CroSTAta: Cross-State Transition Attention Transformer for Robotic Manipulation
作者: Giovanni Minelli, Giulio Turrisi, Victor Barasuol, Claudio Semini
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-01
备注: Code and data available at https://github.com/iit-DLSLab/croSTAta
💡 一句话要点
提出基于状态转移注意力的Transformer,提升机器人操作策略的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 模仿学习 注意力机制 Transformer 状态转移 时间推理 鲁棒性
📋 核心要点
- 现有机器人操作策略学习方法难以应对训练数据未覆盖的执行变化,鲁棒性不足。
- 论文提出跨状态转移注意力Transformer,通过状态转移注意力机制建模状态演化模式,提升策略对历史信息的利用。
- 实验表明,该方法在仿真环境中优于传统交叉注意力、TCN和LSTM等方法,尤其在精度要求高的任务中提升显著。
📝 摘要(中文)
通过模仿学习训练机器人操作策略面临挑战,尤其是在策略遇到训练数据未明确覆盖的执行变化时。虽然利用历史上下文的注意力机制可以提高鲁棒性,但标准方法处理序列中所有过去状态,而没有显式地建模演示中可能包含的时间结构,例如失败和恢复模式。我们提出了一种跨状态转移注意力Transformer,它采用一种新的状态转移注意力(STA)机制,根据学习到的状态演化模式来调节标准注意力权重,使策略能够更好地根据执行历史调整其行为。我们的方法将这种结构化注意力与训练期间的时间掩蔽相结合,其中视觉信息从最近的时间步中随机移除,以鼓励从历史上下文中进行时间推理。在仿真中的评估表明,在所有任务中,STA始终优于标准交叉注意力和时间建模方法(如TCN和LSTM网络),在对精度要求高的任务中,性能提升超过2倍。
🔬 方法详解
问题定义:论文旨在解决机器人操作策略在面对未知的执行变化时鲁棒性不足的问题。现有方法,如直接使用交叉注意力机制,平等地对待所有历史状态,忽略了状态之间的转移关系和时间结构,无法有效利用历史信息进行推理和决策。这种忽略导致策略难以从过去的失败或恢复模式中学习,从而降低了其泛化能力。
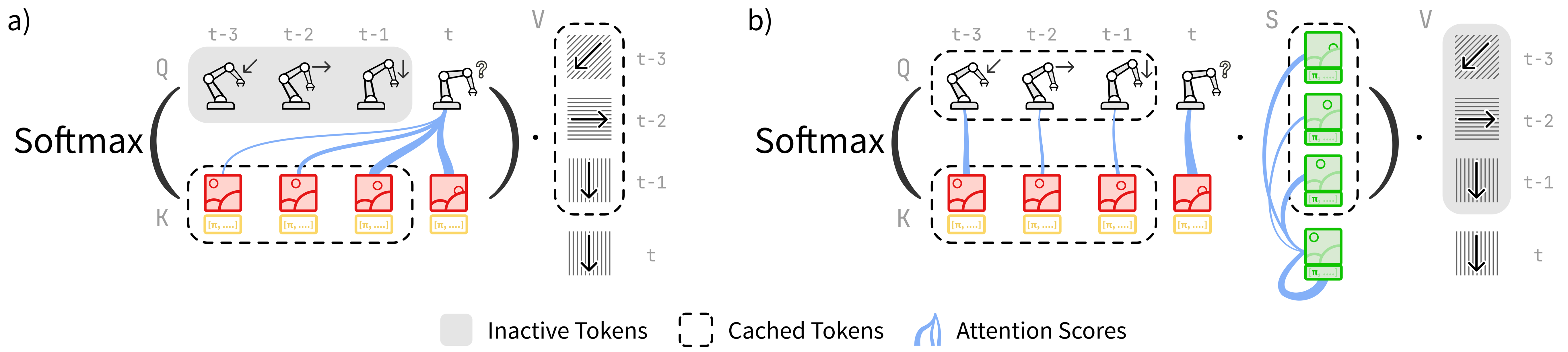
核心思路:论文的核心思路是引入状态转移注意力(STA)机制,显式地建模状态之间的演化关系。通过学习状态转移模式,STA能够根据历史状态的演化情况动态地调整注意力权重,从而使策略能够更加关注与当前状态相关的历史信息,并更好地预测未来的状态和动作。这种设计使得策略能够从过去的经验中学习,并根据执行历史调整其行为。
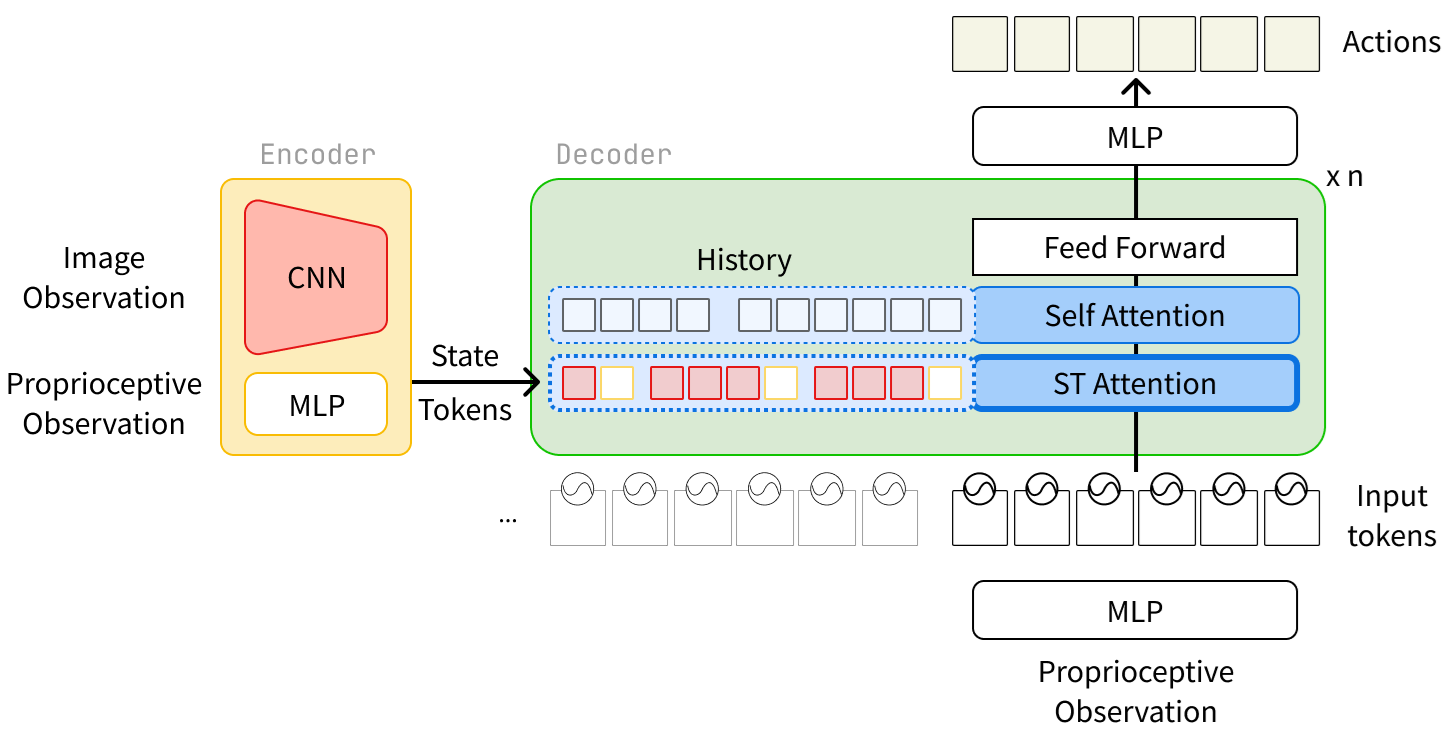
技术框架:整体框架基于Transformer架构,主要包括以下模块:1) 状态编码器:将当前状态和历史状态编码为向量表示。2) 状态转移注意力(STA)模块:计算状态之间的转移概率,并根据转移概率调整注意力权重。3) 注意力Transformer:利用调整后的注意力权重计算上下文向量,并用于预测未来的状态和动作。4) 时间掩蔽模块:在训练期间随机移除最近时间步的视觉信息,以鼓励策略从历史上下文中进行时间推理。
关键创新:论文最重要的技术创新点是状态转移注意力(STA)机制。与传统的注意力机制不同,STA不仅考虑了状态之间的相似性,还考虑了状态之间的转移概率。通过学习状态转移模式,STA能够更加准确地捕捉状态之间的依赖关系,从而提高策略的鲁棒性和泛化能力。STA与现有方法的本质区别在于,它显式地建模了状态之间的演化关系,而现有方法则忽略了这种关系。
关键设计:在STA模块中,状态转移概率通过一个可学习的转移矩阵来表示。该矩阵的每个元素表示从一个状态到另一个状态的转移概率。在训练过程中,转移矩阵通过最小化预测误差来学习。时间掩蔽模块通过随机选择一定比例的最近时间步,并将它们的视觉信息设置为零来实现。损失函数包括预测误差和正则化项,用于防止过拟合。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在仿真环境中,STA方法在所有任务中均优于标准交叉注意力、TCN和LSTM等基线方法。特别是在对精度要求高的任务中,STA的性能提升超过2倍。这些结果表明,STA能够有效地建模状态之间的转移关系,并提高策略的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如装配、抓取、导航等。通过提高机器人操作策略的鲁棒性和泛化能力,可以使机器人在更加复杂和动态的环境中执行任务,从而提高生产效率和降低人工成本。未来,该方法可以进一步扩展到多机器人协作、人机协作等领域,实现更加智能和高效的机器人系统。
📄 摘要(原文)
Learning robotic manipulation policies through supervised learning from demonstrations remains challenging when policies encounter execution variations not explicitly covered during training. While incorporating historical context through attention mechanisms can improve robustness, standard approaches process all past states in a sequence without explicitly modeling the temporal structure that demonstrations may include, such as failure and recovery patterns. We propose a Cross-State Transition Attention Transformer that employs a novel State Transition Attention (STA) mechanism to modulate standard attention weights based on learned state evolution patterns, enabling policies to better adapt their behavior based on execution history. Our approach combines this structured attention with temporal masking during training, where visual information is randomly removed from recent timesteps to encourage temporal reasoning from historical context. Evaluation in simulation shows that STA consistently outperforms standard cross-attention and temporal modeling approaches like TCN and LSTM networks across all tasks, achieving more than 2x improvement over cross-attention on precision-critical tasks.