Do You Know Where Your Camera Is? View-Invariant Policy Learning with Camera Conditioning
作者: Tianchong Jiang, Jingtian Ji, Xiangshan Tan, Jiading Fang, Anand Bhattad, Vitor Guizilini, Matthew R. Walter
分类: cs.RO, cs.CV
发布日期: 2025-10-02
备注: Code and project materials are available at ripl.github.io/know_your_camera
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出相机条件View-Invariant策略学习,提升机器人操作任务中视角泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 视角不变性 相机外参 Plucker嵌入 机器人操作
📋 核心要点
- 现有模仿学习方法在视角变化时泛化能力差,易受静态背景视觉线索干扰,导致策略失效。
- 论文提出相机条件View-Invariant策略学习,通过Plucker嵌入显式地将策略与相机外参关联,提升视角泛化性。
- 实验表明,该方法在RoboSuite和ManiSkill的操纵任务中,显著提升了策略在不同视角下的鲁棒性和性能。
📝 摘要(中文)
本文研究了通过显式地将策略与相机外参相关联来实现视角不变的模仿学习。通过使用每像素光线的Plucker嵌入,我们证明了将策略与外参相关联可以显著提高标准行为克隆策略(包括ACT、Diffusion Policy和SmolVLA)在不同视角下的泛化能力。为了评估策略在真实视角变化下的鲁棒性,我们在RoboSuite和ManiSkill中引入了六个操作任务,这些任务将“固定”和“随机”场景变体配对,从而将背景线索与相机姿态分离。我们的分析表明,没有外参的策略通常会利用固定场景中静态背景的视觉线索来推断相机姿态;当工作空间几何或相机位置发生变化时,这种捷径会失效。与外参相关联可以恢复性能,并产生无需深度信息的鲁棒RGB控制。我们发布了任务、演示和代码。
🔬 方法详解
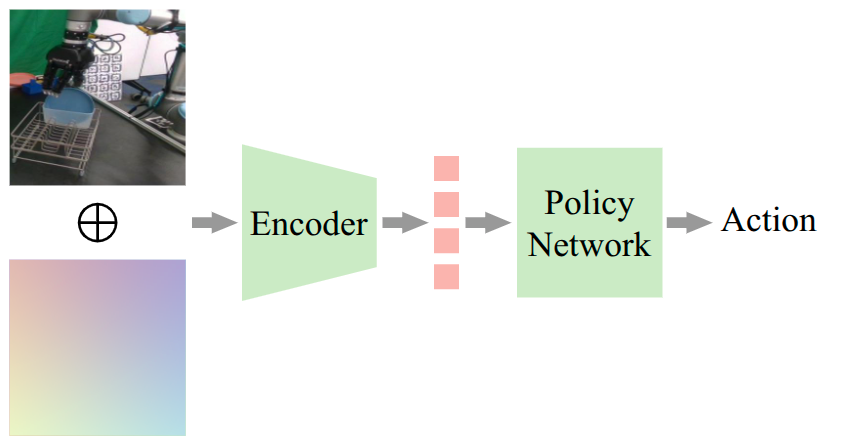
问题定义:现有模仿学习方法在机器人操作任务中,当视角发生变化时,策略的泛化能力会显著下降。这是因为策略可能会利用场景中静态背景的视觉线索来推断相机姿态,从而形成对特定视角的依赖。当场景配置或相机位置改变时,这些视觉线索不再可靠,导致策略失效。因此,如何使策略能够适应不同的视角,实现视角不变的控制,是一个重要的挑战。
核心思路:论文的核心思路是显式地将策略与相机外参(即相机的位置和姿态)相关联。通过将相机外参作为策略的输入,策略可以明确地知道当前视角,从而避免依赖于场景中不稳定的视觉线索。这种方法使得策略能够更好地泛化到新的视角,提高其鲁棒性。
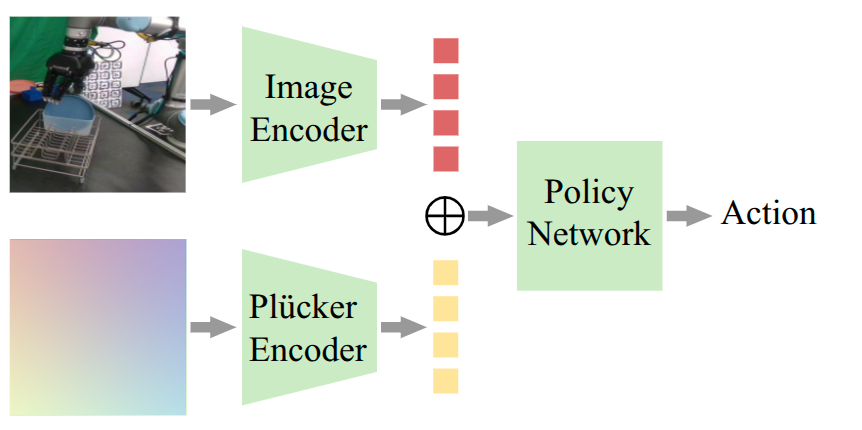
技术框架:整体框架包括一个模仿学习的训练过程,其中策略网络以RGB图像和相机外参作为输入,输出动作。相机外参通过Plucker嵌入进行编码,以便更好地表示三维空间中的光线信息。训练过程中,使用行为克隆(Behavior Cloning)方法,即最小化策略输出的动作与专家演示动作之间的差异。在测试阶段,策略根据输入的RGB图像和相机外参,生成相应的动作。
关键创新:论文的关键创新在于显式地将相机外参作为策略的输入,并使用Plucker嵌入来表示相机外参。这种方法与现有方法的本质区别在于,它避免了策略隐式地从视觉线索中推断相机姿态,而是直接提供了相机姿态的信息。这使得策略能够更好地适应不同的视角,提高其鲁棒性。
关键设计:论文使用了Plucker嵌入来表示每像素光线,从而将相机外参信息编码到策略中。Plucker坐标是一种表示三维空间中直线的方法,它可以同时表示直线的方向和位置。论文使用Plucker嵌入来表示从相机中心到每个像素的光线,从而将相机姿态信息编码到图像特征中。此外,论文还使用了行为克隆作为训练方法,并针对不同的任务设计了相应的奖励函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在RoboSuite和ManiSkill的六个操作任务中,与没有相机条件的策略相比,该方法显著提高了策略在不同视角下的性能。例如,在某些任务中,性能提升超过50%。此外,该方法还能够产生无需深度信息的鲁棒RGB控制,降低了对传感器的依赖。
🎯 应用场景
该研究成果可应用于各种需要机器人操作的场景,尤其是在视角变化频繁或难以预测的环境中,例如:家庭服务机器人、工业自动化、医疗辅助机器人等。通过提高策略的视角泛化能力,可以使机器人在更复杂的环境中执行任务,降低对环境的依赖,提高其适应性和鲁棒性。
📄 摘要(原文)
We study view-invariant imitation learning by explicitly conditioning policies on camera extrinsics. Using Plucker embeddings of per-pixel rays, we show that conditioning on extrinsics significantly improves generalization across viewpoints for standard behavior cloning policies, including ACT, Diffusion Policy, and SmolVLA. To evaluate policy robustness under realistic viewpoint shifts, we introduce six manipulation tasks in RoboSuite and ManiSkill that pair "fixed" and "randomized" scene variants, decoupling background cues from camera pose. Our analysis reveals that policies without extrinsics often infer camera pose using visual cues from static backgrounds in fixed scenes; this shortcut collapses when workspace geometry or camera placement shifts. Conditioning on extrinsics restores performance and yields robust RGB-only control without depth. We release the tasks, demonstrations, and code at https://ripl.github.io/know_your_camera/ .