SAC Flow: Sample-Efficient Reinforcement Learning of Flow-Based Policies via Velocity-Reparameterized Sequential Modeling
作者: Yixian Zhang, Shu'ang Yu, Tonghe Zhang, Mo Guang, Haojia Hui, Kaiwen Long, Yu Wang, Chao Yu, Wenbo Ding
分类: cs.RO, cs.LG
发布日期: 2025-09-30 (更新: 2026-01-14)
💡 一句话要点
提出SAC Flow算法,通过速度重参数化建模,提升Flow-based策略在强化学习中的样本效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 Flow-based策略 离线强化学习 速度重参数化 序列模型
📋 核心要点
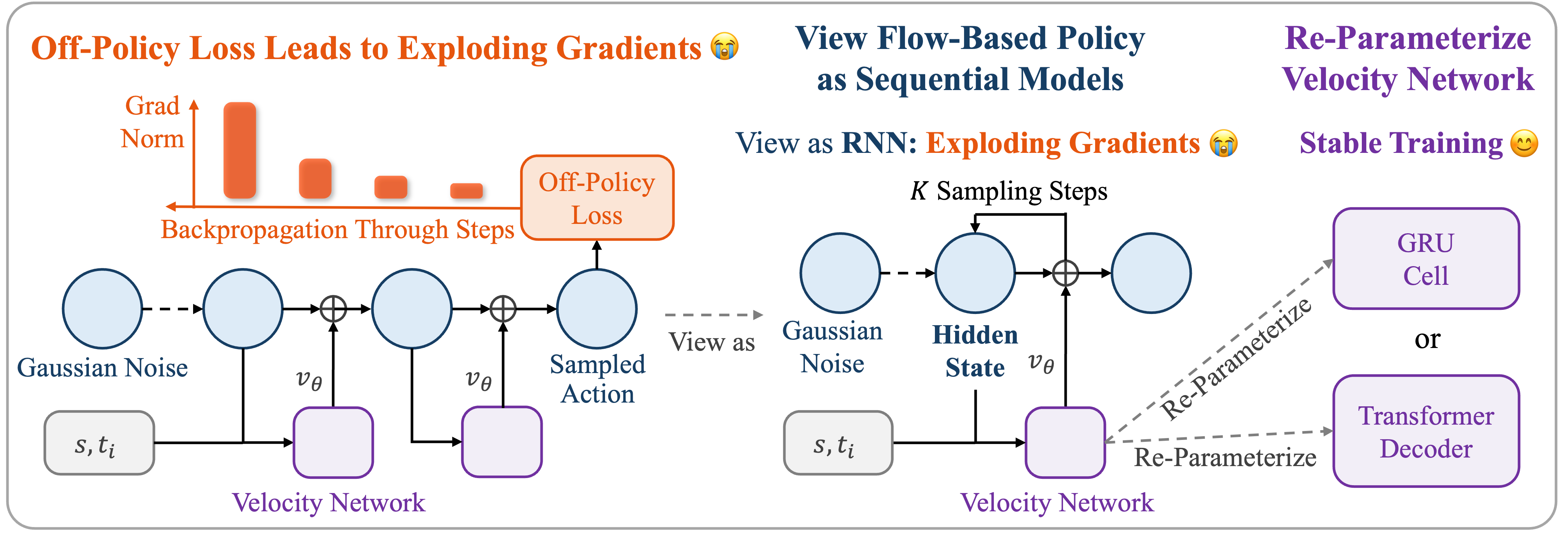
- Flow-based策略在离线强化学习中训练时,由于梯度问题导致训练不稳定,限制了其应用。
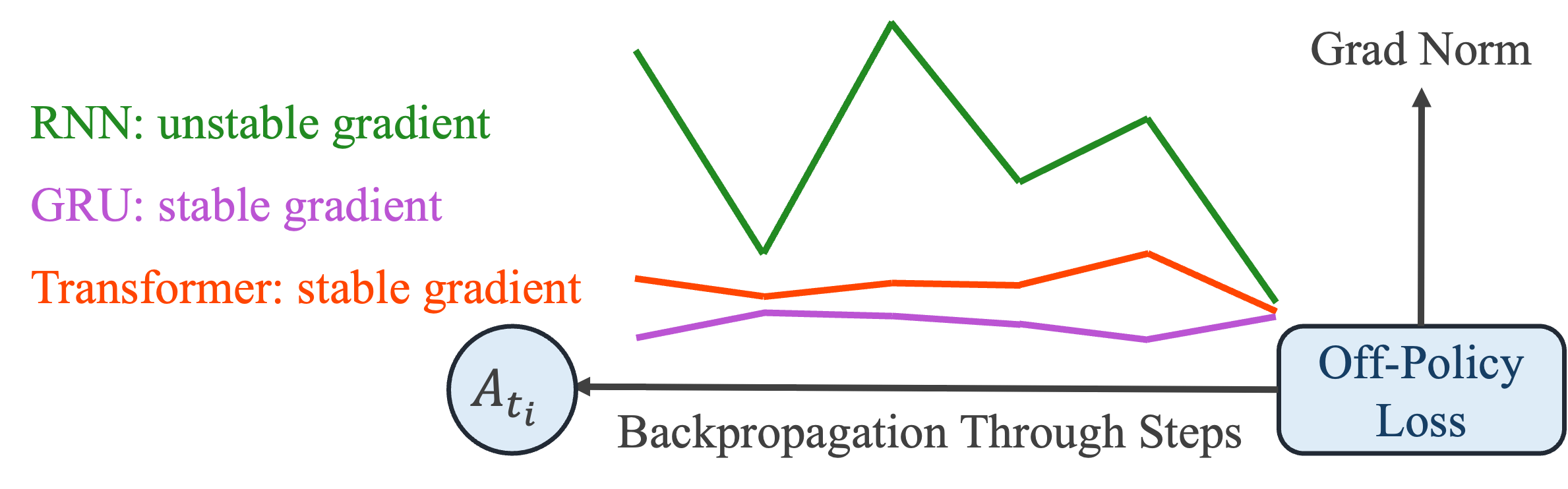
- 通过将Flow展开等价于残差循环计算,并借鉴现代序列模型,对速度网络进行重参数化,提出Flow-G和Flow-T两种稳定架构。
- 开发了基于SAC的算法,通过噪声增强的展开实现端到端训练,在连续控制和机器人操作任务上取得了SOTA性能。
📝 摘要(中文)
由于多步动作采样过程中的梯度病理,使用离线强化学习训练富有表现力的基于Flow的策略非常不稳定。本文将这种不稳定性追溯到一个根本联系:Flow的展开在代数上等价于残差循环计算,使其容易受到与RNN相同的梯度消失和爆炸的影响。为了解决这个问题,本文利用现代序列模型的原理对速度网络进行重参数化,引入了两种稳定的架构:Flow-G(包含门控速度)和Flow-T(利用解码速度)。然后,本文开发了一种基于SAC的实用算法,通过噪声增强的展开来实现这些策略的直接端到端训练。该方法支持从头开始学习和离线到在线学习,并在连续控制和机器人操作基准测试中实现了最先进的性能,无需策略蒸馏或代理目标等常见方法。
🔬 方法详解
问题定义:现有方法在离线强化学习中训练基于Flow的策略时,由于多步动作采样过程中的梯度病理,训练过程非常不稳定。这种不稳定性源于Flow的展开在代数上等价于残差循环计算,因此容易受到RNN中常见的梯度消失和梯度爆炸问题的影响。这限制了Flow-based策略在强化学习中的应用,尤其是在样本效率至关重要的场景下。
核心思路:本文的核心思路是通过对速度网络进行重参数化,使其训练更加稳定。借鉴现代序列模型的思想,设计了两种新的Flow架构:Flow-G和Flow-T。Flow-G通过引入门控机制来控制速度的更新,而Flow-T则利用解码后的速度。这种重参数化使得Flow网络能够更有效地学习,并避免梯度问题。
技术框架:SAC Flow算法基于Soft Actor-Critic (SAC) 框架,并在此基础上集成了Flow-based策略。整体流程包括:1) 使用离线数据集训练Q函数和Flow-based策略;2) 使用SAC算法进行策略优化,其中策略由Flow网络表示;3) 通过噪声增强的Flow rollout进行动作采样,以提高探索能力和训练稳定性。该框架支持从头开始学习和离线到在线学习。
关键创新:本文最重要的技术创新在于对Flow网络的速度进行重参数化,使其能够稳定地进行训练。通过将Flow展开与残差循环计算联系起来,并借鉴现代序列模型的思想,提出了Flow-G和Flow-T两种新的Flow架构。这种重参数化方法有效地解决了Flow-based策略在离线强化学习中训练不稳定的问题。
关键设计:Flow-G使用门控机制来控制速度的更新,具体来说,使用一个门控单元来决定是否更新速度。Flow-T则使用一个解码器网络将隐状态解码为速度。在训练过程中,使用噪声增强的Flow rollout进行动作采样,以提高探索能力和训练稳定性。损失函数包括SAC算法中的策略损失和Q函数损失。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SAC Flow算法在连续控制和机器人操作基准测试中取得了最先进的性能。与现有的方法相比,SAC Flow算法在样本效率和最终性能方面都有显著提升。例如,在某些任务上,SAC Flow算法的性能超过了现有方法的50%以上,并且所需的训练样本数量更少。
🎯 应用场景
该研究成果可应用于各种需要高样本效率的强化学习任务,例如机器人控制、自动驾驶、游戏AI等。通过使用离线数据进行预训练,可以显著减少在线探索所需的样本数量,从而加速强化学习算法的收敛速度。此外,该方法还可以应用于需要复杂策略表达的任务,例如机器人操作和复杂环境下的导航。
📄 摘要(原文)
Training expressive flow-based policies with off-policy reinforcement learning is notoriously unstable due to gradient pathologies in the multi-step action sampling process. We trace this instability to a fundamental connection: the flow rollout is algebraically equivalent to a residual recurrent computation, making it susceptible to the same vanishing and exploding gradients as RNNs. To address this, we reparameterize the velocity network using principles from modern sequential models, introducing two stable architectures: Flow-G, which incorporates a gated velocity, and Flow-T, which utilizes a decoded velocity. We then develop a practical SAC-based algorithm, enabled by a noise-augmented rollout, that facilitates direct end-to-end training of these policies. Our approach supports both from-scratch and offline-to-online learning and achieves state-of-the-art performance on continuous control and robotic manipulation benchmarks, eliminating the need for common workarounds like policy distillation or surrogate objectives.