EmbodiSwap for Zero-Shot Robot Imitation Learning
作者: Eadom Dessalene, Pavan Mantripragada, Michael Maynord, Yiannis Aloimonos
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-10-04
备注: Video link: https://drive.google.com/file/d/1UccngwgPqUwPMhBja7JrXfZoTquCx_Qe/view?usp=sharing
💡 一句话要点
提出EmbodiSwap,用于零样本机器人模仿学习,弥合人与机器人之间的具身差距。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 机器人模仿学习 零样本学习 具身智能 合成数据 V-JEPA
📋 核心要点
- 现有模仿学习方法难以直接迁移人类视频中的知识到机器人,因为存在具身差距和视角差异。
- EmbodiSwap通过将逼真的合成机器人覆盖在人类视频上,生成机器人视角的训练数据,从而弥合具身差距。
- 实验表明,使用EmbodiSwap和V-JEPA训练的零样本模型在真实机器人任务中取得了显著的成功率,优于其他基线方法。
📝 摘要(中文)
本文提出了一种名为EmbodiSwap的方法,用于生成逼真的合成机器人覆盖在人类视频上的图像。EmbodiSwap被应用于零样本模仿学习,弥合了真实场景中以人为中心的视频与目标机器人具身之间的差距。我们利用EmbodiSwap生成的数据训练了一个闭环机器人操作策略。我们创新性地使用了V-JEPA作为视觉骨干网络,将V-JEPA从视频理解领域重新用于基于合成机器人视频的模仿学习。采用V-JEPA优于机器人领域中更常用的替代视觉骨干网络。在真实世界的测试中,我们的零样本训练的V-JEPA模型实现了82%的成功率,优于经过少量样本训练的$π_0$网络以及在EmbodiSwap生成的数据上训练的$π_0$网络。我们发布了(i)用于生成合成机器人覆盖的代码,该代码以人类视频和任意机器人URDF作为输入并生成机器人数据集,(ii)我们在EPIC-Kitchens、HOI4D和Ego4D上合成的机器人数据集,以及(iii)模型检查点和推理代码,以促进可重复的研究和更广泛的应用。
🔬 方法详解
问题定义:现有机器人模仿学习方法通常需要大量的机器人数据,或者难以直接将人类演示迁移到机器人上,因为人类和机器人的具身不同,视角也存在差异。这导致了训练数据获取成本高昂,且泛化能力有限。
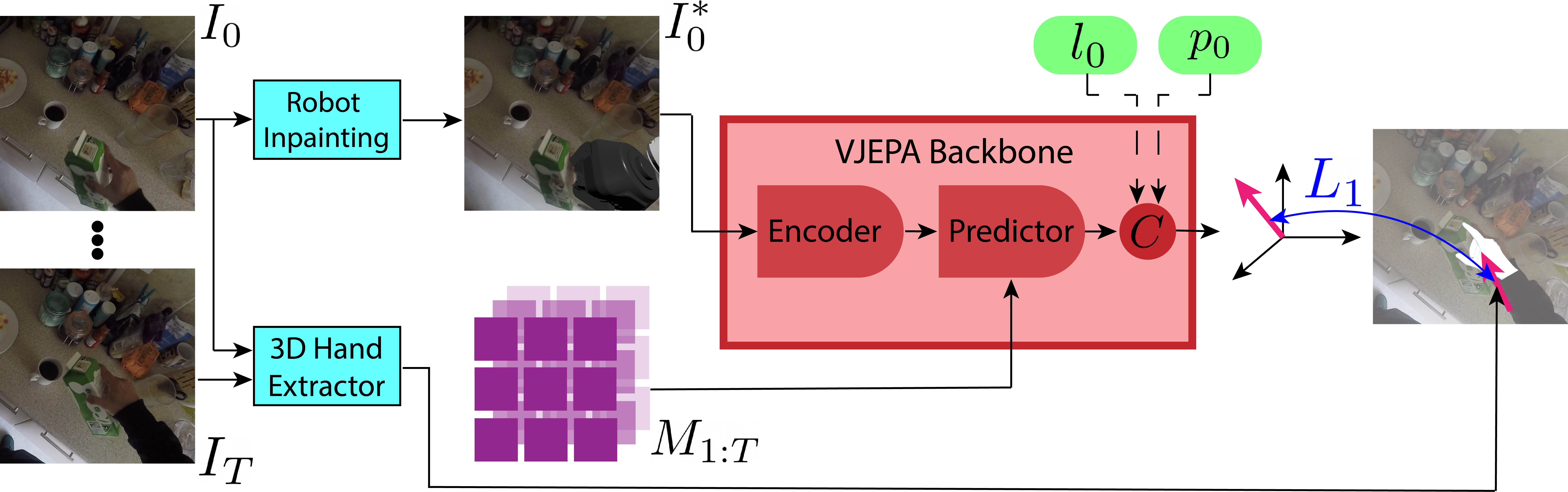
核心思路:本文的核心思路是利用计算机图形学技术,将人类视频中的动作“转移”到机器人身上,生成合成的机器人视角视频。这样,就可以利用大量现成的人类视频数据,通过模仿学习训练机器人策略,而无需实际的机器人演示。
技术框架:整体框架包含两个主要阶段:1) EmbodiSwap:将机器人模型覆盖到人类视频上,生成合成的机器人视频数据。该模块接收人类视频和机器人URDF模型作为输入,输出带有逼真机器人覆盖的视频。2) 模仿学习:使用生成的合成数据训练机器人控制策略。该模块使用V-JEPA作为视觉骨干网络,学习从视频帧到机器人动作的映射。
关键创新:1) EmbodiSwap技术:能够逼真地将机器人模型覆盖到人类视频上,生成高质量的合成训练数据。2) V-JEPA的应用:将V-JEPA从视频理解领域迁移到机器人模仿学习领域,并证明其优于传统的视觉骨干网络。
关键设计:EmbodiSwap的关键设计包括:精确的机器人模型渲染、光照和阴影的模拟、以及与人类视频的无缝融合。模仿学习的关键设计包括:使用V-JEPA作为视觉特征提取器,以及设计合适的损失函数来训练机器人控制策略。具体参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用EmbodiSwap和V-JEPA训练的零样本模型在真实机器人任务中取得了82%的成功率,显著优于经过少量样本训练的$π_0$网络以及在EmbodiSwap生成的数据上训练的$π_0$网络。这表明了该方法的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业机器人等。通过利用大量现成的人类视频数据,可以降低机器人训练成本,提高机器人的泛化能力和适应性。该方法还可以用于远程操作,允许人类通过观察远程环境中的人类操作员来控制机器人。
📄 摘要(原文)
We introduce EmbodiSwap - a method for producing photorealistic synthetic robot overlays over human video. We employ EmbodiSwap for zero-shot imitation learning, bridging the embodiment gap between in-the-wild ego-centric human video and a target robot embodiment. We train a closed-loop robot manipulation policy over the data produced by EmbodiSwap. We make novel use of V-JEPA as a visual backbone, repurposing V-JEPA from the domain of video understanding to imitation learning over synthetic robot videos. Adoption of V-JEPA outperforms alternative vision backbones more conventionally used within robotics. In real-world tests, our zero-shot trained V-JEPA model achieves an $82\%$ success rate, outperforming a few-shot trained $π_0$ network as well as $π_0$ trained over data produced by EmbodiSwap. We release (i) code for generating the synthetic robot overlays which takes as input human videos and an arbitrary robot URDF and generates a robot dataset, (ii) the robot dataset we synthesize over EPIC-Kitchens, HOI4D and Ego4D, and (iii) model checkpoints and inference code, to facilitate reproducible research and broader adoption.