TGPO: Temporal Grounded Policy Optimization for Signal Temporal Logic Tasks
作者: Yue Meng, Fei Chen, Chuchu Fan
分类: cs.RO, cs.AI, cs.LG, cs.LO
发布日期: 2025-09-30
🔗 代码/项目: GITHUB
💡 一句话要点
提出TGPO,通过时序分解和分层优化解决基于STL的任务规划问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 信号时序逻辑 强化学习 分层策略 时间分配 机器人控制
📋 核心要点
- 复杂、长时程任务的策略学习是机器人和自主系统的核心挑战,现有强化学习方法难以直接应用于非马尔可夫的STL任务。
- TGPO将STL任务分解为带时间约束的子目标,通过分层框架,高层进行时间分配,低层学习时间条件策略,从而实现任务目标。
- 实验表明,TGPO在多种环境下显著优于现有方法,尤其是在高维和长时程任务中,任务成功率平均提升了31.6%。
📝 摘要(中文)
本文提出了一种名为时间锚定策略优化(TGPO)的方法,用于解决一般的信号时序逻辑(STL)任务。TGPO将STL分解为带时间约束的子目标和不变约束,并提供了一个分层框架来解决该问题。TGPO的高层组件为这些子目标提出具体的时序分配,而低层的时间条件策略学习使用密集的、阶段性的奖励信号来实现排序后的子目标。在推理过程中,我们对各种时间分配进行采样,并选择最有希望的分配,以便策略网络展开解决方案轨迹。为了促进具有多个子目标的复杂STL的高效策略学习,我们利用学习到的评论家通过Metropolis-Hastings采样来指导高层时间搜索,从而将探索重点放在时间上可行的解决方案上。我们在五个环境中进行了实验,范围从低维导航到操作、无人机和四足运动。在广泛的STL任务下,TGPO显著优于最先进的基线(尤其是在高维和长时程情况下),与最佳基线相比,任务成功率平均提高了31.6%。
🔬 方法详解
问题定义:论文旨在解决机器人和自主系统中,如何高效学习满足复杂信号时序逻辑(STL)约束的控制策略问题。现有方法通常只能处理有限的STL片段,或者将STL鲁棒性分数作为稀疏的终端奖励,导致学习效率低下,难以处理高维和长时程任务。
核心思路:TGPO的核心思路是将复杂的STL任务分解为一系列带时间约束的子目标和不变约束。通过分层策略,高层负责为子目标分配时间,低层学习在给定时间约束下实现子目标的策略。这种分解和分层优化使得问题更容易求解,并能利用密集的阶段性奖励信号来加速学习。
技术框架:TGPO包含两个主要组件:高层的时间分配器和低层的时间条件策略。高层时间分配器使用Metropolis-Hastings采样方法,根据学习到的评论家提供的反馈,搜索可行的时间分配方案。低层时间条件策略则学习在给定的时间分配下,如何按顺序实现各个子目标。整个框架通过迭代优化高层的时间分配和低层的策略,最终找到满足STL约束的控制策略。
关键创新:TGPO的关键创新在于将STL任务分解为带时间约束的子目标,并使用分层策略进行优化。这种分解使得问题更容易求解,并能利用密集的阶段性奖励信号来加速学习。此外,TGPO还利用学习到的评论家来指导高层的时间搜索,从而提高搜索效率。
关键设计:高层时间分配器使用Metropolis-Hastings采样,其接受概率基于学习到的评论家对当前时间分配方案的评估。低层时间条件策略可以使用任何标准的强化学习算法进行训练,例如PPO。奖励函数的设计至关重要,需要提供密集的阶段性奖励,以引导策略学习实现各个子目标。具体网络结构和参数设置取决于具体的任务环境。
🖼️ 关键图片

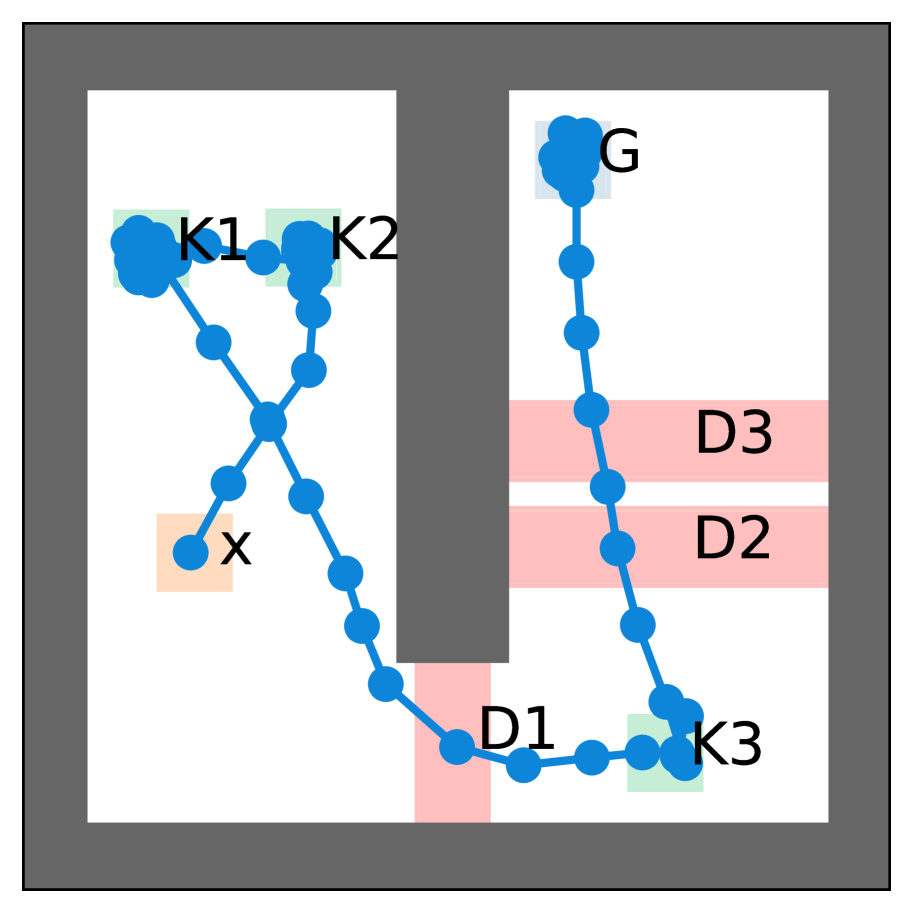

📊 实验亮点
实验结果表明,TGPO在五个不同的环境中,包括低维导航、操作、无人机和四足运动,都显著优于现有的基线方法。特别是在高维和长时程任务中,TGPO的优势更加明显。与最佳基线相比,TGPO的任务成功率平均提高了31.6%,证明了其在解决复杂STL任务方面的有效性。
🎯 应用场景
TGPO具有广泛的应用前景,例如自主导航、机器人操作、无人机控制和四足机器人运动等领域。它可以用于开发能够安全可靠地执行复杂任务的自主系统,例如在仓库中进行货物搬运、在复杂环境中进行搜索救援、以及在危险环境中进行巡检等。
📄 摘要(原文)
Learning control policies for complex, long-horizon tasks is a central challenge in robotics and autonomous systems. Signal Temporal Logic (STL) offers a powerful and expressive language for specifying such tasks, but its non-Markovian nature and inherent sparse reward make it difficult to be solved via standard Reinforcement Learning (RL) algorithms. Prior RL approaches focus only on limited STL fragments or use STL robustness scores as sparse terminal rewards. In this paper, we propose TGPO, Temporal Grounded Policy Optimization, to solve general STL tasks. TGPO decomposes STL into timed subgoals and invariant constraints and provides a hierarchical framework to tackle the problem. The high-level component of TGPO proposes concrete time allocations for these subgoals, and the low-level time-conditioned policy learns to achieve the sequenced subgoals using a dense, stage-wise reward signal. During inference, we sample various time allocations and select the most promising assignment for the policy network to rollout the solution trajectory. To foster efficient policy learning for complex STL with multiple subgoals, we leverage the learned critic to guide the high-level temporal search via Metropolis-Hastings sampling, focusing exploration on temporally feasible solutions. We conduct experiments on five environments, ranging from low-dimensional navigation to manipulation, drone, and quadrupedal locomotion. Under a wide range of STL tasks, TGPO significantly outperforms state-of-the-art baselines (especially for high-dimensional and long-horizon cases), with an average of 31.6% improvement in task success rate compared to the best baseline. The code will be available at https://github.com/mengyuest/TGPO