Learning to Act Through Contact: A Unified View of Multi-Task Robot Learning
作者: Shafeef Omar, Majid Khadiv
分类: cs.RO
发布日期: 2025-10-04
💡 一句话要点
提出基于接触的统一多任务机器人学习框架,实现通用运动与操作策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人学习 强化学习 多任务学习 接触规划 运动操作 目标条件策略 机器人控制
📋 核心要点
- 现有机器人控制方法通常为每个任务设计独立策略,缺乏通用性,难以应对复杂多变的场景。
- 论文提出基于接触目标的统一框架,将不同任务转化为接触序列,利用共享结构学习通用策略。
- 实验表明,该框架在多种机器人形态和任务中表现出鲁棒性和泛化能力,验证了显式接触推理的有效性。
📝 摘要(中文)
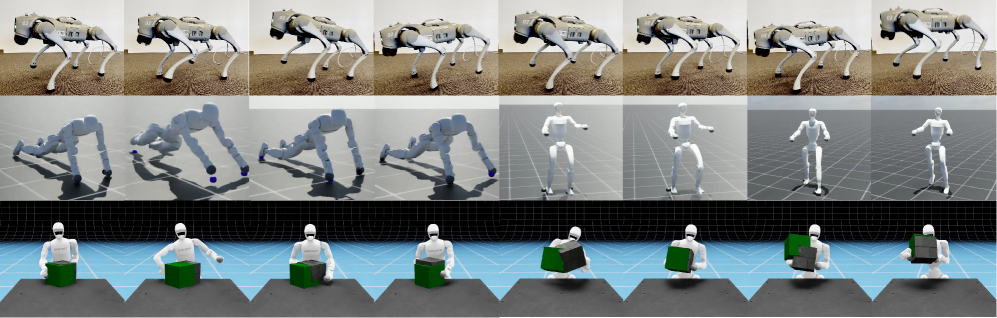
本文提出了一种统一的框架,用于多任务运动和操作策略学习,该框架基于显式接触表示。不同于为不同任务设计不同的策略,我们的方法通过一系列接触目标(期望的接触位置、时间和主动末端执行器)统一了任务的定义。这使得能够利用不同接触密集型任务之间的共享结构,从而产生一个能够执行各种任务的单一策略。具体而言,我们训练了一个目标条件强化学习(RL)策略来实现给定的接触计划。我们在多个机器人实体和任务上验证了我们的框架:四足机器人执行多个步态,人形机器人执行多个双足和四足步态,以及人形机器人执行不同的双手物体操作任务。每个场景都由一个单一策略控制,该策略经过训练以执行基于接触的不同任务,从而在形态上不同的系统中展示了通用和鲁棒的行为。我们的结果表明,显式接触推理显著提高了对未见场景的泛化能力,将显式接触策略学习定位为可扩展的运动操作的有希望的基础。
🔬 方法详解
问题定义:现有机器人控制方法通常针对特定任务设计策略,难以泛化到新的任务或环境。特别是对于运动和操作结合的任务(loco-manipulation),需要分别设计运动和操作策略,增加了复杂性。现有方法难以有效利用不同任务之间的共性,导致学习效率低下。
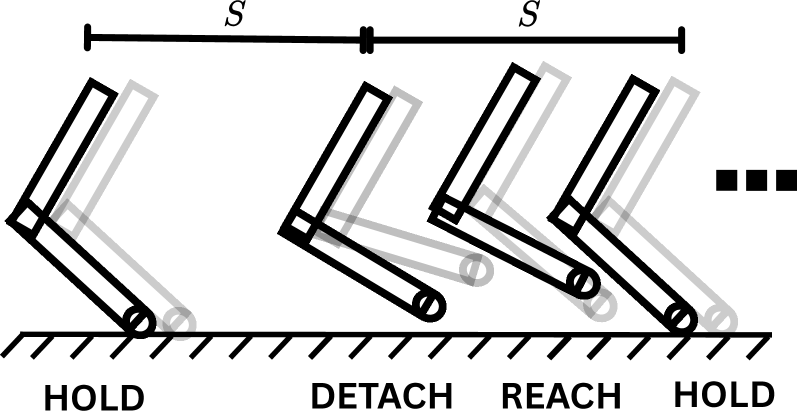
核心思路:论文的核心思路是将不同的运动和操作任务统一表示为一系列的接触目标。通过定义期望的接触位置、时间和主动末端执行器,可以将不同的任务转化为相同的形式。然后,利用强化学习训练一个策略,使其能够根据给定的接触计划执行相应的动作。这种方法能够利用不同任务之间的共享结构,从而学习到一个通用的策略。
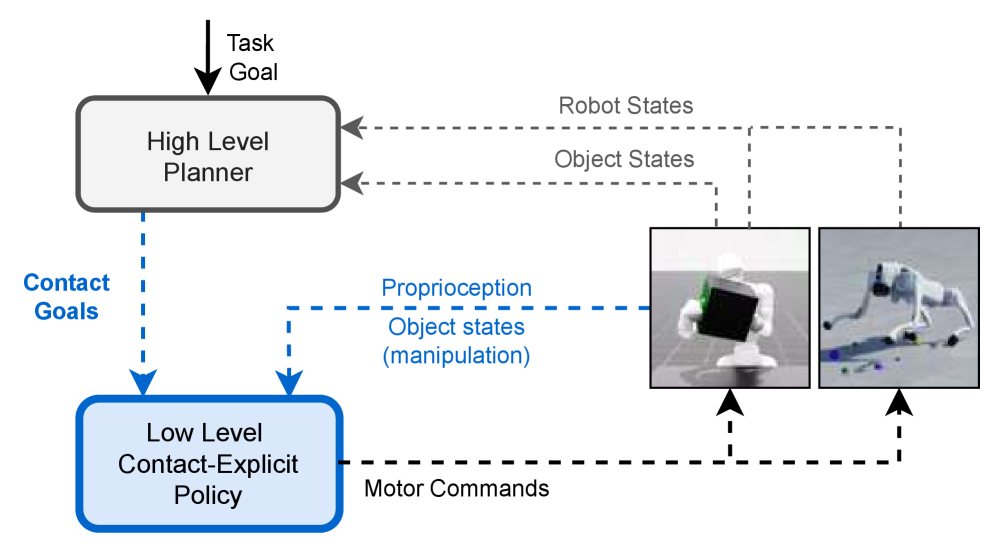
技术框架:该框架主要包含两个部分:接触计划生成器和目标条件强化学习策略。首先,接触计划生成器根据任务目标生成一系列的接触目标。然后,目标条件强化学习策略根据当前的机器人状态和接触目标,输出相应的动作。该策略使用强化学习进行训练,目标是最大化机器人在执行任务过程中的奖励。整体流程是:任务目标 -> 接触计划 -> 机器人动作 -> 环境反馈 -> 策略更新。
关键创新:最重要的技术创新点在于将不同的任务统一表示为接触目标序列。这种表示方法能够显式地表达任务中的接触信息,从而使得策略能够更好地理解任务的目标。与现有方法相比,该方法不需要为每个任务单独设计策略,而是可以学习到一个通用的策略,从而提高了泛化能力。
关键设计:论文使用目标条件强化学习算法进行策略训练。奖励函数的设计至关重要,需要考虑任务的完成情况、接触的准确性以及动作的平滑性。具体的网络结构未知,但推测使用了某种形式的循环神经网络或Transformer来处理接触目标序列。论文中没有明确提及具体的参数设置和损失函数,这部分信息未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架在多种机器人形态和任务中表现出良好的性能。例如,一个单一策略可以控制四足机器人执行多种步态,人形机器人执行双足和四足步态,以及人形机器人执行不同的双手物体操作任务。这些结果表明,该框架具有很强的通用性和鲁棒性,能够有效地解决多任务机器人学习问题。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要运动和操作结合的机器人任务,例如家庭服务机器人、工业自动化机器人和搜索救援机器人。通过学习通用的运动和操作策略,机器人可以更好地适应不同的环境和任务,提高工作效率和安全性。未来的研究可以进一步探索如何自动生成接触计划,从而实现更加自主的机器人控制。
📄 摘要(原文)
We present a unified framework for multi-task locomotion and manipulation policy learning grounded in a contact-explicit representation. Instead of designing different policies for different tasks, our approach unifies the definition of a task through a sequence of contact goals-desired contact positions, timings, and active end-effectors. This enables leveraging the shared structure across diverse contact-rich tasks, leading to a single policy that can perform a wide range of tasks. In particular, we train a goal-conditioned reinforcement learning (RL) policy to realise given contact plans. We validate our framework on multiple robotic embodiments and tasks: a quadruped performing multiple gaits, a humanoid performing multiple biped and quadrupedal gaits, and a humanoid executing different bimanual object manipulation tasks. Each of these scenarios is controlled by a single policy trained to execute different tasks grounded in contacts, demonstrating versatile and robust behaviours across morphologically distinct systems. Our results show that explicit contact reasoning significantly improves generalisation to unseen scenarios, positioning contact-explicit policy learning as a promising foundation for scalable loco-manipulation.