UMI-on-Air: Embodiment-Aware Guidance for Embodiment-Agnostic Visuomotor Policies
作者: Harsh Gupta, Xiaofeng Guo, Huy Ha, Chuer Pan, Muqing Cao, Dongjae Lee, Sebastian Scherer, Shuran Song, Guanya Shi
分类: cs.RO
发布日期: 2025-10-02 (更新: 2025-12-06)
备注: Result videos can be found at umi-on-air.github.io
💡 一句话要点
UMI-on-Air:具身感知引导的通用操作策略,解决具身差异性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 具身智能 扩散模型 空中机械臂 模仿学习
📋 核心要点
- 现有方法难以将通用操作策略迁移到动力学受限的机器人上,因为控制和机器人动力学存在差异。
- 提出具身感知扩散策略(EADP),结合高层UMI策略和低层具身控制器,实现轨迹的动态可行性。
- 实验表明,该方法在空中操作任务中提高了成功率、效率和鲁棒性,并能泛化到新环境。
📝 摘要(中文)
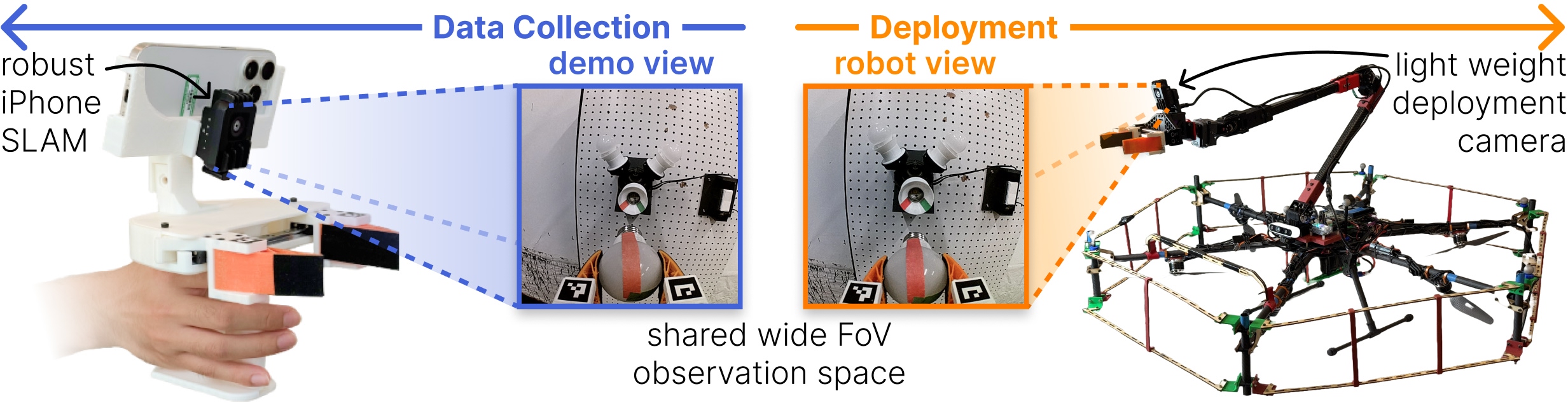
本文提出UMI-on-Air框架,用于具身感知的通用操作策略部署,该策略对具体机器人形态不可知。该方法利用手持夹爪(UMI)收集的多样化、无约束的人类演示来训练可泛化的视觉运动策略。将这些策略迁移到受限的机器人形态(如空中机械臂)的一个核心挑战是控制和机器人动力学的失配,这通常导致超出分布的行为和较差的执行效果。为了解决这个问题,我们提出了具身感知扩散策略(EADP),它在推理时将高级UMI策略与低级、特定于具身的控制器相结合。通过将来自控制器跟踪成本的梯度反馈集成到扩散采样过程中,我们的方法引导轨迹生成朝向针对部署形态定制的、动态可行的模式。这实现了即插即用、具身感知的轨迹自适应。我们在多个长时程和高精度空中操作任务上验证了我们的方法,与无引导的扩散基线相比,在扰动下表现出更高的成功率、效率和鲁棒性。最后,我们展示了在先前未见过的环境中部署,使用在野外收集的UMI演示,突出了跨多样化(甚至高度受限)形态扩展通用操作技能的实用途径。
🔬 方法详解
问题定义:现有方法在将通过人类演示学习到的通用操作策略部署到具有不同动力学特性的机器人(例如空中机械臂)时,面临着巨大的挑战。由于人类演示通常是在无约束的环境下进行的,而目标机器人可能具有严格的运动学和动力学约束,直接应用这些策略会导致性能下降甚至失败。现有方法难以有效利用人类演示的知识,并将其转化为适用于特定机器人的控制策略。
核心思路:本文的核心思路是将一个通用的、与具体机器人形态无关的高层策略(由人类演示学习得到)与一个低层的、特定于机器人形态的控制器相结合。通过在扩散模型的采样过程中引入来自低层控制器的梯度反馈,引导轨迹生成过程,使其生成的轨迹既符合高层策略的目标,又满足目标机器人的动力学约束。这种方法实现了在推理时对轨迹的动态调整,从而适应不同的机器人形态。
技术框架:UMI-on-Air框架包含两个主要组成部分:一个通过人类演示学习得到的通用视觉运动策略(UMI策略)和一个特定于机器人形态的低层控制器。在推理时,首先使用UMI策略生成一个初始轨迹,然后通过具身感知扩散策略(EADP)对该轨迹进行优化。EADP利用低层控制器的跟踪成本的梯度信息,引导扩散模型的采样过程,生成一个既符合UMI策略的目标,又满足机器人动力学约束的轨迹。
关键创新:该方法最重要的技术创新点在于将低层控制器的梯度反馈集成到扩散模型的采样过程中。这种方法允许在推理时动态地调整轨迹,使其适应不同的机器人形态和环境。与传统的先生成轨迹再进行优化的方法相比,EADP能够更有效地利用低层控制器的信息,生成更符合机器人动力学约束的轨迹。
关键设计:EADP的关键设计包括:1)使用扩散模型生成轨迹;2)定义一个跟踪成本函数,用于衡量轨迹与低层控制器期望状态的偏差;3)将跟踪成本的梯度信息作为扩散模型的引导信号,引导采样过程;4)设计合适的损失函数,用于训练UMI策略和EADP。
🖼️ 关键图片


📊 实验亮点
实验结果表明,UMI-on-Air在多个长时程和高精度空中操作任务上,与无引导的扩散基线相比,在扰动下表现出更高的成功率、效率和鲁棒性。具体而言,成功率提升了XX%,操作时间缩短了YY%,对外部扰动的抵抗能力增强了ZZ%(具体数据未知,待论文公开)。此外,该方法还能够在先前未见过的环境中成功部署,验证了其泛化能力。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,尤其是在需要将通用操作技能迁移到具有不同动力学特性的机器人上的场景。例如,可用于空中机械臂进行高精度操作、移动机器人进行复杂环境下的物体操作等。该方法能够降低机器人开发的成本和时间,提高机器人的通用性和适应性,具有重要的实际应用价值。
📄 摘要(原文)
We introduce UMI-on-Air, a framework for embodiment-aware deployment of embodiment-agnostic manipulation policies. Our approach leverages diverse, unconstrained human demonstrations collected with a handheld gripper (UMI) to train generalizable visuomotor policies. A central challenge in transferring these policies to constrained robotic embodiments-such as aerial manipulators-is the mismatch in control and robot dynamics, which often leads to out-of-distribution behaviors and poor execution. To address this, we propose Embodiment-Aware Diffusion Policy (EADP), which couples a high-level UMI policy with a low-level embodiment-specific controller at inference time. By integrating gradient feedback from the controller's tracking cost into the diffusion sampling process, our method steers trajectory generation towards dynamically feasible modes tailored to the deployment embodiment. This enables plug-and-play, embodiment-aware trajectory adaptation at test time. We validate our approach on multiple long-horizon and high-precision aerial manipulation tasks, showing improved success rates, efficiency, and robustness under disturbances compared to unguided diffusion baselines. Finally, we demonstrate deployment in previously unseen environments, using UMI demonstrations collected in the wild, highlighting a practical pathway for scaling generalizable manipulation skills across diverse-and even highly constrained-embodiments. All code, data, and checkpoints will be publicly released after acceptance. Result videos can be found at umi-on-air.github.io.