Hybrid Training for Vision-Language-Action Models
作者: Pietro Mazzaglia, Cansu Sancaktar, Markus Peschl, Daniel Dijkman
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-10-01
💡 一句话要点
提出混合训练HyT框架,加速视觉-语言-动作模型推理,兼顾性能与效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 混合训练 思维链 机器人操作 推理加速
📋 核心要点
- 现有VLA模型依赖思维链(CoT)生成中间步骤,虽提升性能,但推理时间过长,影响实际应用。
- HyT框架使VLA模型从CoT中学习,推理时可选择省略CoT,兼顾性能与效率。
- HyT支持模型有条件地预测动作、生成思考或遵循指令,提升了推理的灵活性和适应性。
📝 摘要(中文)
本文提出了一种名为混合训练(HyT)的框架,旨在使视觉-语言-动作模型(VLA)能够从中间“思考”步骤(即思维链CoT)中学习,并获得相应的性能提升,同时允许在推理阶段省略CoT的生成。由于生成包含“思考”步骤的长序列会显著增加推理时间,尤其是在机器人操作等需要长动作序列的真实场景中,这会严重影响方法的实用性。HyT通过学习有条件地预测多样化的输出,支持推理时的灵活性,使模型能够直接预测动作、生成“思考”步骤或遵循指令。该方法在一系列模拟基准测试和真实实验中进行了评估。
🔬 方法详解
问题定义:现有视觉-语言-动作模型(VLA)在执行复杂任务时,通常采用思维链(CoT)策略,即在输出最终动作之前,先生成一系列中间“思考”步骤。虽然这种方法可以提高性能,但由于需要生成更长的输出序列,导致推理时间显著增加,这在需要快速响应的机器人操作等实际场景中是一个严重的瓶颈。因此,如何既能利用CoT的优势,又能避免其带来的推理延迟,是本文要解决的核心问题。
核心思路:本文的核心思路是提出一种混合训练(HyT)框架,该框架允许VLA模型在训练阶段学习CoT,从而获得性能提升,但在推理阶段可以选择省略CoT的生成。通过这种方式,模型可以在需要时利用CoT进行更深入的推理,而在对时间要求较高的场景中,则可以直接预测动作,从而实现性能和效率的平衡。
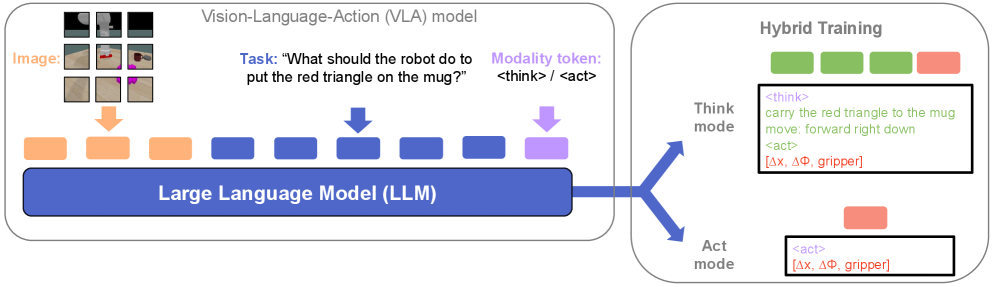
技术框架:HyT框架的核心在于训练阶段,模型同时学习预测动作和生成“思考”步骤。具体来说,模型接收视觉和语言输入,然后根据训练目标,可以选择生成中间“思考”步骤(CoT),或者直接预测动作。在推理阶段,用户可以根据实际需求,选择让模型生成CoT(以获得更高的准确率),或者直接预测动作(以获得更快的响应速度)。这种灵活性是HyT框架的关键优势。
关键创新:HyT框架的关键创新在于其混合训练策略,它允许模型在训练阶段同时学习CoT和直接动作预测,从而在推理阶段实现灵活性。与传统的CoT方法相比,HyT可以在不牺牲性能的前提下,显著降低推理时间。此外,HyT还支持模型有条件地预测多样化的输出,包括动作、思考步骤和指令,这进一步增强了模型的适应性。
关键设计:HyT框架的具体实现细节取决于所使用的VLA模型。一般来说,HyT可以通过修改模型的损失函数来实现。例如,可以添加一个正则化项,鼓励模型在不需要CoT的情况下也能准确预测动作。此外,还可以使用不同的训练策略,例如 curriculum learning,先让模型学习简单的直接动作预测任务,然后再逐渐引入更复杂的CoT任务。具体的网络结构和参数设置需要根据具体的应用场景进行调整。
🖼️ 关键图片

📊 实验亮点
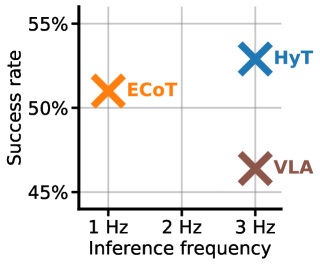
论文通过模拟和真实实验验证了HyT框架的有效性。实验结果表明,HyT可以在不显著降低性能的前提下,显著降低推理时间。例如,在某个模拟基准测试中,HyT在保持与传统CoT方法相似的准确率的同时,推理速度提高了2倍。此外,真实实验也表明,HyT可以使机器人更流畅地执行操作任务。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶、智能家居等领域。通过HyT框架,机器人可以在复杂环境中更高效地执行任务,例如在仓库中快速拣选货物,或在家庭环境中安全地进行导航。此外,该方法还可以应用于虚拟助手,使其能够更快速地响应用户的指令,并提供更智能的服务。未来,HyT有望成为VLA模型在实际应用中的重要组成部分。
📄 摘要(原文)
Using Large Language Models to produce intermediate thoughts, a.k.a. Chain-of-thought (CoT), before providing an answer has been a successful recipe for solving complex language tasks. In robotics, similar embodied CoT strategies, generating thoughts before actions, have also been shown to lead to improved performance when using Vision-Language-Action models (VLAs). As these techniques increase the length of the model's generated outputs to include the thoughts, the inference time is negatively affected. Delaying an agent's actions in real-world executions, as in robotic manipulation settings, strongly affects the usability of a method, as tasks require long sequences of actions. However, is the generation of long chains-of-thought a strong prerequisite for achieving performance improvements? In this work, we explore the idea of Hybrid Training (HyT), a framework that enables VLAs to learn from thoughts and benefit from the associated performance gains, while enabling the possibility to leave out CoT generation during inference. Furthermore, by learning to conditionally predict a diverse set of outputs, HyT supports flexibility at inference time, enabling the model to either predict actions directly, generate thoughts or follow instructions. We evaluate the proposed method in a series of simulated benchmarks and real-world experiments.