Best of Sim and Real: Decoupled Visuomotor Manipulation via Learning Control in Simulation and Perception in Real
作者: Jialei Huang, Zhaoheng Yin, Yingdong Hu, Shuo Wang, Xingyu Lin, Yang Gao
分类: cs.RO
发布日期: 2025-09-30
备注: 10 pages, 6 figures
💡 一句话要点
提出解耦的视觉运动操作框架,提升Sim-to-Real迁移性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: Sim-to-Real 机器人操作 解耦学习 视觉运动 强化学习
📋 核心要点
- 端到端学习方法在机器人操作的Sim-to-Real迁移中,感知和控制相互纠缠,导致泛化性差,需要大量真实数据。
- 提出解耦框架,在仿真中学习控制策略,在真实环境中学习感知,利用各自优势,降低对真实数据的依赖。
- 实验表明,该方法仅需少量真实数据即可实现优异的性能,并在超出训练分布的情况下表现出良好的泛化能力。
📝 摘要(中文)
本文提出了一种解耦框架,用于解决机器人操作中的Sim-to-Real迁移问题。该框架在仿真环境中利用特权状态训练控制策略,掌握空间布局和操作动力学;在真实环境中,仅调整感知模块,将真实观测对齐到冻结的控制策略。核心思想是控制策略和动作模式具有通用性,可以通过系统随机化在仿真环境中学习,而感知具有领域特定性,必须在真实的视觉观测中学习。与需要大量真实世界数据的端到端方法不同,该方法通过将复杂的Sim-to-Real问题简化为结构化的感知对齐任务,仅需10-20个真实演示即可实现强大的性能。在桌面操作任务上的验证表明,该方法在数据效率和超出分布泛化方面优于端到端基线。学习到的策略能够成功处理超出训练分布的物体位置和尺度,证实了解耦感知和控制从根本上改善了Sim-to-Real迁移。
🔬 方法详解
问题定义:现有端到端方法在机器人操作的Sim-to-Real迁移中,感知和控制模块耦合紧密,导致模型难以泛化到真实环境。真实数据获取成本高昂,仿真数据与真实数据存在差异,直接训练的模型难以适应真实场景的变化。因此,如何高效地利用仿真数据,并减少对真实数据的依赖,是亟待解决的问题。
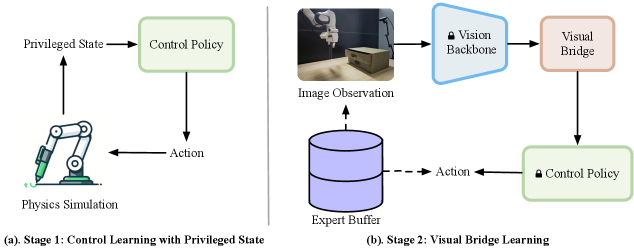
核心思路:论文的核心思路是将感知和控制解耦。控制策略在仿真环境中学习,利用仿真环境的特权状态信息,学习通用的操作策略和动作模式。感知模块则专注于将真实世界的视觉观测映射到控制策略所需的输入空间。这样,控制策略无需关注具体的视觉细节,而感知模块则专注于弥合仿真和真实环境之间的视觉差异。
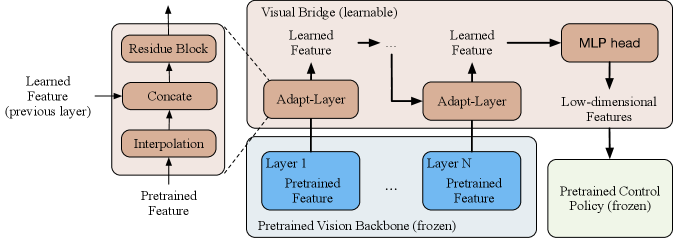
技术框架:整体框架包含两个主要部分:仿真环境中的控制策略学习和真实环境中的感知模块学习。首先,在仿真环境中,通过强化学习或模仿学习训练控制策略,目标是学习在不同空间布局和动力学条件下的操作技能。然后,在真实环境中,利用少量真实数据训练感知模块,将真实图像转换为控制策略可以理解的状态表示。最后,将训练好的控制策略和感知模块组合起来,实现机器人在真实环境中的操作。
关键创新:最重要的创新点在于解耦感知和控制。传统方法通常将感知和控制作为一个整体进行学习,导致模型难以泛化。通过解耦,控制策略可以专注于学习通用的操作技能,而感知模块可以专注于适应真实环境的视觉特征。这种解耦使得模型更加模块化,易于维护和扩展。
关键设计:在仿真环境中,采用系统随机化方法,增加环境的多样性,提高控制策略的鲁棒性。在真实环境中,使用少量真实数据进行微调,以适应真实环境的视觉特征。感知模块可以使用各种图像处理和深度学习技术,例如卷积神经网络,将真实图像转换为状态表示。损失函数的设计需要考虑控制策略的需求,例如,可以使用控制策略的预测误差作为感知模块的损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在桌面操作任务上取得了显著的性能提升。与端到端基线方法相比,该方法仅需10-20个真实演示即可达到甚至超过其性能。此外,该方法在超出训练分布的物体位置和尺度上表现出更好的泛化能力,验证了解耦感知和控制的有效性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过利用仿真数据和少量真实数据,可以快速训练出能够在真实环境中稳定工作的机器人操作系统。该方法降低了对大量真实数据的依赖,降低了机器人部署的成本和难度,加速了机器人技术在各个领域的应用。
📄 摘要(原文)
Sim-to-real transfer remains a fundamental challenge in robot manipulation due to the entanglement of perception and control in end-to-end learning. We present a decoupled framework that learns each component where it is most reliable: control policies are trained in simulation with privileged state to master spatial layouts and manipulation dynamics, while perception is adapted only at deployment to bridge real observations to the frozen control policy. Our key insight is that control strategies and action patterns are universal across environments and can be learned in simulation through systematic randomization, while perception is inherently domain-specific and must be learned where visual observations are authentic. Unlike existing end-to-end approaches that require extensive real-world data, our method achieves strong performance with only 10-20 real demonstrations by reducing the complex sim-to-real problem to a structured perception alignment task. We validate our approach on tabletop manipulation tasks, demonstrating superior data efficiency and out-of-distribution generalization compared to end-to-end baselines. The learned policies successfully handle object positions and scales beyond the training distribution, confirming that decoupling perception from control fundamentally improves sim-to-real transfer.