AFFORD2ACT: Affordance-Guided Automatic Keypoint Selection for Generalizable and Lightweight Robotic Manipulation
作者: Anukriti Singh, Kasra Torshizi, Khuzema Habib, Kelin Yu, Ruohan Gao, Pratap Tokekar
分类: cs.RO, cs.AI
发布日期: 2025-10-01
💡 一句话要点
AFFORD2ACT:基于可供性的机器人操作关键点自动选择框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 可供性 关键点选择 Transformer网络 策略学习
📋 核心要点
- 基于视觉的机器人学习依赖密集图像或点云输入,计算量大且易受无关背景特征干扰。
- AFFORD2ACT利用可供性引导,从文本提示和图像中提取少量语义关键点,实现轻量级操作策略。
- 实验表明,AFFORD2ACT在多种真实操作任务中表现出高数据效率和泛化能力,成功率达82%。
📝 摘要(中文)
本文提出AFFORD2ACT,一个基于可供性的框架,用于从文本提示和单张图像中提取最少的语义2D关键点,用于机器人操作。AFFORD2ACT包含三个阶段:可供性过滤、类别级关键点构建和基于Transformer的策略学习,其中嵌入了门控机制以推断最相关的关键点。该方法生成一个紧凑的38维状态策略,可在15分钟内完成训练,并在没有本体感受或密集表示的情况下实时运行。在各种真实操作任务中,AFFORD2ACT持续提高数据效率,在未见过的物体、新类别、背景和干扰物上实现了82%的成功率。
🔬 方法详解
问题定义:现有基于视觉的机器人操作方法通常依赖于密集的图像或点云输入,这导致计算成本高昂,并且容易受到不相关的背景特征的干扰。虽然基于关键点的方法可以关注操作相关的特征并实现轻量化,但它们通常依赖于手动启发式方法或任务耦合的选择,限制了其可扩展性和语义理解能力。
核心思路:AFFORD2ACT的核心思路是利用可供性(affordance)作为指导,自动地从图像中选择与操作任务相关的关键点。通过文本提示来定义操作任务,并利用可供性信息来过滤和选择关键点,从而减少了需要处理的数据量,并提高了策略学习的效率和泛化能力。
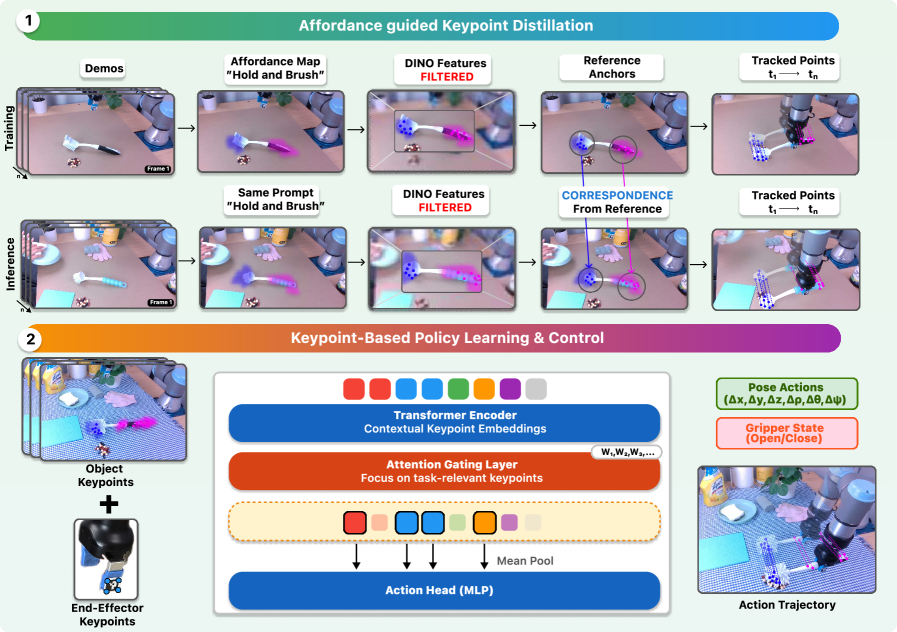
技术框架:AFFORD2ACT框架包含三个主要阶段:1) 可供性过滤:利用文本提示和图像信息,过滤掉与操作任务无关的关键点。2) 类别级关键点构建:基于过滤后的可供性信息,构建类别级别的关键点表示。3) 基于Transformer的策略学习:使用Transformer网络学习操作策略,并嵌入门控机制来推断最相关的关键点。
关键创新:AFFORD2ACT的关键创新在于其利用可供性信息来自动选择关键点,从而避免了手动设计或任务耦合的选择过程。此外,该框架还采用了Transformer网络和门控机制,以提高策略学习的效率和泛化能力。这种方法能够生成一个紧凑的38维状态策略,可以在短时间内完成训练,并在真实环境中实时运行。
关键设计:AFFORD2ACT的关键设计包括:1) 使用文本提示来定义操作任务,并利用预训练的语言模型来提取可供性信息。2) 使用卷积神经网络(CNN)来提取图像特征,并将图像特征与可供性信息融合,以过滤和选择关键点。3) 使用Transformer网络来学习操作策略,并使用门控机制来动态地选择最相关的关键点。4) 损失函数的设计旨在鼓励策略学习的稳定性和泛化能力。
🖼️ 关键图片


📊 实验亮点
AFFORD2ACT在各种真实操作任务中表现出卓越的性能。实验结果表明,该方法在未见过的物体、新类别、背景和干扰物上实现了82%的成功率,并且能够在15分钟内完成策略训练。与传统的基于密集表示的方法相比,AFFORD2ACT显著提高了数据效率和泛化能力,同时降低了计算成本。
🎯 应用场景
AFFORD2ACT可应用于各种机器人操作任务,例如物体抓取、放置、组装等。该方法能够提高机器人操作的效率、鲁棒性和泛化能力,使其能够适应不同的环境和物体。此外,AFFORD2ACT还可以用于开发更智能、更自主的机器人系统,从而在工业自动化、医疗保健、家庭服务等领域发挥重要作用。
📄 摘要(原文)
Vision-based robot learning often relies on dense image or point-cloud inputs, which are computationally heavy and entangle irrelevant background features. Existing keypoint-based approaches can focus on manipulation-centric features and be lightweight, but either depend on manual heuristics or task-coupled selection, limiting scalability and semantic understanding. To address this, we propose AFFORD2ACT, an affordance-guided framework that distills a minimal set of semantic 2D keypoints from a text prompt and a single image. AFFORD2ACT follows a three-stage pipeline: affordance filtering, category-level keypoint construction, and transformer-based policy learning with embedded gating to reason about the most relevant keypoints, yielding a compact 38-dimensional state policy that can be trained in 15 minutes, which performs well in real-time without proprioception or dense representations. Across diverse real-world manipulation tasks, AFFORD2ACT consistently improves data efficiency, achieving an 82% success rate on unseen objects, novel categories, backgrounds, and distractors.