Evolutionary Continuous Adaptive RL-Powered Co-Design for Humanoid Chin-Up Performance
作者: Tianyi Jin, Melya Boukheddimi, Rohit Kumar, Gabriele Fadini, Frank Kirchner
分类: cs.RO
发布日期: 2025-09-30
💡 一句话要点
提出EA-CoRL框架,解决人形机器人协同设计中控制策略对硬件的持续适应问题,提升引体向上性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 协同设计 强化学习 进化算法 人形机器人 控制策略
📋 核心要点
- 传统机器人设计流程是先确定硬件再开发控制算法,这可能导致机器人无法充分利用其硬件能力。
- EA-CoRL框架通过进化算法探索硬件设计空间,并利用强化学习持续优化控制策略以适应硬件变化。
- 实验表明,EA-CoRL在人形机器人引体向上任务中,相比现有方法,实现了更高的性能和更广的设计空间探索。
📝 摘要(中文)
本文提出了一种基于进化连续自适应强化学习的协同设计框架(EA-CoRL),该框架结合了强化学习(RL)和进化策略,使控制策略能够持续适应硬件的变化。EA-CoRL包含两个关键组成部分:设计进化,它使用进化算法探索硬件选择,以识别高效的配置;策略连续适应,它在不断发展的设计中微调特定任务的控制策略,以最大化性能奖励。我们通过协同设计RH5人形机器人的执行器(齿轮比)和控制策略来评估EA-CoRL,以完成以前因执行器限制而不可行的高动态引体向上任务。与最先进的基于RL的协同设计方法相比,结果表明EA-CoRL实现了更高的适应度分数和更广泛的设计空间探索,突出了连续策略适应在机器人协同设计中的关键作用。
🔬 方法详解
问题定义:论文旨在解决人形机器人协同设计中,控制策略难以有效适应不断变化的硬件设计的问题。传统方法通常采用先设计硬件再设计控制器的串行方式,或者采用离散的协同设计方法,无法实现控制策略对硬件的持续优化和适应,导致机器人性能受限。尤其是在高动态任务中,执行器的限制更加明显。
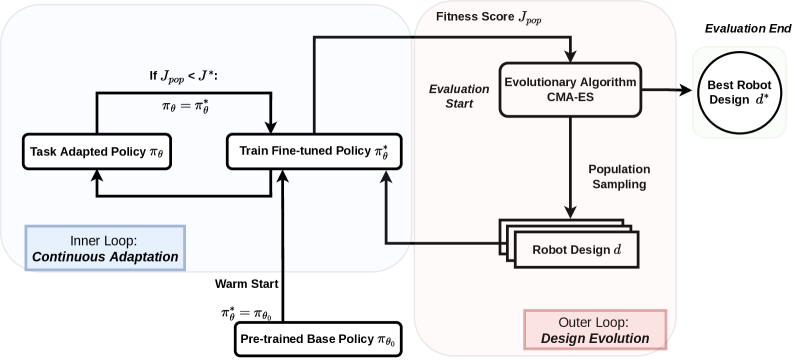
核心思路:论文的核心思路是将进化算法和强化学习相结合,实现硬件设计和控制策略的并行优化。进化算法负责探索硬件设计空间,寻找更优的硬件配置;强化学习则负责在每个硬件配置下,持续优化控制策略,使其能够充分利用当前硬件的性能。通过这种协同优化方式,可以克服传统方法的局限性,实现机器人性能的最大化。
技术框架:EA-CoRL框架包含两个主要模块:设计进化和策略连续适应。设计进化模块使用进化算法(例如遗传算法)来搜索硬件参数空间,生成不同的硬件设计方案。策略连续适应模块则使用强化学习算法,针对每个硬件设计方案训练一个控制策略。在进化过程中,每个个体(硬件设计方案)的适应度由其对应的控制策略在特定任务上的性能决定。通过不断迭代进化和策略优化,最终找到最优的硬件设计和控制策略组合。
关键创新:EA-CoRL的关键创新在于实现了控制策略对硬件的“连续适应”。传统的协同设计方法通常是离散的,即针对一组固定的硬件设计训练一个控制策略。而EA-CoRL则允许控制策略在硬件设计进化的过程中不断调整和优化,从而更好地适应硬件的变化。这种连续适应能力使得EA-CoRL能够更有效地探索设计空间,找到更优的硬件和控制策略组合。
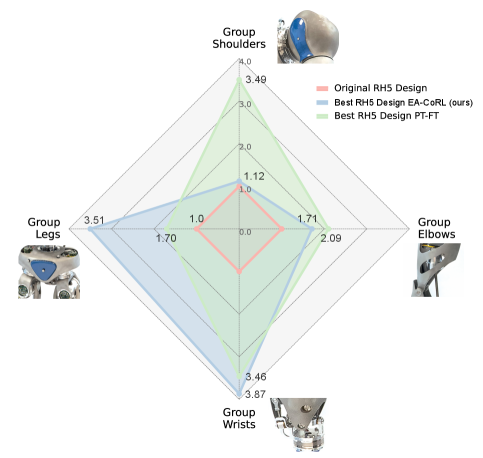
关键设计:在实验中,论文使用遗传算法作为进化算法,并使用强化学习算法(具体算法未知)来训练控制策略。关键设计包括:1) 适应度函数的设计,用于评估每个硬件设计方案的性能;2) 进化算法的参数设置,例如种群大小、交叉率和变异率;3) 强化学习算法的参数设置,例如学习率、折扣因子和探索策略。论文针对RH5人形机器人的引体向上任务,对执行器的齿轮比进行了协同设计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,EA-CoRL在RH5人形机器人的引体向上任务中,相比于现有的基于RL的协同设计方法,实现了更高的适应度分数和更广泛的设计空间探索。具体性能数据未知,但论文强调了EA-CoRL在探索更优硬件设计方面的优势,证明了连续策略适应在机器人协同设计中的重要性。
🎯 应用场景
该研究成果可应用于各种机器人系统的协同设计,尤其是在需要高性能和高动态性的场景中,例如人形机器人、四足机器人、无人机等。通过EA-CoRL框架,可以优化机器人的硬件设计和控制策略,提高其运动能力、能源效率和任务完成能力。此外,该方法还可以应用于机器人辅助康复、智能制造等领域,具有广阔的应用前景。
📄 摘要(原文)
Humanoid robots have seen significant advancements in both design and control, with a growing emphasis on integrating these aspects to enhance overall performance. Traditionally, robot design has followed a sequential process, where control algorithms are developed after the hardware is finalized. However, this can be myopic and prevent robots to fully exploit their hardware capabilities. Recent approaches advocate for co-design, optimizing both design and control in parallel to maximize robotic capabilities. This paper presents the Evolutionary Continuous Adaptive RL-based Co-Design (EA-CoRL) framework, which combines reinforcement learning (RL) with evolutionary strategies to enable continuous adaptation of the control policy to the hardware. EA-CoRL comprises two key components: Design Evolution, which explores the hardware choices using an evolutionary algorithm to identify efficient configurations, and Policy Continuous Adaptation, which fine-tunes a task-specific control policy across evolving designs to maximize performance rewards. We evaluate EA-CoRL by co-designing the actuators (gear ratios) and control policy of the RH5 humanoid for a highly dynamic chin-up task, previously unfeasible due to actuator limitations. Comparative results against state-of-the-art RL-based co-design methods show that EA-CoRL achieves higher fitness score and broader design space exploration, highlighting the critical role of continuous policy adaptation in robot co-design.