Contrastive Representation Regularization for Vision-Language-Action Models
作者: Taeyoung Kim, Jimin Lee, Myungkyu Koo, Dongyoung Kim, Kyungmin Lee, Changyeon Kim, Younggyo Seo, Jinwoo Shin
分类: cs.RO, cs.LG
发布日期: 2025-10-02 (更新: 2025-10-13)
备注: 20 pages, 12 figures
💡 一句话要点
提出RS-CL对比学习方法,提升视觉-语言-动作模型在机器人操作任务中的性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 对比学习 表征学习 本体感受状态
📋 核心要点
- 现有VLA模型在机器人操作中表现出潜力,但其表征对控制动作和本体感受等机器人信号的敏感性不足。
- 论文提出机器人状态感知对比损失(RS-CL),通过对比学习使VLA模型的表征与机器人的本体感受状态对齐。
- 实验结果表明,RS-CL显著提升了VLA模型在模拟和真实机器人操作任务中的性能,例如抓取放置任务。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通过利用预训练的视觉-语言模型(VLM)的丰富表征,在机器人操作方面展现了能力。然而,它们的表征可能仍然不是最优的,缺乏对机器人信号(如控制动作和本体感受状态)的敏感性。为了解决这个问题,我们引入了机器人状态感知对比损失(RS-CL),这是一种简单而有效的VLA模型表征正则化方法,旨在弥合VLM表征和机器人信号之间的差距。特别地,RS-CL通过使用状态之间的相对距离作为软监督,使表征更紧密地与机器人的本体感受状态对齐。作为原始动作预测目标的补充,RS-CL有效地增强了控制相关的表征学习,同时保持轻量级并与标准VLA训练流程完全兼容。我们的实验结果表明,RS-CL显著提高了最先进的VLA模型的操作性能;在RoboCasa-Kitchen的抓取和放置任务中,通过更精确的抓取和放置定位,将现有技术水平从30.8%提高到41.5%,并在具有挑战性的真实机器人操作任务中,将成功率从45.0%提高到58.3%。
🔬 方法详解
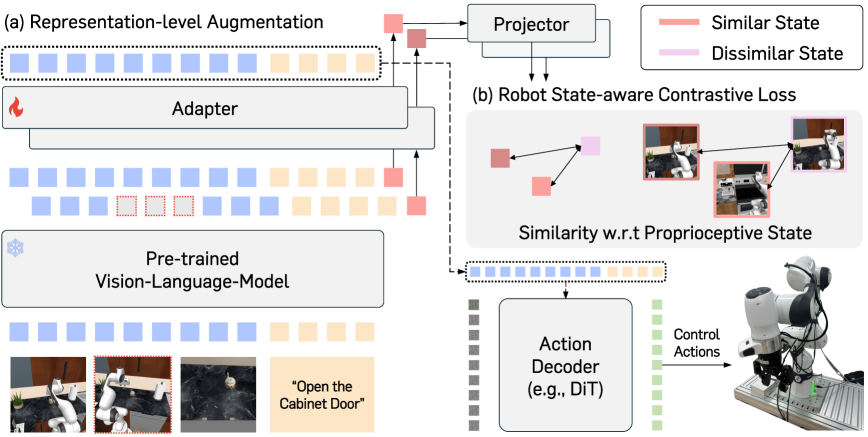
问题定义:现有的视觉-语言-动作(VLA)模型虽然能够利用预训练的视觉-语言模型(VLM)的强大表征能力,但在机器人操作任务中,其表征对于机器人自身的状态信息(如关节角度、末端执行器位置等本体感受状态)和控制动作的敏感性不足。这导致模型在复杂操作任务中难以进行精确的控制和规划,限制了其性能的进一步提升。
核心思路:论文的核心思路是通过对比学习的方式,将VLA模型的表征空间与机器人的本体感受状态空间对齐。具体来说,就是让相似的机器人状态在表征空间中也更加接近,而不同的状态在表征空间中尽可能远离。这样,VLA模型就能更好地理解和利用机器人自身的状态信息,从而提高控制精度和操作成功率。
技术框架:该方法在标准的VLA训练流程中增加了一个额外的对比学习损失项。整体框架包括:1) 使用VLM提取视觉和语言特征;2) 将视觉、语言和机器人状态信息输入到VLA模型中,得到动作预测;3) 使用RS-CL对比损失,将VLA模型的表征与机器人本体感受状态对齐;4) 结合动作预测损失和对比损失,共同优化VLA模型。
关键创新:该论文的关键创新在于提出了机器人状态感知对比损失(RS-CL)。与传统的对比学习方法不同,RS-CL不仅仅是简单地将相似的样本拉近,而是利用机器人状态之间的相对距离作为软监督信号。也就是说,如果两个机器人状态在物理空间中距离较近,那么它们在表征空间中也应该更接近;反之,如果两个状态距离较远,那么它们在表征空间中也应该更远离。这种相对距离的约束能够更有效地学习到控制相关的表征。
关键设计:RS-CL的关键设计包括:1) 使用机器人本体感受状态之间的欧氏距离作为相似度度量;2) 使用InfoNCE损失函数来构建对比学习目标;3) 将对比损失与原始的动作预测损失进行加权求和,共同优化VLA模型。具体的权重系数需要根据实验进行调整,以平衡动作预测和状态对齐之间的关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RS-CL显著提高了VLA模型在机器人操作任务中的性能。在RoboCasa-Kitchen的抓取和放置任务中,成功率从30.8%提升到41.5%。在真实机器人操作任务中,成功率从45.0%提升到58.3%。这些结果表明,RS-CL能够有效地增强控制相关的表征学习,提高机器人的操作能力。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过提升机器人对自身状态的感知能力和控制精度,可以实现更复杂、更精细的操作,提高生产效率和服务质量。未来,该方法有望与其他先进技术(如强化学习、模仿学习)相结合,进一步提升机器人的智能化水平。
📄 摘要(原文)
Vision-Language-Action (VLA) models have shown its capabilities in robot manipulation by leveraging rich representations from pre-trained Vision-Language Models (VLMs). However, their representations arguably remain suboptimal, lacking sensitivity to robotic signals such as control actions and proprioceptive states. To address the issue, we introduce Robot State-aware Contrastive Loss (RS-CL), a simple and effective representation regularization for VLA models, designed to bridge the gap between VLM representations and robotic signals. In particular, RS-CL aligns the representations more closely with the robot's proprioceptive states, by using relative distances between the states as soft supervision. Complementing the original action prediction objective, RS-CL effectively enhances control-relevant representation learning, while being lightweight and fully compatible with standard VLA training pipeline. Our empirical results demonstrate that RS-CL substantially improves the manipulation performance of state-of-the-art VLA models; it pushes the prior art from 30.8% to 41.5% on pick-and-place tasks in RoboCasa-Kitchen, through more accurate positioning during grasping and placing, and boosts success rates from 45.0% to 58.3% on challenging real-robot manipulation tasks.