Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
作者: Joao Pedro Araujo, Yanjie Ze, Pei Xu, Jiajun Wu, C. Karen Liu
分类: cs.RO
发布日期: 2025-10-02
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
提出通用运动重定向(GMR)方法,提升人型机器人运动跟踪策略的鲁棒性和真实性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 运动重定向 人型机器人 运动跟踪 强化学习 形态差异
📋 核心要点
- 现有运动重定向方法在人型机器人运动跟踪中存在伪影,导致策略鲁棒性下降,需要大量奖励工程。
- 提出通用运动重定向(GMR)方法,旨在减少重定向过程中的伪影,提升运动跟踪策略的性能和真实性。
- 实验表明,GMR在跟踪性能和运动保真度上优于现有开源方法,接近闭源基线,提升了策略鲁棒性。
📝 摘要(中文)
人型机器人运动跟踪策略对于构建遥操作流程和分层控制器至关重要,但面临着人与机器人之间的形态差异这一根本挑战。现有方法通过将人类运动数据重定向到人型机器人身上,然后训练强化学习(RL)策略来模仿这些参考轨迹来解决这一问题。然而,重定向过程中引入的伪影,如脚部滑动、自穿透和物理上不可行的运动,通常会遗留在参考轨迹中,需要RL策略进行纠正。虽然之前的工作已经展示了运动跟踪能力,但它们通常需要大量的奖励工程和领域随机化才能成功。本文系统地评估了在抑制过度奖励调整的情况下,重定向质量如何影响策略性能。为了解决现有重定向方法中发现的问题,我们提出了一种新的重定向方法,即通用运动重定向(GMR)。我们将GMR与两个开源重定向器PHC和ProtoMotions,以及来自宇树科技的高质量闭源数据集一起评估。使用BeyondMimic进行策略训练,我们分离了重定向效果,而无需奖励调整。我们在LAFAN1数据集的一个多样化子集上的实验表明,虽然大多数运动都可以被跟踪,但重定向数据中的伪影会显著降低策略的鲁棒性,特别是对于动态或长序列。GMR在跟踪性能和对源运动的忠实度方面始终优于现有的开源方法,实现了接近闭源基线的感知保真度和策略成功率。
🔬 方法详解
问题定义:论文旨在解决人型机器人运动跟踪中,由于人类运动数据重定向到机器人时产生的伪影(如脚部滑动、自穿透等)导致强化学习策略训练困难,鲁棒性差的问题。现有方法通常依赖大量的奖励工程和领域随机化来弥补重定向质量的不足,缺乏对重定向本身质量的关注。
核心思路:论文的核心思路是通过改进运动重定向算法,减少重定向过程中产生的伪影,从而为强化学习策略提供更干净、更真实的参考轨迹。这样可以降低对奖励工程的依赖,提升策略的泛化能力和鲁棒性。
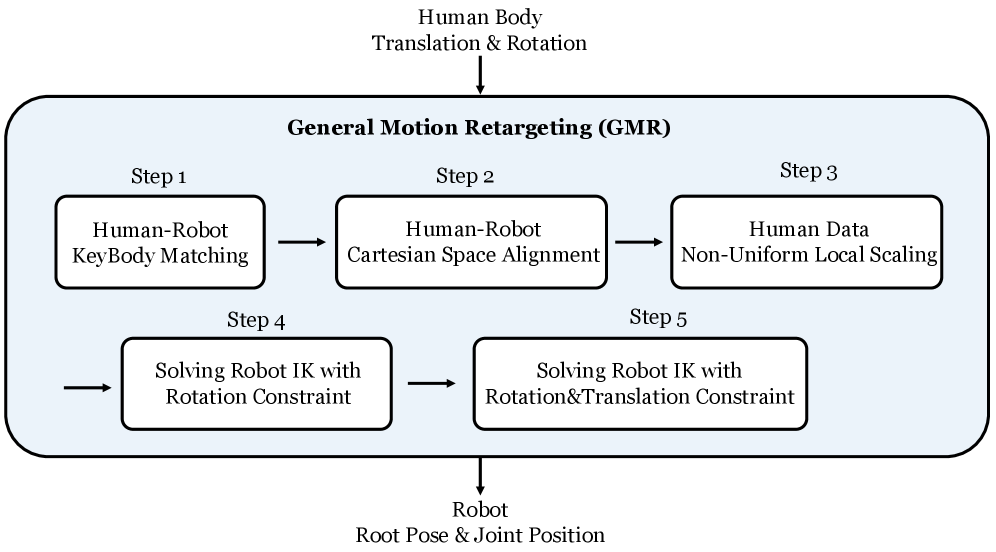
技术框架:整体框架包括三个主要步骤:1)使用不同重定向方法(GMR、PHC、ProtoMotions、Unitree闭源数据)将人类运动数据重定向到人型机器人;2)使用BeyondMimic算法训练强化学习策略,模仿重定向后的运动轨迹;3)评估策略的跟踪性能和运动保真度。通过对比不同重定向方法下的策略表现,评估重定向质量对最终性能的影响。
关键创新:论文的关键创新在于提出了通用运动重定向(GMR)方法,该方法旨在减少重定向过程中的伪影,提高运动的物理可行性和真实性。与现有方法相比,GMR更注重保持原始运动的特征,同时避免产生不自然的姿势和运动。
关键设计:具体的GMR算法细节未在摘要中详细描述,但可以推测其关键设计可能包括:1)优化目标函数,同时考虑运动保真度、物理可行性和关节限制;2)使用更精细的运动学模型,更好地处理人与机器人之间的形态差异;3)采用后处理技术,进一步消除重定向后的伪影,例如使用运动平滑算法或碰撞检测与避免算法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GMR方法在LAFAN1数据集上,相较于开源方法PHC和ProtoMotions,在运动跟踪性能和对原始运动的保真度上均有显著提升,接近闭源数据集Unitree的表现。这表明高质量的运动重定向能够显著提升强化学习策略的鲁棒性和泛化能力,减少对人工调整的依赖。
🎯 应用场景
该研究成果可应用于机器人遥操作、虚拟现实、游戏动画等领域。通过高质量的运动重定向,可以让人型机器人更自然、更流畅地模仿人类的动作,提升人机交互的体验和效率。未来,该技术有望应用于远程医疗、危险环境作业等场景,实现更安全、更高效的人机协作。
📄 摘要(原文)
Humanoid motion tracking policies are central to building teleoperation pipelines and hierarchical controllers, yet they face a fundamental challenge: the embodiment gap between humans and humanoid robots. Current approaches address this gap by retargeting human motion data to humanoid embodiments and then training reinforcement learning (RL) policies to imitate these reference trajectories. However, artifacts introduced during retargeting, such as foot sliding, self-penetration, and physically infeasible motion are often left in the reference trajectories for the RL policy to correct. While prior work has demonstrated motion tracking abilities, they often require extensive reward engineering and domain randomization to succeed. In this paper, we systematically evaluate how retargeting quality affects policy performance when excessive reward tuning is suppressed. To address issues that we identify with existing retargeting methods, we propose a new retargeting method, General Motion Retargeting (GMR). We evaluate GMR alongside two open-source retargeters, PHC and ProtoMotions, as well as with a high-quality closed-source dataset from Unitree. Using BeyondMimic for policy training, we isolate retargeting effects without reward tuning. Our experiments on a diverse subset of the LAFAN1 dataset reveal that while most motions can be tracked, artifacts in retargeted data significantly reduce policy robustness, particularly for dynamic or long sequences. GMR consistently outperforms existing open-source methods in both tracking performance and faithfulness to the source motion, achieving perceptual fidelity and policy success rates close to the closed-source baseline. Website: https://jaraujo98.github.io/retargeting_matters. Code: https://github.com/YanjieZe/GMR.