How Well do Diffusion Policies Learn Kinematic Constraint Manifolds?
作者: Lexi Foland, Thomas Cohn, Adam Wei, Nicholas Pfaff, Boyuan Chen, Russ Tedrake
分类: cs.RO
发布日期: 2025-10-01
备注: Under review. 8 pages, 3 figures, 3 tables. Additional results available at https://diffusion-learns-kinematic.github.io
💡 一句话要点
研究扩散策略学习运动学约束流形的能力,揭示数据集质量和大小的影响。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散策略 机器人学习 运动学约束 流形学习 模仿学习 数据集质量 数据集大小
📋 核心要点
- 现有扩散策略在机器人模仿学习中表现出色,但其对运动学约束流形的学习能力缺乏深入分析。
- 本研究通过双手抓取放置任务,分析数据集大小、质量和流形曲率对扩散策略学习约束流形的影响。
- 实验表明,扩散策略能粗略学习约束流形,数据集大小和质量下降会负面影响学习效果,硬件实验验证了结果的实际应用性。
📝 摘要(中文)
扩散策略在机器人模仿学习中表现出令人印象深刻的结果,即使对于需要满足运动学等式约束的任务也是如此。然而,仅凭任务性能并不能可靠地表明策略精确学习训练数据中约束的能力。为了研究这一点,我们通过一个双手抓取放置任务的案例研究,分析了扩散策略如何发现这些流形,该任务鼓励满足运动学约束以获得成功。我们研究了三个因素如何影响训练后的策略:数据集大小、数据集质量和流形曲率。我们的实验表明,扩散策略学习了约束流形的粗略近似,学习受到数据集大小和质量下降的负面影响。另一方面,约束流形的曲率与约束满足和任务成功之间没有明确的相关性。硬件评估验证了我们的结果在现实世界中的适用性。项目网站包含更多结果和可视化效果:https://diffusion-learns-kinematic.github.io
🔬 方法详解
问题定义:论文旨在研究扩散策略在机器人模仿学习中,学习和满足运动学约束流形的能力。现有方法虽然在任务性能上表现良好,但缺乏对策略如何精确学习和表示这些约束的深入理解,尤其是在数据质量和数量受限的情况下。这可能导致策略在实际应用中无法可靠地满足约束条件。
核心思路:论文的核心思路是通过控制数据集的质量、大小以及约束流形的曲率,来系统地分析这些因素对扩散策略学习约束流形的影响。通过观察策略在不同条件下的表现,揭示扩散策略学习约束流形的内在机制和局限性。
技术框架:论文采用了一个双手抓取放置任务作为案例研究。整体流程包括:1) 生成不同质量和大小的训练数据集,这些数据集包含满足运动学约束的机器人运动轨迹;2) 使用扩散策略在这些数据集上进行训练;3) 评估训练后的策略在约束满足程度和任务成功率方面的表现;4) 分析数据集特征(如流形曲率)与策略性能之间的关系;5) 在真实机器人硬件上验证实验结果。
关键创新:论文的关键创新在于其系统性地研究了数据集特征(大小、质量、流形曲率)对扩散策略学习运动学约束流形的影响。以往的研究主要关注任务性能,而忽略了对约束流形学习本身的分析。本研究填补了这一空白,为理解和改进扩散策略在机器人控制中的应用提供了新的视角。
关键设计:论文的关键设计包括:1) 精心设计的双手抓取放置任务,该任务需要满足特定的运动学约束才能成功;2) 通过控制数据生成过程,创建不同质量和大小的数据集;3) 使用合适的指标来量化约束满足程度和任务成功率;4) 采用统计方法分析数据集特征与策略性能之间的相关性。具体的扩散策略网络结构和损失函数细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片

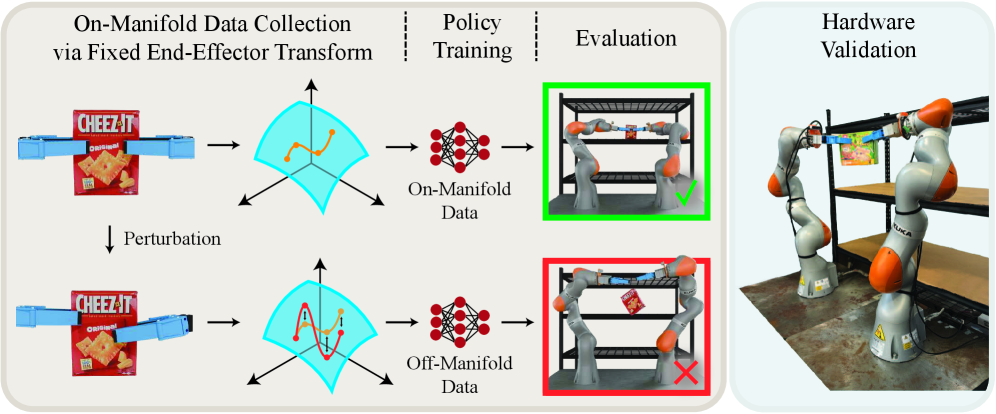
📊 实验亮点
实验结果表明,扩散策略能够学习约束流形的粗略近似,但数据集大小和质量的下降会对学习产生负面影响。约束流形的曲率与约束满足和任务成功之间没有明确的相关性。硬件实验验证了这些发现的实际意义,表明在真实机器人系统中,数据质量和数量仍然是影响扩散策略性能的关键因素。
🎯 应用场景
该研究成果可应用于各种需要精确运动控制和约束满足的机器人任务,例如装配、操作和医疗机器人。通过理解数据集特征对扩散策略学习约束流形的影响,可以更好地设计训练数据,提高策略的泛化能力和鲁棒性,从而推动机器人技术在复杂环境中的应用。
📄 摘要(原文)
Diffusion policies have shown impressive results in robot imitation learning, even for tasks that require satisfaction of kinematic equality constraints. However, task performance alone is not a reliable indicator of the policy's ability to precisely learn constraints in the training data. To investigate, we analyze how well diffusion policies discover these manifolds with a case study on a bimanual pick-and-place task that encourages fulfillment of a kinematic constraint for success. We study how three factors affect trained policies: dataset size, dataset quality, and manifold curvature. Our experiments show diffusion policies learn a coarse approximation of the constraint manifold with learning affected negatively by decreases in both dataset size and quality. On the other hand, the curvature of the constraint manifold showed inconclusive correlations with both constraint satisfaction and task success. A hardware evaluation verifies the applicability of our results in the real world. Project website with additional results and visuals: https://diffusion-learns-kinematic.github.io