DiSA-IQL: Offline Reinforcement Learning for Robust Soft Robot Control under Distribution Shifts
作者: Linjin He, Xinda Qi, Dong Chen, Zhaojian Li, Xiaobo Tan
分类: cs.RO, cs.AI
发布日期: 2025-09-30
💡 一句话要点
DiSA-IQL:面向分布偏移下柔性机器人鲁棒控制的离线强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 柔性机器人 分布偏移 鲁棒控制 隐式Q学习
📋 核心要点
- 柔性机器人控制面临非线性动力学挑战,传统方法依赖简化假设,限制了其在复杂环境中的性能。
- DiSA-IQL通过惩罚不可靠的状态-动作对,在IQL基础上引入鲁棒性调节,缓解分布偏移问题。
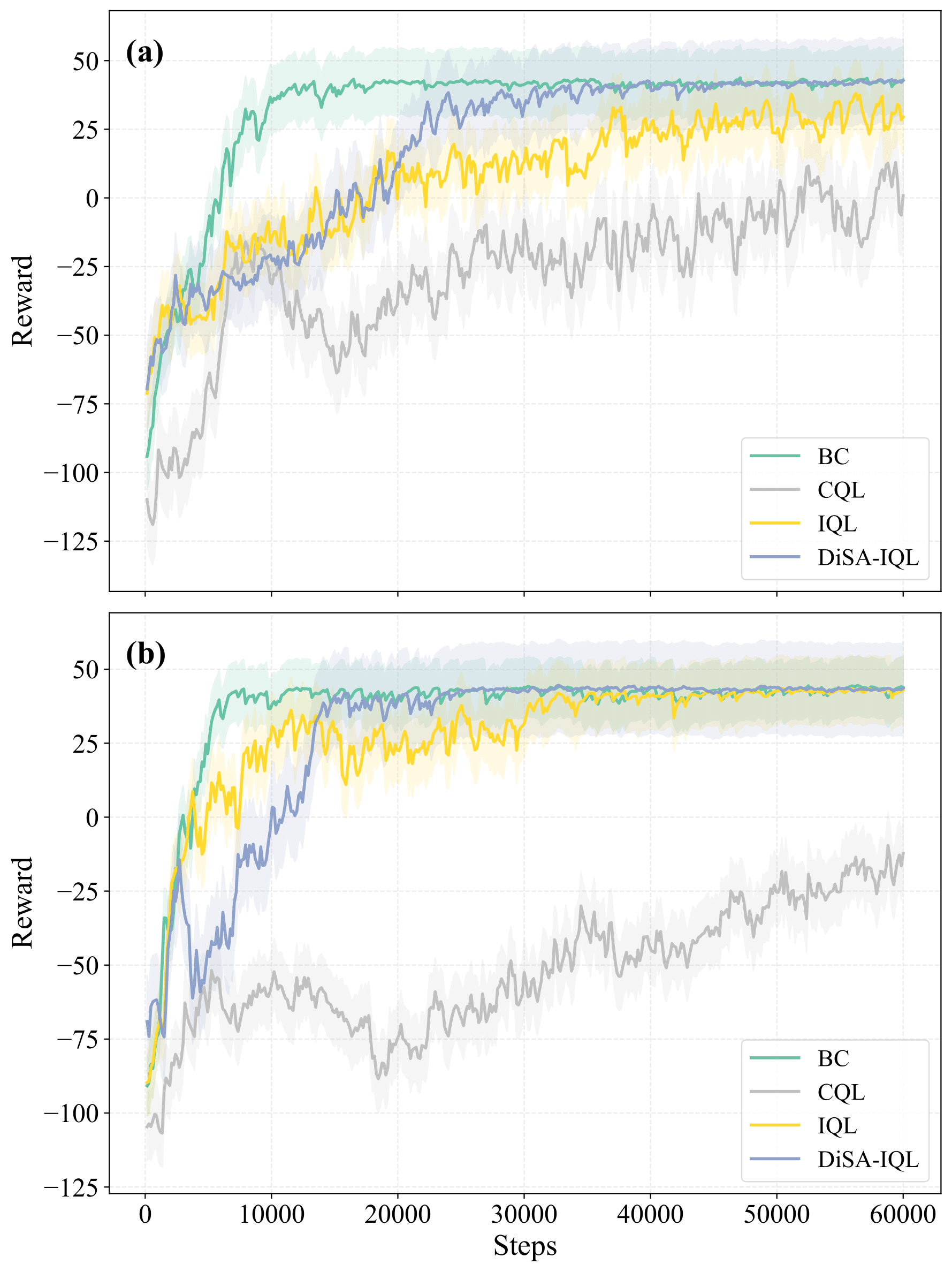
- 仿真结果表明,DiSA-IQL在同分布和异分布场景下均优于BC、CQL和IQL等基线模型。
📝 摘要(中文)
柔性蛇形机器人在复杂环境中具有卓越的灵活性和适应性,但由于其高度非线性动力学,控制仍然具有挑战性。现有的基于模型和仿生控制器依赖于简化的假设,限制了性能。深度强化学习(DRL)最近成为一种有前途的替代方案,但由于代价高昂且可能造成损害的真实世界交互,在线训练通常是不切实际的。离线强化学习通过利用预先收集的数据集提供了一种更安全的选择,但它受到分布偏移的影响,这降低了对未见场景的泛化能力。为了克服这一挑战,我们提出了DiSA-IQL(Distribution-Shift-Aware Implicit Q-Learning),它是IQL的扩展,通过惩罚不可靠的状态-动作对来减轻分布偏移,从而结合了鲁棒性调节。我们在两种设置下的目标到达任务中评估DiSA-IQL:同分布和异分布评估。仿真结果表明,DiSA-IQL始终优于基线模型,包括行为克隆(BC)、保守Q学习(CQL)和原始IQL,实现了更高的成功率、更平滑的轨迹和改进的鲁棒性。代码已开源,以支持可重复性并促进柔性机器人控制离线强化学习的进一步研究。
🔬 方法详解
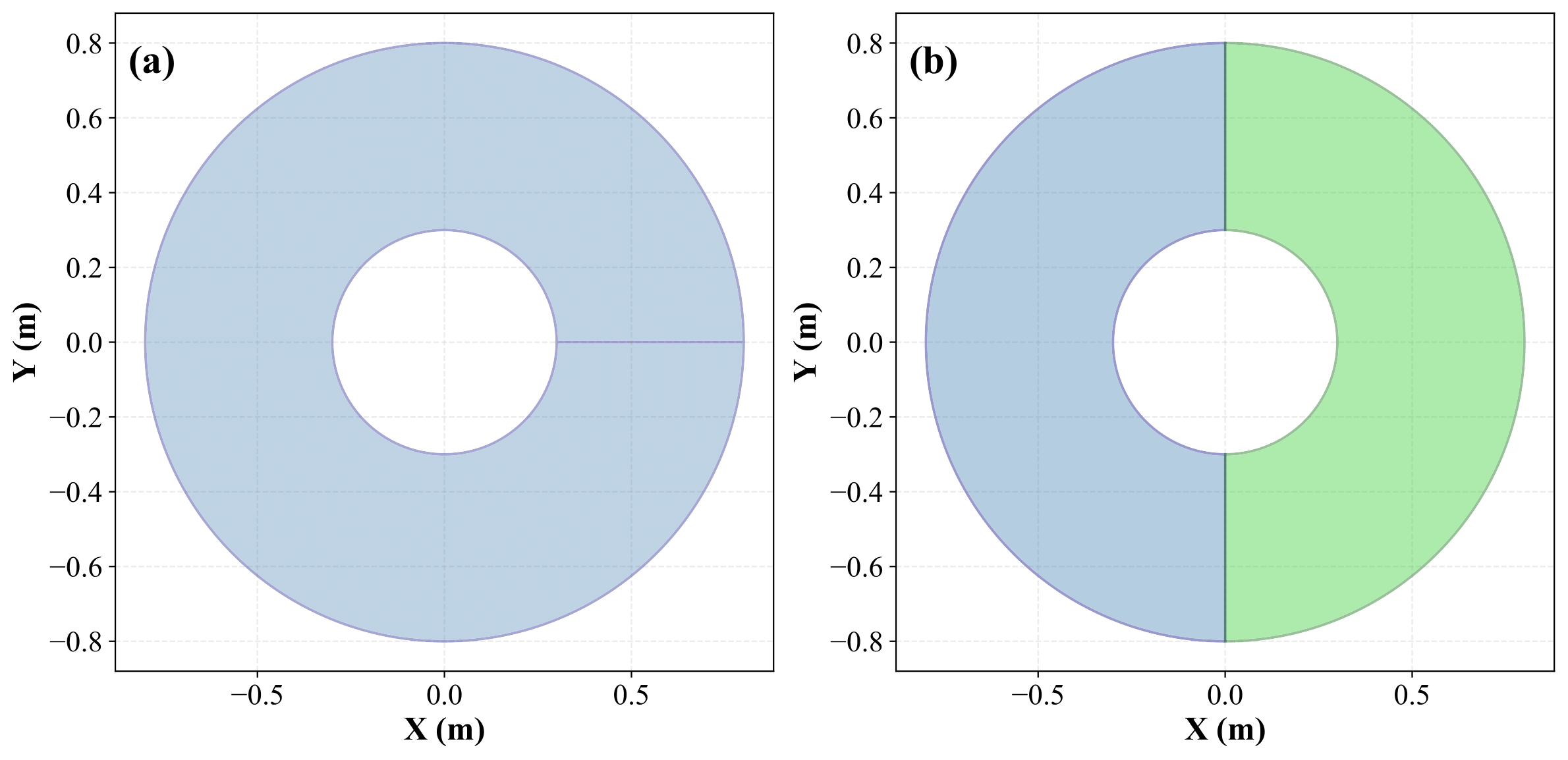
问题定义:论文旨在解决柔性机器人在离线强化学习中,由于数据分布偏移导致的控制策略泛化能力差的问题。现有的离线强化学习方法在训练数据与实际环境存在差异时,性能会显著下降,无法保证柔性机器人在未知环境中的稳定控制。
核心思路:论文的核心思路是设计一种分布偏移感知的离线强化学习算法,通过对不可靠的状态-动作对进行惩罚,从而提高策略的鲁棒性。这种方法旨在使学习到的策略对训练数据中的噪声和偏差具有更强的抵抗能力,从而在实际环境中表现更好。
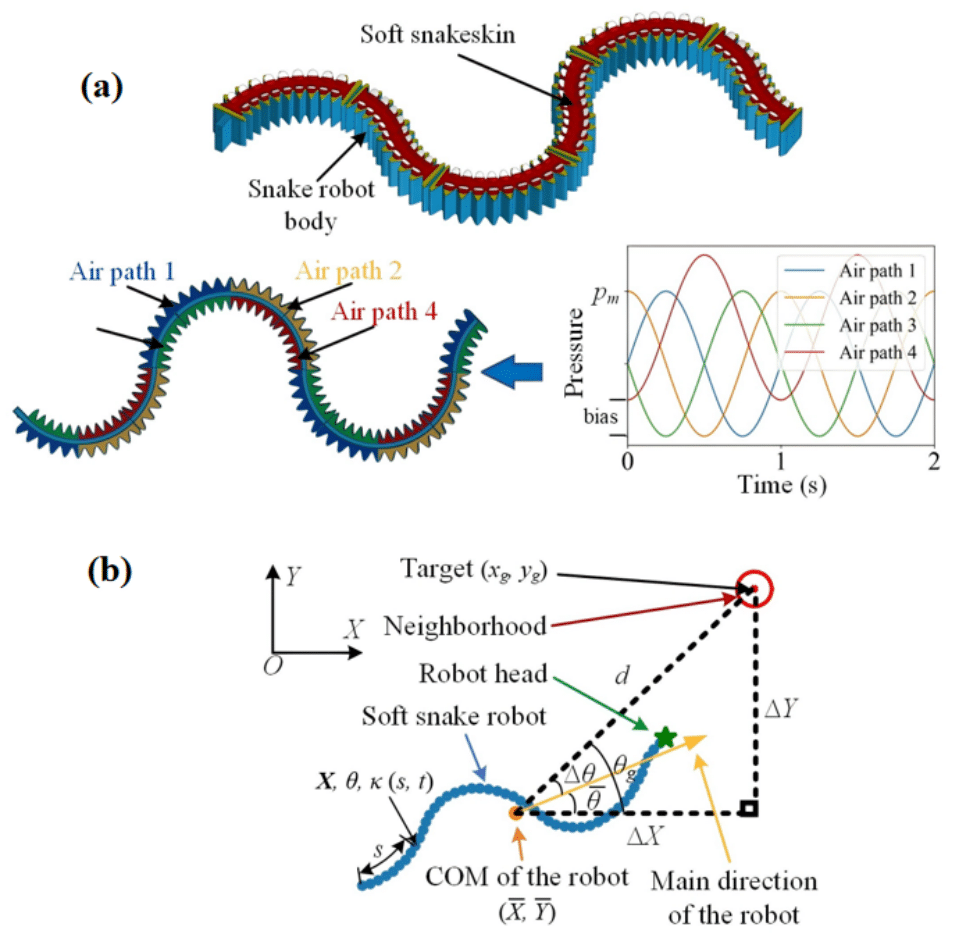
技术框架:DiSA-IQL是在隐式Q学习(IQL)框架上的扩展。整体流程包括:1) 收集离线数据集;2) 使用数据集训练Q函数和价值函数;3) 在训练过程中,引入分布偏移感知模块,对Q函数进行调整,降低不可靠状态-动作对的影响;4) 使用训练好的Q函数和价值函数提取策略。
关键创新:DiSA-IQL的关键创新在于引入了分布偏移感知模块,该模块能够评估状态-动作对的可靠性,并根据可靠性对Q函数进行调整。与传统的IQL相比,DiSA-IQL能够更好地处理分布偏移问题,从而提高策略的泛化能力和鲁棒性。
关键设计:DiSA-IQL的关键设计包括:1) 使用一个额外的网络来估计状态-动作对的可靠性;2) 设计一个损失函数,该损失函数不仅考虑了Q函数的准确性,还考虑了状态-动作对的可靠性;3) 通过调整损失函数中的权重,可以控制分布偏移感知模块的影响程度。
🖼️ 关键图片
📊 实验亮点
DiSA-IQL在柔性蛇形机器人的目标到达任务中表现出色,在同分布和异分布两种设置下均优于BC、CQL和IQL等基线模型。具体而言,DiSA-IQL实现了更高的成功率,生成了更平滑的轨迹,并展现出更强的鲁棒性。这些结果表明,DiSA-IQL能够有效缓解分布偏移问题,提高离线强化学习在柔性机器人控制中的性能。
🎯 应用场景
该研究成果可应用于各种需要柔性机器人进行复杂操作的场景,例如医疗手术、灾难救援、管道检测等。通过离线学习预先收集的数据,可以避免在线训练带来的风险和成本,提高柔性机器人在实际应用中的安全性和效率。未来,该方法有望推广到其他类型的机器人和控制任务中。
📄 摘要(原文)
Soft snake robots offer remarkable flexibility and adaptability in complex environments, yet their control remains challenging due to highly nonlinear dynamics. Existing model-based and bio-inspired controllers rely on simplified assumptions that limit performance. Deep reinforcement learning (DRL) has recently emerged as a promising alternative, but online training is often impractical because of costly and potentially damaging real-world interactions. Offline RL provides a safer option by leveraging pre-collected datasets, but it suffers from distribution shift, which degrades generalization to unseen scenarios. To overcome this challenge, we propose DiSA-IQL (Distribution-Shift-Aware Implicit Q-Learning), an extension of IQL that incorporates robustness modulation by penalizing unreliable state-action pairs to mitigate distribution shift. We evaluate DiSA-IQL on goal-reaching tasks across two settings: in-distribution and out-of-distribution evaluation. Simulation results show that DiSA-IQL consistently outperforms baseline models, including Behavior Cloning (BC), Conservative Q-Learning (CQL), and vanilla IQL, achieving higher success rates, smoother trajectories, and improved robustness. The codes are open-sourced to support reproducibility and to facilitate further research in offline RL for soft robot control.