AIRoA MoMa Dataset: A Large-Scale Hierarchical Dataset for Mobile Manipulation
作者: Ryosuke Takanami, Petr Khrapchenkov, Shu Morikuni, Jumpei Arima, Yuta Takaba, Shunsuke Maeda, Takuya Okubo, Genki Sano, Satoshi Sekioka, Aoi Kadoya, Motonari Kambara, Naoya Nishiura, Haruto Suzuki, Takanori Yoshimoto, Koya Sakamoto, Shinnosuke Ono, Hu Yang, Daichi Yashima, Aoi Horo, Tomohiro Motoda, Kensuke Chiyoma, Hiroshi Ito, Koki Fukuda, Akihito Goto, Kazumi Morinaga, Yuya Ikeda, Riko Kawada, Masaki Yoshikawa, Norio Kosuge, Yuki Noguchi, Kei Ota, Tatsuya Matsushima, Yusuke Iwasawa, Yutaka Matsuo, Tetsuya Ogata
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-09-29
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
AIRoA MoMa:用于移动操作的大规模分层数据集,助力通用机器人
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动操作 机器人数据集 多模态学习 分层注释 力矩感知
📋 核心要点
- 现有移动操作数据集缺乏同步力矩感知、分层注释和显式失败案例,限制了通用机器人的发展。
- AIRoA MoMa数据集通过提供大规模、多模态、分层注释的数据,促进机器人学习复杂操作任务。
- 该数据集包含94小时的真实世界数据,为视觉-语言-动作模型的训练和评估提供了关键资源。
📝 摘要(中文)
本文提出了AIRoA MoMa数据集,这是一个大规模的真实世界多模态数据集,专为移动操作任务设计。该数据集旨在解决当前机器人从受控环境过渡到非结构化人类环境时,难以可靠地遵循自然语言指令这一核心挑战。AIRoA MoMa数据集包含同步的RGB图像、关节状态、六轴腕部力矩信号和内部机器人状态,并采用了一种新颖的双层注释模式,包括子目标和原始动作,用于分层学习和错误分析。初始数据集包含25469个episode(约94小时),使用Human Support Robot (HSR)收集,并完全标准化为LeRobot v2.1格式。通过独特地整合移动操作、富接触交互和长时程结构,AIRoA MoMa为推进下一代视觉-语言-动作模型提供了一个关键的基准。
🔬 方法详解
问题定义:当前移动操作领域面临的挑战是,机器人难以在非结构化的人类环境中可靠地执行自然语言指令。现有的数据集通常缺乏关键信息,例如同步的力矩数据,这对于理解和控制接触力至关重要。此外,缺乏分层注释使得难以进行有效的学习和错误分析,而对失败案例的忽略则阻碍了机器人鲁棒性的提升。
核心思路:AIRoA MoMa数据集的核心思路是通过提供一个大规模、多模态、分层注释的数据集,来弥补现有数据集的不足,从而促进通用机器人的发展。该数据集旨在捕捉移动操作中的富接触交互和长时程结构,并提供详细的机器人状态信息,以便进行更深入的学习和分析。
技术框架:AIRoA MoMa数据集的整体框架包括数据采集、数据标注和数据发布三个主要阶段。数据采集使用Human Support Robot (HSR)在真实世界环境中进行,同步记录RGB图像、关节状态、六轴腕部力矩信号和内部机器人状态。数据标注采用一种新颖的双层注释模式,包括子目标和原始动作,用于分层学习和错误分析。数据发布采用LeRobot v2.1格式,方便用户使用。
关键创新:AIRoA MoMa数据集的关键创新在于其独特地整合了移动操作、富接触交互和长时程结构。与现有数据集相比,AIRoA MoMa数据集提供了更全面的信息,包括同步的力矩数据、分层注释和显式失败案例,这使得可以进行更深入的学习和分析。此外,AIRoA MoMa数据集的规模也远大于现有数据集,这为训练更强大的视觉-语言-动作模型提供了可能。
关键设计:AIRoA MoMa数据集的关键设计包括:1) 使用HSR机器人进行数据采集,保证了数据的真实性和多样性;2) 采用双层注释模式,方便进行分层学习和错误分析;3) 使用LeRobot v2.1格式,方便用户使用;4) 数据集规模达到94小时,保证了数据的充足性。
🖼️ 关键图片

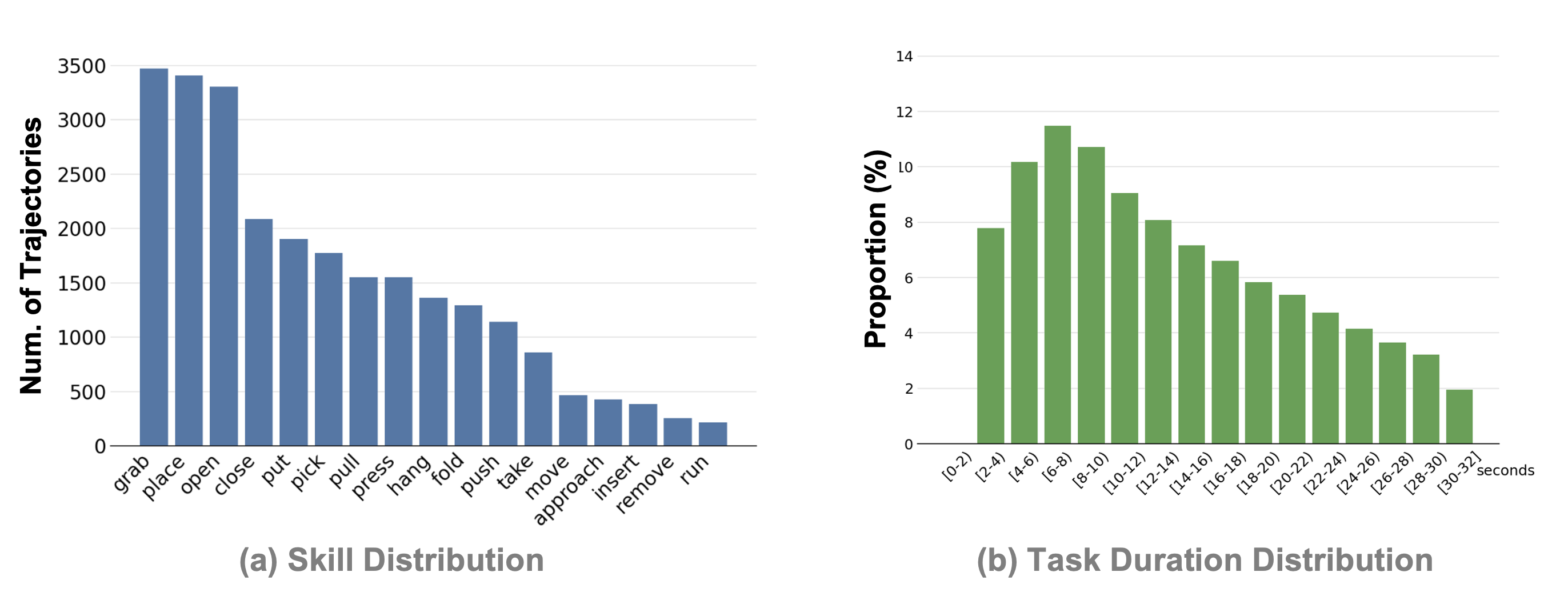
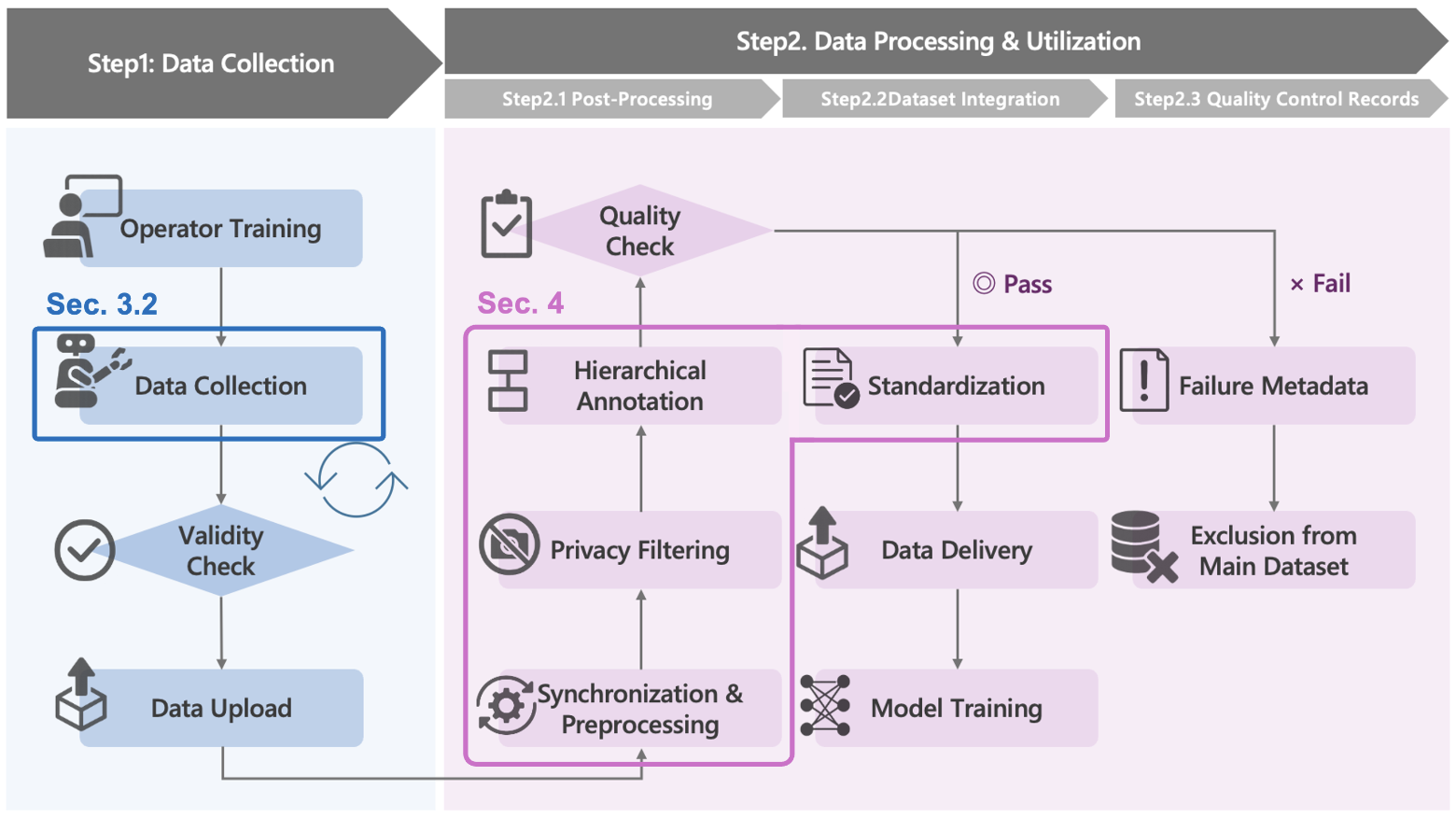
📊 实验亮点
AIRoA MoMa数据集包含25469个episode,总时长约94小时,是目前最大的移动操作数据集之一。该数据集提供了同步的RGB图像、关节状态、六轴腕部力矩信号和内部机器人状态,并采用了一种新颖的双层注释模式。与现有数据集相比,AIRoA MoMa数据集在数据规模、数据质量和注释信息方面都具有显著优势。
🎯 应用场景
AIRoA MoMa数据集可广泛应用于机器人操作、人机交互、视觉-语言导航等领域。该数据集能够促进通用机器人的发展,使其能够更好地理解人类指令,并在复杂环境中执行各种任务。例如,可以应用于家庭服务机器人、医疗辅助机器人、工业自动化等场景,提高机器人的智能化水平和服务能力。
📄 摘要(原文)
As robots transition from controlled settings to unstructured human environments, building generalist agents that can reliably follow natural language instructions remains a central challenge. Progress in robust mobile manipulation requires large-scale multimodal datasets that capture contact-rich and long-horizon tasks, yet existing resources lack synchronized force-torque sensing, hierarchical annotations, and explicit failure cases. We address this gap with the AIRoA MoMa Dataset, a large-scale real-world multimodal dataset for mobile manipulation. It includes synchronized RGB images, joint states, six-axis wrist force-torque signals, and internal robot states, together with a novel two-layer annotation schema of sub-goals and primitive actions for hierarchical learning and error analysis. The initial dataset comprises 25,469 episodes (approx. 94 hours) collected with the Human Support Robot (HSR) and is fully standardized in the LeRobot v2.1 format. By uniquely integrating mobile manipulation, contact-rich interaction, and long-horizon structure, AIRoA MoMa provides a critical benchmark for advancing the next generation of Vision-Language-Action models. The first version of our dataset is now available at https://huggingface.co/datasets/airoa-org/airoa-moma .