MLA: A Multisensory Language-Action Model for Multimodal Understanding and Forecasting in Robotic Manipulation
作者: Zhuoyang Liu, Jiaming Liu, Jiadong Xu, Nuowei Han, Chenyang Gu, Hao Chen, Kaichen Zhou, Renrui Zhang, Kai Chin Hsieh, Kun Wu, Zhengping Che, Jian Tang, Shanghang Zhang
分类: cs.RO
发布日期: 2025-09-30
💡 一句话要点
提出MLA多感官语言-动作模型,增强机器人操作中的多模态理解与预测能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 机器人操作 视觉语言动作模型 物理世界建模 触觉感知
📋 核心要点
- 现有VLA模型在机器人操作中缺乏对多感官信息的综合理解,限制了其在复杂物理交互任务中的表现。
- MLA模型通过多模态对齐方案和未来多感官生成策略,增强了对物理世界的感知和预测能力。
- 实验结果表明,MLA模型在真实世界的机器人操作任务中显著优于现有方法,并具有更好的泛化能力。
📝 摘要(中文)
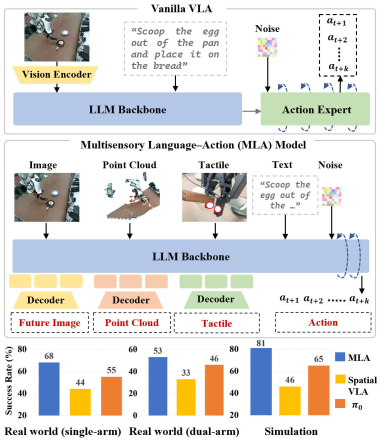
视觉-语言-动作模型(VLA)通过继承视觉-语言模型(VLM)并学习动作生成,在机器人操作任务中展现了泛化能力。然而,现有VLA模型主要关注视觉和语言的解释以生成动作,忽略了机器人与空间物理世界的感知和交互。为此,我们提出了一个多感官语言-动作(MLA)模型,协同感知异构感官模态,并预测未来的多感官目标,以促进物理世界建模。具体而言,为了增强感知表征,我们提出了一种无编码器的多模态对齐方案,创新性地将大型语言模型本身重新用作感知模块,通过位置对应直接解释2D图像、3D点云和触觉token。为了进一步增强MLA对物理动态的理解,我们设计了一种未来多感官生成后训练策略,使MLA能够推理语义、几何和交互信息,为动作生成提供更鲁棒的条件。在评估中,MLA模型在复杂的、接触丰富的真实世界任务中,分别优于先前的最先进的2D和3D VLA方法12%和24%,同时也展示了对未见配置的改进泛化能力。
🔬 方法详解
问题定义:现有视觉-语言-动作模型(VLA)在机器人操作任务中,主要依赖视觉和语言信息生成动作,忽略了机器人与物理世界的交互过程中产生的大量多感官信息,如触觉、力觉等。这导致模型难以理解复杂的物理动态,尤其是在接触丰富的操作任务中表现不佳。现有方法的痛点在于缺乏对多模态信息的有效融合和利用,以及对未来状态的预测能力。
核心思路:MLA的核心思路是利用大型语言模型(LLM)强大的语义理解能力,将其作为多模态信息的统一处理框架。通过将不同模态的信息(视觉、点云、触觉)对齐到LLM的token空间,实现多模态信息的融合。同时,通过未来多感官生成策略,使模型能够预测未来的状态,从而更好地规划动作。
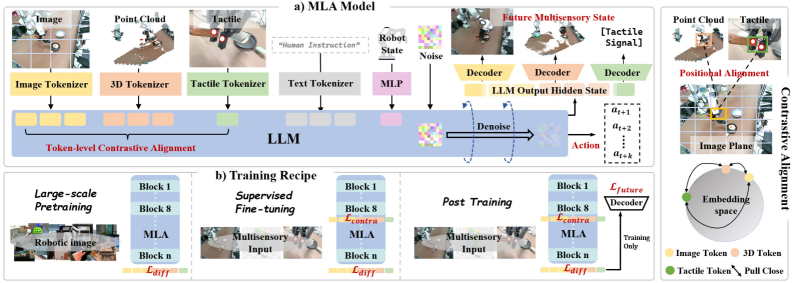
技术框架:MLA模型的整体框架包括三个主要部分:多模态感知模块、语言模型和动作生成模块。多模态感知模块负责将2D图像、3D点云和触觉数据转换为token序列,并对齐到语言模型的token空间。语言模型则负责理解这些token序列,并预测未来的多感官目标。最后,动作生成模块根据语言模型的输出生成相应的机器人动作。
关键创新:MLA的关键创新在于以下两点:1) 提出了一种无编码器的多模态对齐方案,直接将LLM作为感知模块,避免了传统编码器可能造成的的信息损失。2) 设计了一种未来多感官生成后训练策略,使模型能够预测未来的多感官状态,从而更好地理解物理动态。
关键设计:多模态对齐方案通过位置对应关系将不同模态的信息对齐到LLM的token空间。具体来说,对于2D图像,使用预训练的视觉Transformer提取特征,并将其转换为token序列。对于3D点云,使用PointNet++提取特征,并将其转换为token序列。对于触觉数据,使用简单的线性层将其转换为token序列。然后,将这些token序列拼接在一起,作为LLM的输入。未来多感官生成后训练策略通过预测未来的视觉、点云和触觉信息来训练模型。损失函数包括视觉重建损失、点云重建损失和触觉重建损失。
🖼️ 关键图片
📊 实验亮点
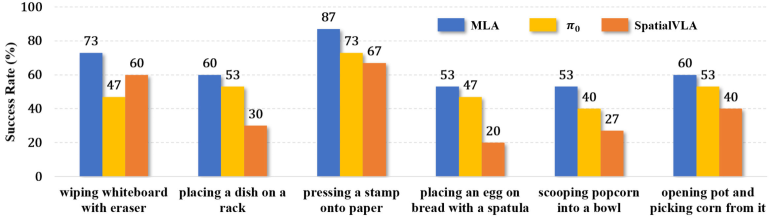
MLA模型在复杂的、接触丰富的真实世界机器人操作任务中,分别优于先前的最先进的2D和3D VLA方法12%和24%。此外,MLA模型还展示了对未见配置的改进泛化能力,表明其具有更强的适应性和鲁棒性。这些实验结果验证了MLA模型在多模态理解和预测方面的优势。
🎯 应用场景
MLA模型可应用于各种需要复杂物理交互的机器人操作任务,例如装配、抓取、操作工具等。该模型能够提升机器人在复杂环境中的适应性和鲁棒性,使其能够更好地完成任务。未来,MLA模型有望应用于智能制造、医疗机器人、家庭服务机器人等领域,实现更智能、更高效的自动化。
📄 摘要(原文)
Vision-language-action models (VLAs) have shown generalization capabilities in robotic manipulation tasks by inheriting from vision-language models (VLMs) and learning action generation. Most VLA models focus on interpreting vision and language to generate actions, whereas robots must perceive and interact within the spatial-physical world. This gap highlights the need for a comprehensive understanding of robotic-specific multisensory information, which is crucial for achieving complex and contact-rich control. To this end, we introduce a multisensory language-action (MLA) model that collaboratively perceives heterogeneous sensory modalities and predicts future multisensory objectives to facilitate physical world modeling. Specifically, to enhance perceptual representations, we propose an encoder-free multimodal alignment scheme that innovatively repurposes the large language model itself as a perception module, directly interpreting multimodal cues by aligning 2D images, 3D point clouds, and tactile tokens through positional correspondence. To further enhance MLA's understanding of physical dynamics, we design a future multisensory generation post-training strategy that enables MLA to reason about semantic, geometric, and interaction information, providing more robust conditions for action generation. For evaluation, the MLA model outperforms the previous state-of-the-art 2D and 3D VLA methods by 12% and 24% in complex, contact-rich real-world tasks, respectively, while also demonstrating improved generalization to unseen configurations. Project website: https://sites.google.com/view/open-mla