Learning Human Reaching Optimality Principles from Minimal Observation Inverse Reinforcement Learning
作者: Sarmad Mehrdad, Maxime Sabbah, Vincent Bonnet, Ludovic Righetti
分类: cs.RO
发布日期: 2025-09-30
备注: 8 pages, 4 figures
💡 一句话要点
提出基于最小观测逆强化学习的人体手臂运动最优性建模方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 运动建模 人体运动 最优控制 生物力学 人形机器人 最小观测
📋 核心要点
- 传统逆强化学习需要大量演示数据,且难以捕捉运动过程中代价函数的变化,限制了其在人体运动建模中的应用。
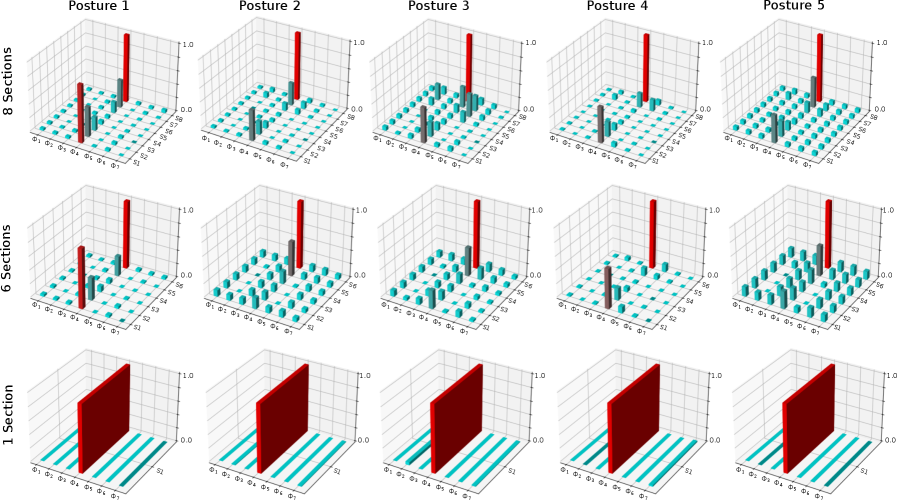
- 本文提出MO-IRL方法,通过迭代优化代价权重,显著减少了所需演示数据量,并能学习到分阶段的动态代价函数。
- 实验表明,该方法在预测人体手臂到达运动时,具有较高的精度和良好的泛化能力,能够捕捉到运动过程中的关键优化原则。
📝 摘要(中文)
本文研究了最小观测逆强化学习(MO-IRL)在建模和预测具有时变代价权重的人体手臂到达运动中的应用。使用平面二连杆生物力学模型和来自受试者执行指向任务的高分辨率运动捕捉数据,我们将每个轨迹分割成多个阶段,并学习七个候选代价函数的特定阶段组合。MO-IRL通过在最大熵IRL公式中缩放观察到的和生成的轨迹来迭代地细化代价权重,与经典的IRL方法相比,大大减少了所需的演示次数和收敛时间。在每个姿势上训练十次试验,对于六段和八段权重划分,分别产生平均关节角度均方根误差(RMSE)为6.4度和5.6度,而使用单个静态权重时为10.4度。对剩余试验的交叉验证,以及首次对未见受试者的20次试验进行受试者间验证,证明了相当的预测精度,约为8度RMSE,表明了鲁棒的泛化能力。学习到的权重强调运动开始和结束期间的关节加速度最小化,这与生物运动中观察到的平滑性原则一致。这些结果表明,MO-IRL可以有效地揭示人类运动控制的动态、受试者独立的代价结构,并具有在人形机器人中的潜在应用。
🔬 方法详解
问题定义:论文旨在解决如何高效地从少量的人体运动数据中学习到潜在的运动控制策略,特别是手臂到达运动。现有逆强化学习方法通常需要大量的演示数据才能有效学习,并且难以捕捉运动过程中代价函数随时间变化的情况,这限制了其在实际应用中的可行性。
核心思路:论文的核心思路是利用最小观测逆强化学习(MO-IRL),通过迭代地优化代价权重,使得模型生成的轨迹与观察到的轨迹尽可能相似。MO-IRL通过在最大熵逆强化学习框架下,缩放观察到的和生成的轨迹,从而减少了对大量演示数据的需求,并能够学习到分阶段的动态代价函数。
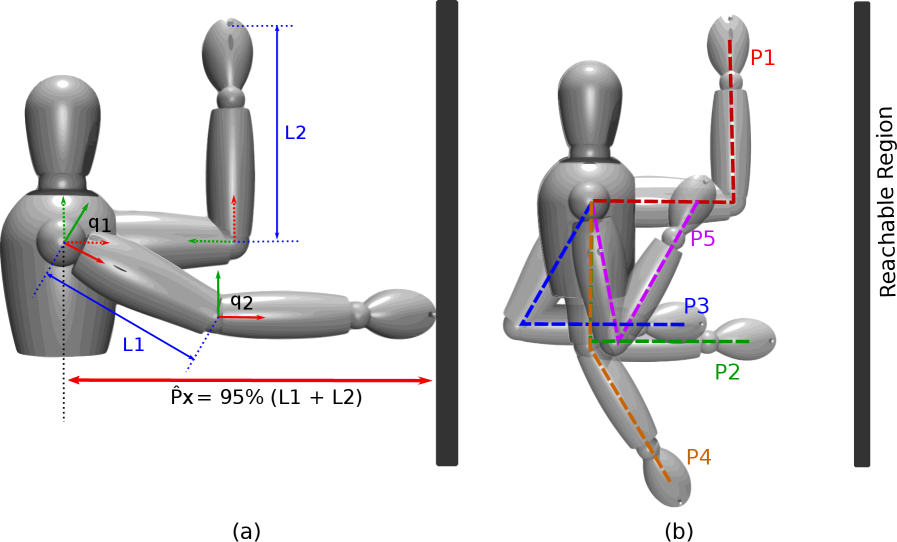
技术框架:整体框架包括以下几个主要阶段:1) 数据采集:使用运动捕捉系统记录人体手臂到达运动的轨迹数据。2) 模型构建:建立一个平面二连杆生物力学模型来模拟手臂运动。3) 轨迹分割:将每个轨迹分割成多个阶段,每个阶段对应不同的代价权重。4) MO-IRL优化:使用MO-IRL算法迭代地优化每个阶段的代价权重,使得模型生成的轨迹与观察到的轨迹尽可能相似。5) 性能评估:使用均方根误差(RMSE)等指标评估模型的预测精度和泛化能力。
关键创新:最重要的技术创新点是MO-IRL在人体运动建模中的应用,以及其在减少数据需求和捕捉动态代价函数方面的优势。与传统的逆强化学习方法相比,MO-IRL能够从更少的演示数据中学习到更准确的运动控制策略,并且能够捕捉到运动过程中代价函数随时间变化的情况。
关键设计:论文中关键的设计包括:1) 使用最大熵逆强化学习框架,以保证学习到的策略具有一定的鲁棒性。2) 将轨迹分割成多个阶段,每个阶段对应不同的代价权重,以捕捉运动过程中代价函数的变化。3) 使用七个候选代价函数,包括关节角度、关节速度、关节加速度等的最小化,以反映人体运动控制的潜在优化目标。4) 使用迭代优化算法来更新代价权重,直到模型生成的轨迹与观察到的轨迹足够相似。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MO-IRL方法在预测人体手臂到达运动时,具有较高的精度和良好的泛化能力。在每个姿势上训练十次试验,对于六段和八段权重划分,分别产生平均关节角度均方根误差(RMSE)为6.4度和5.6度,而使用单个静态权重时为10.4度。对未见受试者的20次试验进行受试者间验证,证明了预测精度约为8度RMSE,表明了鲁棒的泛化能力。
🎯 应用场景
该研究成果可应用于人形机器人控制、康复机器人设计、虚拟现实人机交互等领域。通过学习人类运动的最优性原则,可以使机器人能够更自然、更高效地完成各种任务,提高人机交互的流畅性和安全性。此外,该方法还可以用于分析不同人群的运动模式,为运动康复提供个性化的指导。
📄 摘要(原文)
This paper investigates the application of Minimal Observation Inverse Reinforcement Learning (MO-IRL) to model and predict human arm-reaching movements with time-varying cost weights. Using a planar two-link biomechanical model and high-resolution motion-capture data from subjects performing a pointing task, we segment each trajectory into multiple phases and learn phase-specific combinations of seven candidate cost functions. MO-IRL iteratively refines cost weights by scaling observed and generated trajectories in the maximum entropy IRL formulation, greatly reducing the number of required demonstrations and convergence time compared to classical IRL approaches. Training on ten trials per posture yields average joint-angle Root Mean Squared Errors (RMSE) of 6.4 deg and 5.6 deg for six- and eight-segment weight divisions, respectively, versus 10.4 deg using a single static weight. Cross-validation on remaining trials and, for the first time, inter-subject validation on an unseen subject's 20 trials, demonstrates comparable predictive accuracy, around 8 deg RMSE, indicating robust generalization. Learned weights emphasize joint acceleration minimization during movement onset and termination, aligning with smoothness principles observed in biological motion. These results suggest that MO-IRL can efficiently uncover dynamic, subject-independent cost structures underlying human motor control, with potential applications for humanoid robots.