U-LAG: Uncertainty-Aware, Lag-Adaptive Goal Retargeting for Robotic Manipulation
作者: Anamika J H, Anujith Muraleedharan
分类: cs.RO
发布日期: 2025-10-02
备注: 8 pages, 5 figures. Accepted to the IROS 2025 Workshop on Perception and Planning for Mobile Manipulation in Changing Environments
💡 一句话要点
提出U-LAG,解决机器人操作中感知滞后和不确定性下的目标重定位问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting)
关键词: 机器人操作 目标重定位 感知滞后 不确定性感知 粒子滤波
📋 核心要点
- 现有机器人操作方法难以应对感知滞后和环境变化,导致任务失败。
- U-LAG通过可插拔的目标重定位模块,在感知和控制之间动态调整目标。
- UAR-PF利用不确定性感知,选择最大化预期进度的目标,提升操作成功率。
📝 摘要(中文)
本文提出U-LAG,一个中间执行目标重定位层,用于解决机器人操作中因感知滞后、噪声或过时信息带来的挑战。U-LAG在不改变底层控制器的情况下,通过重新瞄准任务目标(接触前、接触时、接触后)来适应新的观测。与运动重定位或通用视觉伺服不同,U-LAG将飞行中的目标重瞄准视为感知和控制之间可插拔的模块。主要技术贡献是UAR-PF,一种不确定性感知重定位器,它维护对象姿态在感知滞后下的分布,并选择能最大化预期进度的目标。在PyBullet/PandaGym中,针对抓取、推动、堆叠和插桩任务,构建了可复现的位移x滞后压力测试,在接近过程中,对象发生突发的平面位移,并注入合成的感知滞后。在0-10厘米的位移和0-400毫秒的滞后下,UAR-PF和ICP相对于无重定位的基线表现出良好的性能,以适度的末端执行器行程和更少的中止次数实现了更高的成功率;简单的操作安全措施进一步提高了稳定性。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,由于感知滞后(latency)、噪声和环境变化导致的目标不确定性问题。现有的方法,如直接控制或简单的视觉伺服,难以适应这种不确定性,导致操作失败或效率低下。特别是在动态环境中,目标位置的快速变化使得机器人需要不断调整其运动轨迹。
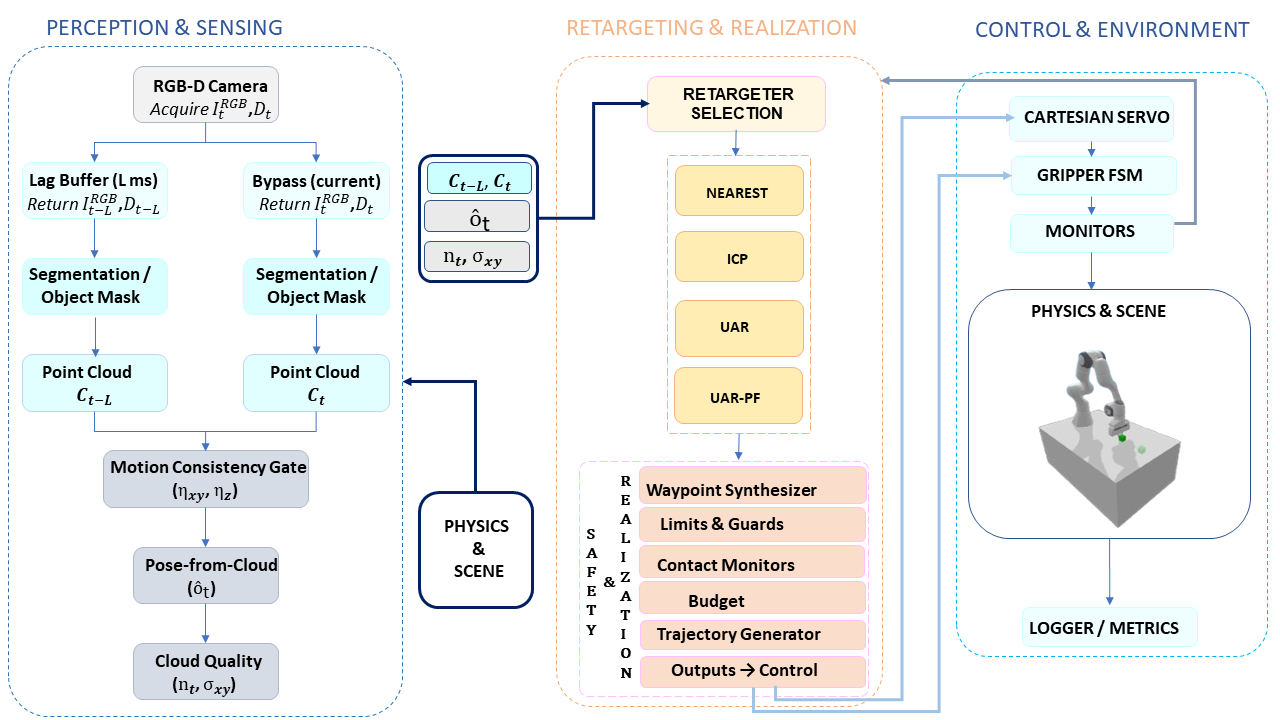
核心思路:论文的核心思路是将目标重定位作为一个独立的、可插拔的模块,位于感知和控制之间。这个模块负责根据最新的感知信息,动态地调整任务目标,从而补偿感知滞后和环境变化带来的影响。通过维护一个关于目标姿态的概率分布,并选择能够最大化预期进度的目标,U-LAG能够更有效地完成任务。
技术框架:U-LAG的整体框架包括三个主要部分:感知模块、UAR-PF重定位模块和底层控制器。感知模块负责获取环境信息,例如目标物体的位置和姿态。UAR-PF模块利用这些信息,结合感知滞后的估计,维护一个关于目标姿态的概率分布,并选择新的目标。底层控制器则负责执行运动指令,将末端执行器移动到新的目标位置。
关键创新:论文最关键的创新在于UAR-PF(Uncertainty-Aware Retargeting using Particle Filter)重定位器。UAR-PF使用粒子滤波来估计目标物体在感知滞后下的姿态分布,并根据这个分布选择能够最大化预期进度的目标。与传统的重定位方法相比,UAR-PF能够更好地处理感知不确定性,从而提高操作的鲁棒性和成功率。此外,可插拔的重定位接口也使得U-LAG可以方便地集成到不同的机器人系统中。
关键设计:UAR-PF的关键设计包括:1)使用粒子滤波来维护目标姿态的概率分布;2)设计一个奖励函数,用于评估不同目标位置的预期进度;3)使用优化算法(例如梯度下降)来选择能够最大化奖励函数的目标位置。此外,论文还提出了一些操作安全措施,例如限制末端执行器的最大速度和加速度,以防止碰撞和不稳定性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在存在0-10厘米的位移和0-400毫秒的感知滞后情况下,UAR-PF相对于没有重定位的基线,在抓取、推动、堆叠和插桩等任务中表现出更高的成功率,同时减少了末端执行器的行程和中止次数。与ICP等传统方法相比,UAR-PF在处理感知不确定性方面表现更佳,证明了其在动态环境下的有效性。
🎯 应用场景
U-LAG适用于各种需要在动态和不确定环境中进行操作的机器人应用,例如:自动驾驶车辆中的物体抓取、工业自动化中的装配任务、以及医疗机器人中的手术辅助。该方法可以提高机器人在复杂环境中的操作鲁棒性和效率,降低人为干预的需求,并为实现更智能、更自主的机器人系统奠定基础。
📄 摘要(原文)
Robots manipulating in changing environments must act on percepts that are late, noisy, or stale. We present U-LAG, a mid-execution goal-retargeting layer that leaves the low-level controller unchanged while re-aiming task goals (pre-contact, contact, post) as new observations arrive. Unlike motion retargeting or generic visual servoing, U-LAG treats in-flight goal re-aiming as a first-class, pluggable module between perception and control. Our main technical contribution is UAR-PF, an uncertainty-aware retargeter that maintains a distribution over object pose under sensing lag and selects goals that maximize expected progress. We instantiate a reproducible Shift x Lag stress test in PyBullet/PandaGym for pick, push, stacking, and peg insertion, where the object undergoes abrupt in-plane shifts while synthetic perception lag is injected during approach. Across 0-10 cm shifts and 0-400 ms lags, UAR-PF and ICP degrade gracefully relative to a no-retarget baseline, achieving higher success with modest end-effector travel and fewer aborts; simple operational safeguards further improve stability. Contributions: (1) UAR-PF for lag-adaptive, uncertainty-aware goal retargeting; (2) a pluggable retargeting interface; and (3) a reproducible Shift x Lag benchmark with evaluation on pick, push, stacking, and peg insertion.