ARMADA: Autonomous Online Failure Detection and Human Shared Control Empower Scalable Real-world Deployment and Adaptation
作者: Wenye Yu, Jun Lv, Zixi Ying, Yang Jin, Chuan Wen, Cewu Lu
分类: cs.RO
发布日期: 2025-10-02
💡 一句话要点
ARMADA:结合自主故障检测与人机共享控制,实现机器人部署与自适应
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人机协作 模仿学习 故障检测 机器人部署 自主学习
📋 核心要点
- 现有模仿学习方法在真实场景中部署时,面临领域数据不足、人工标注成本高昂以及需要全时人工监控等挑战。
- ARMADA系统通过FLOAT自主在线故障检测方法,实现并行策略部署,仅在必要时请求人工干预,降低对人工监督的依赖。
- 实验表明,ARMADA在真实世界任务中显著提升了成功率,降低了人工干预率,并超越了现有故障检测方法。
📝 摘要(中文)
模仿学习在从大规模真实世界数据中学习方面展现了潜力。然而,预训练策略通常在缺乏足够的领域内数据时表现不佳。此外,人工收集的演示数据需要大量劳动,并且往往包含混合质量的数据和冗余信息。作为一种解决方案,人机回路系统收集特定领域的数据用于策略后训练,并利用闭环策略反馈来提供信息丰富的指导,但通常需要在策略部署期间进行全时人工监控。在这项工作中,我们设计了ARMADA,一个具有人机回路共享控制的多机器人部署和自适应系统,其特点是一种名为FLOAT的自主在线故障检测方法。由于FLOAT,ARMADA能够并行策略部署,并且仅在必要时才请求人工干预,从而显著减少了对人工监督的依赖。因此,ARMADA能够有效获取领域内数据,并实现更可扩展的部署和更快地适应新场景。我们在四个真实世界的任务上评估了ARMADA的性能。FLOAT平均达到近95%的准确率,超过了先前最先进的故障检测方法20%以上。此外,与先前的人机回路学习方法相比,经过多轮策略部署和后训练,ARMADA的成功率提高了4倍以上,人工干预率降低了2倍以上。
🔬 方法详解
问题定义:论文旨在解决模仿学习策略在真实世界机器人部署中,因领域数据不足、人工标注成本高以及需要全时人工监控而导致的性能下降问题。现有方法要么依赖大量人工标注数据,要么需要人工持续监控策略执行过程,效率低下且成本高昂。
核心思路:论文的核心思路是利用自主在线故障检测方法(FLOAT)来减少对人工监督的依赖。FLOAT能够自动检测策略执行过程中的失败情况,并仅在必要时请求人工干预。通过这种方式,系统可以并行部署策略,并高效地收集领域内数据,从而加速策略的自适应过程。
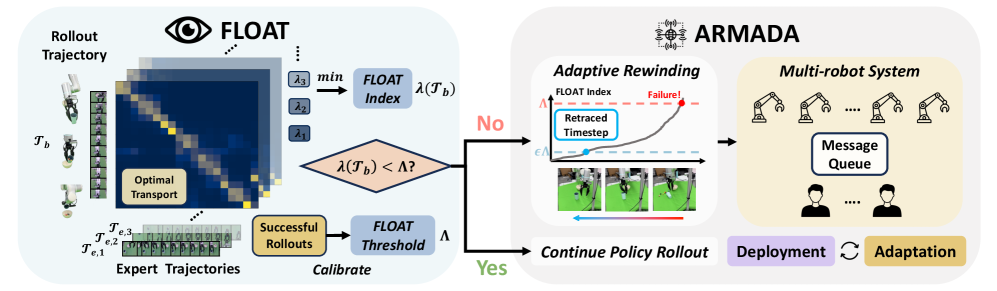
技术框架:ARMADA系统包含以下主要模块:1) 预训练的模仿学习策略;2) FLOAT自主在线故障检测模块;3) 人机共享控制界面;4) 策略后训练模块。系统首先使用预训练策略进行部署,FLOAT模块实时监测策略执行情况,当检测到潜在失败时,系统请求人工干预。人工干预数据用于策略后训练,提升策略在特定领域的性能。
关键创新:FLOAT自主在线故障检测模块是该论文的关键创新点。与现有故障检测方法相比,FLOAT能够更准确地识别策略执行过程中的失败情况,从而减少不必要的人工干预。FLOAT的具体实现细节未知,但摘要中提到其准确率超过现有方法20%以上。
关键设计:论文中没有详细描述FLOAT的具体设计细节,例如使用的特征、模型结构、损失函数等。人机共享控制界面的设计也未详细说明,但可以推测其需要提供清晰的策略执行状态信息,并允许人工方便地介入控制。
🖼️ 关键图片

📊 实验亮点
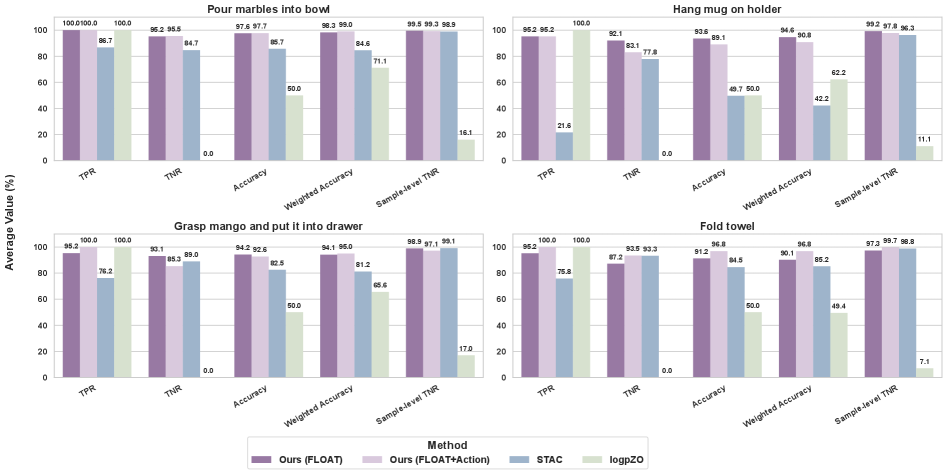
实验结果表明,FLOAT故障检测平均准确率达到近95%,超过现有技术20%以上。ARMADA系统在多轮策略部署和后训练后,成功率提升超过4倍,人工干预率降低超过2倍。这些数据表明,ARMADA在真实世界任务中具有显著的性能优势。
🎯 应用场景
该研究成果可广泛应用于各种需要机器人自主执行任务的场景,例如物流、仓储、家庭服务、农业等。通过减少对人工监督的依赖,可以显著降低部署和维护成本,提高机器人系统的可扩展性和适应性。未来,该技术有望推动机器人更广泛地应用于真实世界。
📄 摘要(原文)
Imitation learning has shown promise in learning from large-scale real-world datasets. However, pretrained policies usually perform poorly without sufficient in-domain data. Besides, human-collected demonstrations entail substantial labour and tend to encompass mixed-quality data and redundant information. As a workaround, human-in-the-loop systems gather domain-specific data for policy post-training, and exploit closed-loop policy feedback to offer informative guidance, but usually require full-time human surveillance during policy rollout. In this work, we devise ARMADA, a multi-robot deployment and adaptation system with human-in-the-loop shared control, featuring an autonomous online failure detection method named FLOAT. Thanks to FLOAT, ARMADA enables paralleled policy rollout and requests human intervention only when necessary, significantly reducing reliance on human supervision. Hence, ARMADA enables efficient acquisition of in-domain data, and leads to more scalable deployment and faster adaptation to new scenarios. We evaluate the performance of ARMADA on four real-world tasks. FLOAT achieves nearly 95% accuracy on average, surpassing prior state-of-the-art failure detection approaches by over 20%. Besides, ARMADA manifests more than 4$\times$ increase in success rate and greater than 2$\times$ reduction in human intervention rate over multiple rounds of policy rollout and post-training, compared to previous human-in-the-loop learning methods.