制。
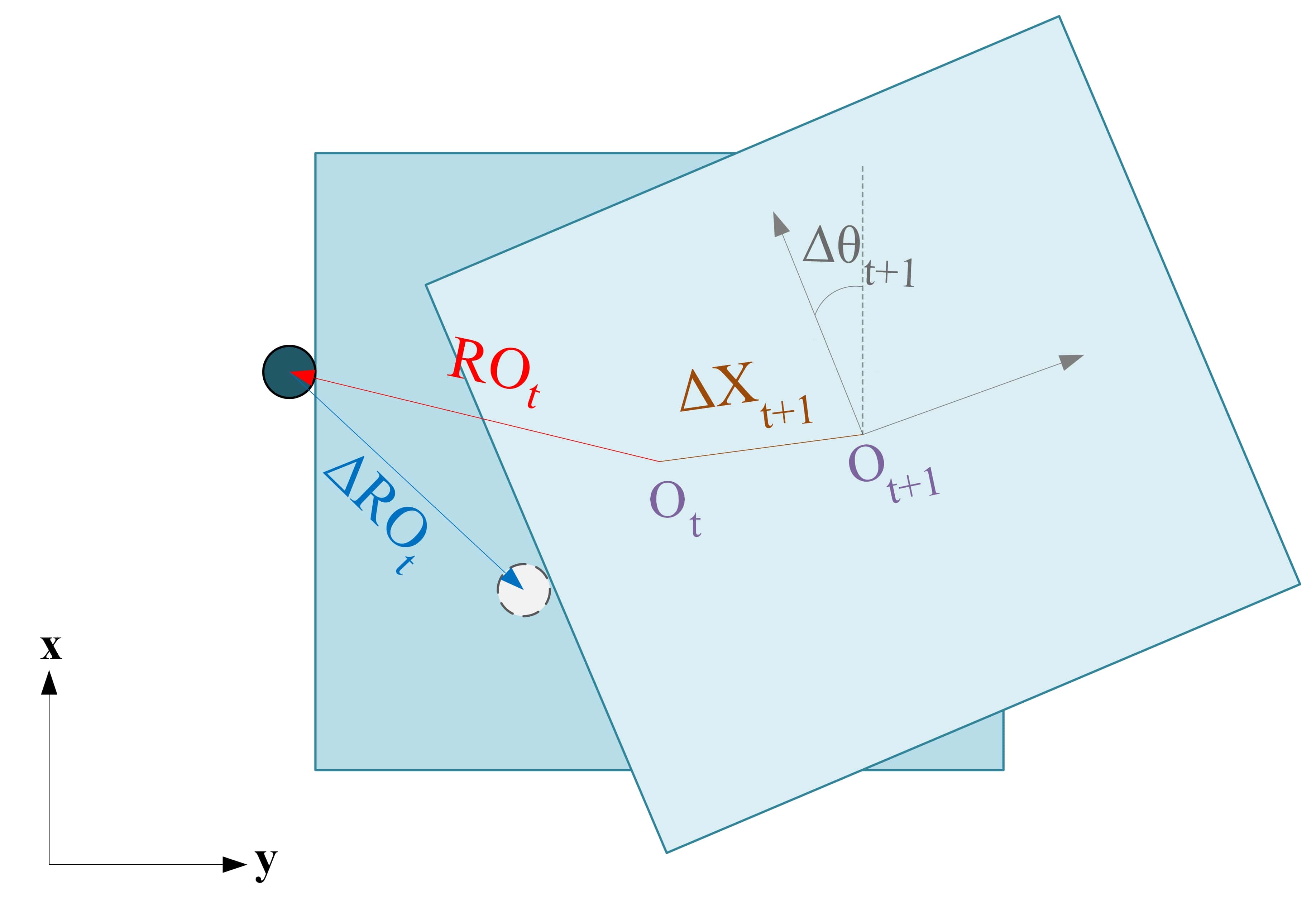
关键设计:状态表示包括物体的位置、姿态等信息。动作表示包括推移的方向和距离。GRU网络的输入为当前状态和动作,输出为下一个状态的预测值。损失函数采用均方误差(MSE)来衡量预测状态与真实状态之间的差异。MPPI控制器的成本函数包括目标位置的距离、轨迹长度等因素。域随机化用于提高模型在真实环境中的泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在精确位置控制方面取得了很高的成功率,在严格的阈值下也能实现精确的定位。在轨迹跟踪和避障方面也表现出强大的性能。此外,通过改变控制器的目标函数,无需重新训练即可解决多个任务。消融实验验证了GRU网络和MPPI控制器的有效性,表明它们能够提高预测精度和控制性能。
🎯 应用场景
该研究成果可应用于自动化装配、物流分拣、机器人辅助操作等领域。例如,在自动化装配中,机器人可以通过推移操作精确地调整零件的位置和姿态,从而提高装配效率和精度。在物流分拣中,机器人可以利用推移操作将不同类型的物品分拣到指定的位置。该研究的未来影响在于,可以降低机器人操作的复杂性,提高机器人的自主性和适应性。
📄 摘要(原文)
Data-driven planar pushing methods have recently gained attention as they reduce manual engineering effort and improve generalization compared to analytical approaches. However, most prior work targets narrow capabilities (e.g., side switching, precision, or single-task training), limiting broader applicability. We present a model-based framework for non-prehensile tabletop pushing that uses a single learned model to address multiple tasks without retraining. Our approach employs a recurrent GRU-based architecture with additional non-linear layers to capture object-environment dynamics while ensuring stability. A tailored state-action representation enables the model to generalize across uncertain dynamics, variable push lengths, and diverse tasks. For control, we integrate the learned dynamics with a sampling-based Model Predictive Path Integral (MPPI) controller, which generates adaptive, task-oriented actions. This framework supports side switching, variable-length pushes, and objectives such as precise positioning, trajectory following, and obstacle avoidance. Training is performed in simulation with domain randomization to support sim-to-real transfer. We first evaluate the architecture through ablation studies, showing improved prediction accuracy and stable rollouts. We then validate the full system in simulation and real-world experiments using a Franka Panda robot with markerless tracking. Results demonstrate high success rates in precise positioning under strict thresholds and strong performance in trajectory tracking and obstacle avoidance. Moreover, multiple tasks are solved simply by changing the controller's objective function, without retraining. While our current focus is on a single object type, we extend the framework by training on wider push lengths and designing a balanced controller that reduces the number of steps for longer-horizon goals.