Compose Your Policies! Improving Diffusion-based or Flow-based Robot Policies via Test-time Distribution-level Composition
作者: Jiahang Cao, Yize Huang, Hanzhong Guo, Rui Zhang, Mu Nan, Weijian Mai, Jiaxu Wang, Hao Cheng, Jingkai Sun, Gang Han, Wen Zhao, Qiang Zhang, Yijie Guo, Qihao Zheng, Chunfeng Song, Xiao Li, Ping Luo, Andrew F. Luo
分类: cs.RO, cs.LG
发布日期: 2025-10-01
备注: Project Page: https://sagecao1125.github.io/GPC-Site/
💡 一句话要点
提出通用策略组合(GPC),无需额外训练即可提升扩散或Flow模型机器人策略性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 扩散模型 策略组合 免训练 强化学习
📋 核心要点
- 现有基于扩散模型的机器人控制策略受限于大规模交互数据集的高昂获取成本,难以进一步提升性能。
- 论文提出通用策略组合(GPC)方法,通过组合多个预训练策略的分布得分,无需额外训练即可提升性能。
- 在多个基准测试和真实机器人实验中,GPC均显著提升了性能和适应性,验证了其有效性。
📝 摘要(中文)
基于扩散模型的机器人控制,包括视觉-语言-动作(VLA)和视觉-动作(VA)策略,已经展示了显著的能力。然而,它们的发展受到获取大规模交互数据集的高成本限制。本文介绍了一种无需额外模型训练即可提高策略性能的替代范例。令人惊讶的是,我们证明了组合策略可以超过任何一个父策略的性能。我们的贡献有三方面。首先,我们建立了一个理论基础,表明多个扩散模型的分布得分的凸组合可以产生比任何单个得分更好的单步函数目标。然后使用Grönwall型界限来表明,这种单步改进会传播到整个生成轨迹,从而带来系统性的性能提升。其次,受这些结果的启发,我们提出了通用策略组合(GPC),这是一种无需训练的方法,通过凸组合和测试时搜索来组合多个预训练策略的分布得分,从而提高性能。GPC是通用的,允许即插即用地组合异构策略,包括VA和VLA模型,以及基于扩散或Flow-matching的模型,而不管它们的输入视觉模态如何。第三,我们提供了广泛的实验验证。在Robomimic、PushT和RoboTwin基准测试以及真实世界机器人评估中的实验证实,GPC始终如一地提高了各种任务的性能和适应性。对替代组合算子和加权策略的进一步分析提供了对GPC成功机制的见解。这些结果将GPC确立为一种简单而有效的方法,通过利用现有策略来提高控制性能。
🔬 方法详解
问题定义:现有基于扩散模型的机器人控制策略,如VLA和VA策略,依赖于大量交互数据进行训练,数据获取成本高昂,限制了策略性能的进一步提升。如何有效利用已有的预训练策略,在不进行额外训练的情况下,提升机器人控制性能,是本文要解决的核心问题。
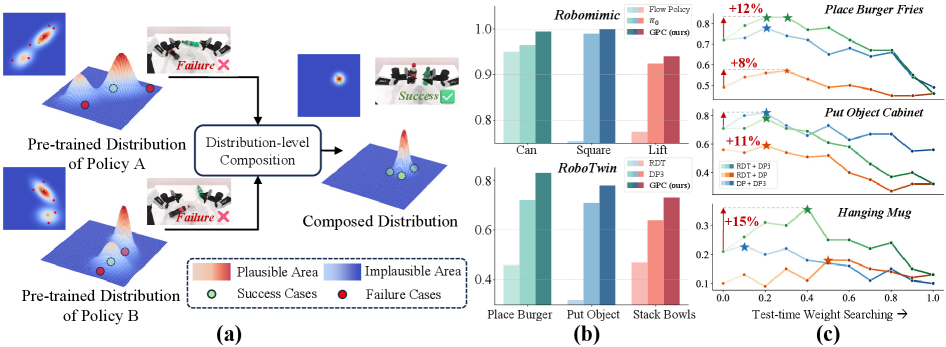
核心思路:论文的核心思路是通过组合多个预训练策略的分布得分,利用凸组合的优势,获得比单个策略更优的性能。理论上证明了分布得分的凸组合可以产生更好的单步函数目标,并且这种改进可以传播到整个轨迹。
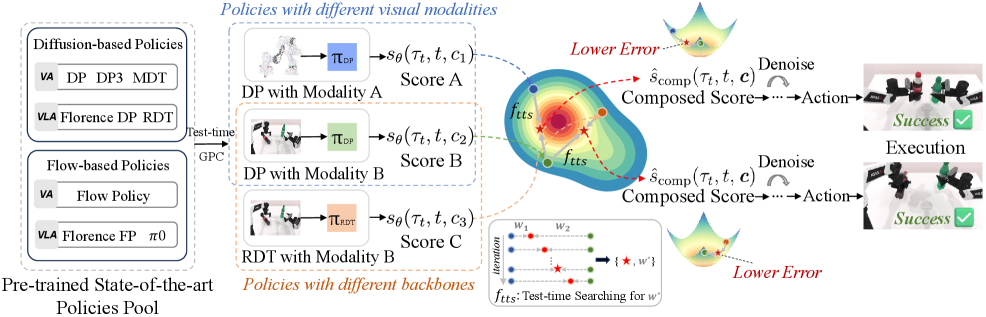
技术框架:GPC方法主要包含以下几个阶段:1) 收集多个预训练的机器人控制策略,这些策略可以是VA或VLA模型,也可以基于扩散模型或Flow-matching;2) 在测试时,对于给定的状态,每个策略生成一个动作分布;3) 使用凸组合的方式,将这些动作分布的得分进行组合,得到最终的动作分布;4) 通过搜索策略,找到最优的组合权重,从而最大化性能。
关键创新:GPC的关键创新在于提出了一种无需训练的策略组合方法,通过利用多个预训练策略的互补信息,提升整体性能。与现有方法相比,GPC不需要额外的训练数据或计算资源,可以直接应用于已有的策略,具有很强的通用性和易用性。此外,论文还从理论上证明了凸组合的有效性。
关键设计:GPC的关键设计包括:1) 使用凸组合来组合不同策略的分布得分,保证组合后的分布仍然是一个有效的概率分布;2) 使用测试时搜索来寻找最优的组合权重,例如可以使用网格搜索或优化算法;3) GPC可以灵活地组合不同类型的策略,例如VA和VLA策略,以及基于不同模型的策略。
🖼️ 关键图片
📊 实验亮点
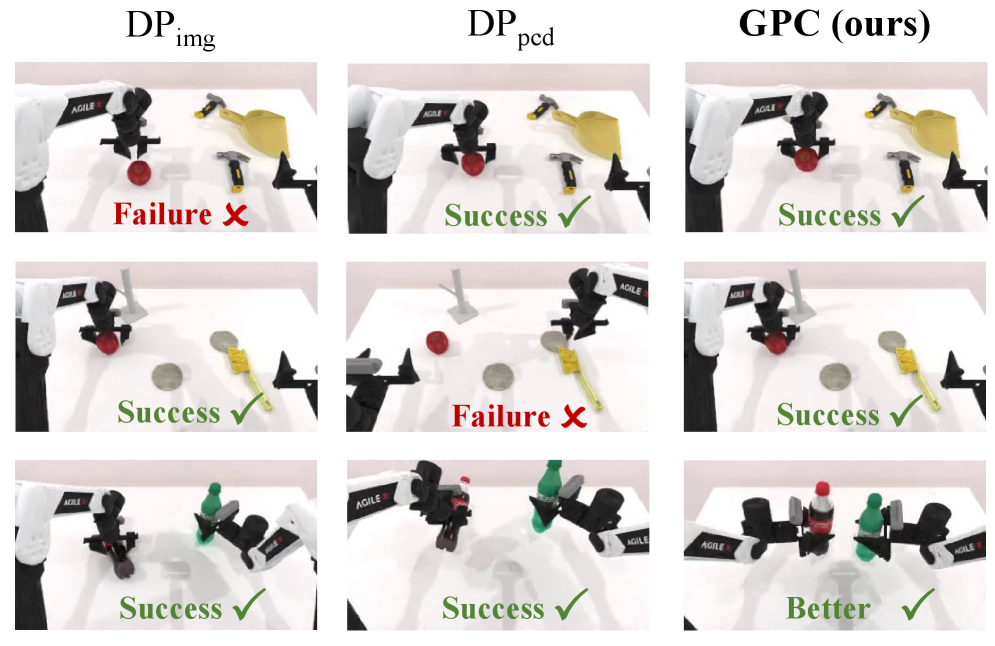
实验结果表明,GPC在Robomimic、PushT和RoboTwin等多个基准测试中均取得了显著的性能提升。例如,在Robomimic数据集上,GPC方法相比于最佳的单个策略,成功率提升了5%-10%。在真实机器人实验中,GPC也表现出良好的泛化能力和鲁棒性,能够有效地完成各种复杂的操作任务。此外,实验还分析了不同组合算子和权重策略对性能的影响,为GPC的进一步优化提供了指导。
🎯 应用场景
GPC方法可广泛应用于机器人控制领域,尤其是在数据获取成本高昂的场景下。例如,可以利用已有的仿真数据训练策略,然后通过GPC方法组合多个策略,提升在真实机器人上的性能。此外,GPC还可以用于组合不同模态的策略,例如视觉和触觉策略,从而提高机器人的感知能力和控制精度。该方法具有很强的通用性和可扩展性,有望推动机器人技术的进一步发展。
📄 摘要(原文)
Diffusion-based models for robotic control, including vision-language-action (VLA) and vision-action (VA) policies, have demonstrated significant capabilities. Yet their advancement is constrained by the high cost of acquiring large-scale interaction datasets. This work introduces an alternative paradigm for enhancing policy performance without additional model training. Perhaps surprisingly, we demonstrate that the composed policies can exceed the performance of either parent policy. Our contribution is threefold. First, we establish a theoretical foundation showing that the convex composition of distributional scores from multiple diffusion models can yield a superior one-step functional objective compared to any individual score. A Grönwall-type bound is then used to show that this single-step improvement propagates through entire generation trajectories, leading to systemic performance gains. Second, motivated by these results, we propose General Policy Composition (GPC), a training-free method that enhances performance by combining the distributional scores of multiple pre-trained policies via a convex combination and test-time search. GPC is versatile, allowing for the plug-and-play composition of heterogeneous policies, including VA and VLA models, as well as those based on diffusion or flow-matching, irrespective of their input visual modalities. Third, we provide extensive empirical validation. Experiments on Robomimic, PushT, and RoboTwin benchmarks, alongside real-world robotic evaluations, confirm that GPC consistently improves performance and adaptability across a diverse set of tasks. Further analysis of alternative composition operators and weighting strategies offers insights into the mechanisms underlying the success of GPC. These results establish GPC as a simple yet effective method for improving control performance by leveraging existing policies.