Annotation-Free One-Shot Imitation Learning for Multi-Step Manipulation Tasks
作者: Vijja Wichitwechkarn, Emlyn Williams, Charles Fox, Ruchi Choudhary
分类: cs.RO
发布日期: 2025-09-29
💡 一句话要点
提出一种免标注的单样本模仿学习方法,用于多步操作任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 单样本模仿学习 多步操作任务 免标注学习 机器人操作 视觉特征提取
📋 核心要点
- 现有单样本模仿学习方法难以处理长时程多步操作任务,需要额外训练或标注。
- 该方法通过单次演示学习多步操作,无需额外训练或人工标注,提升泛化能力。
- 实验表明,该方法在多步和单步任务中均表现出色,成功率分别达到82.5%和90%。
📝 摘要(中文)
本文提出了一种免标注的单样本模仿学习方法,旨在使机器人能够仅通过一次人类演示学习新的操作技能。现有方法在单步任务上表现出色,但在处理长时程、多步任务时,若没有额外的模型训练或手动标注,则能力受限。本文提出的方法无需额外训练或手动标注,即可应用于多步任务。在多步和单步操作任务上的评估结果表明,该方法分别实现了82.5%和90%的平均成功率,与基线方法相比,性能相当甚至更优。此外,本文还比较了框架内不同预训练特征提取器的性能和计算效率。
🔬 方法详解
问题定义:现有单样本模仿学习方法在处理多步操作任务时,需要大量的额外训练数据或者人工标注,这限制了其在实际场景中的应用。论文旨在解决在仅有单次演示的情况下,如何让机器人学会执行复杂的多步操作任务,而无需额外的模型训练或人工标注。现有方法的痛点在于泛化能力不足,难以适应新的环境和任务。
核心思路:论文的核心思路是利用预训练的视觉特征提取器,将人类演示和机器人执行过程中的视觉信息进行编码,然后通过模仿学习算法,学习人类的操作策略。关键在于如何有效地利用单次演示中的信息,并将其泛化到新的场景中。通过避免额外的训练和标注,提高了算法的实用性和效率。
技术框架:整体框架包含以下几个主要模块:1) 视觉特征提取模块:使用预训练的卷积神经网络(CNN)提取图像特征。2) 轨迹编码模块:将人类演示的轨迹编码成一个紧凑的表示。3) 模仿学习模块:利用模仿学习算法,学习从视觉特征到动作的映射关系。4) 动作执行模块:将学习到的动作应用到机器人上,完成操作任务。
关键创新:该方法最重要的创新点在于它能够在没有额外训练或人工标注的情况下,仅通过单次演示学习多步操作任务。与现有方法相比,该方法更加高效和实用,因为它避免了耗时的数据收集和标注过程。此外,论文还比较了不同预训练特征提取器的性能,为实际应用提供了指导。
关键设计:论文的关键设计包括:1) 使用预训练的视觉特征提取器,例如ResNet或VGG,以提高特征的泛化能力。2) 设计合适的轨迹编码方法,例如动态时间规整(DTW)或隐马尔可夫模型(HMM),以捕捉人类演示中的时序信息。3) 使用模仿学习算法,例如行为克隆(Behavior Cloning)或逆强化学习(Inverse Reinforcement Learning),学习从视觉特征到动作的映射关系。4) 仔细调整模仿学习算法的参数,例如学习率、批大小等,以获得最佳性能。
🖼️ 关键图片

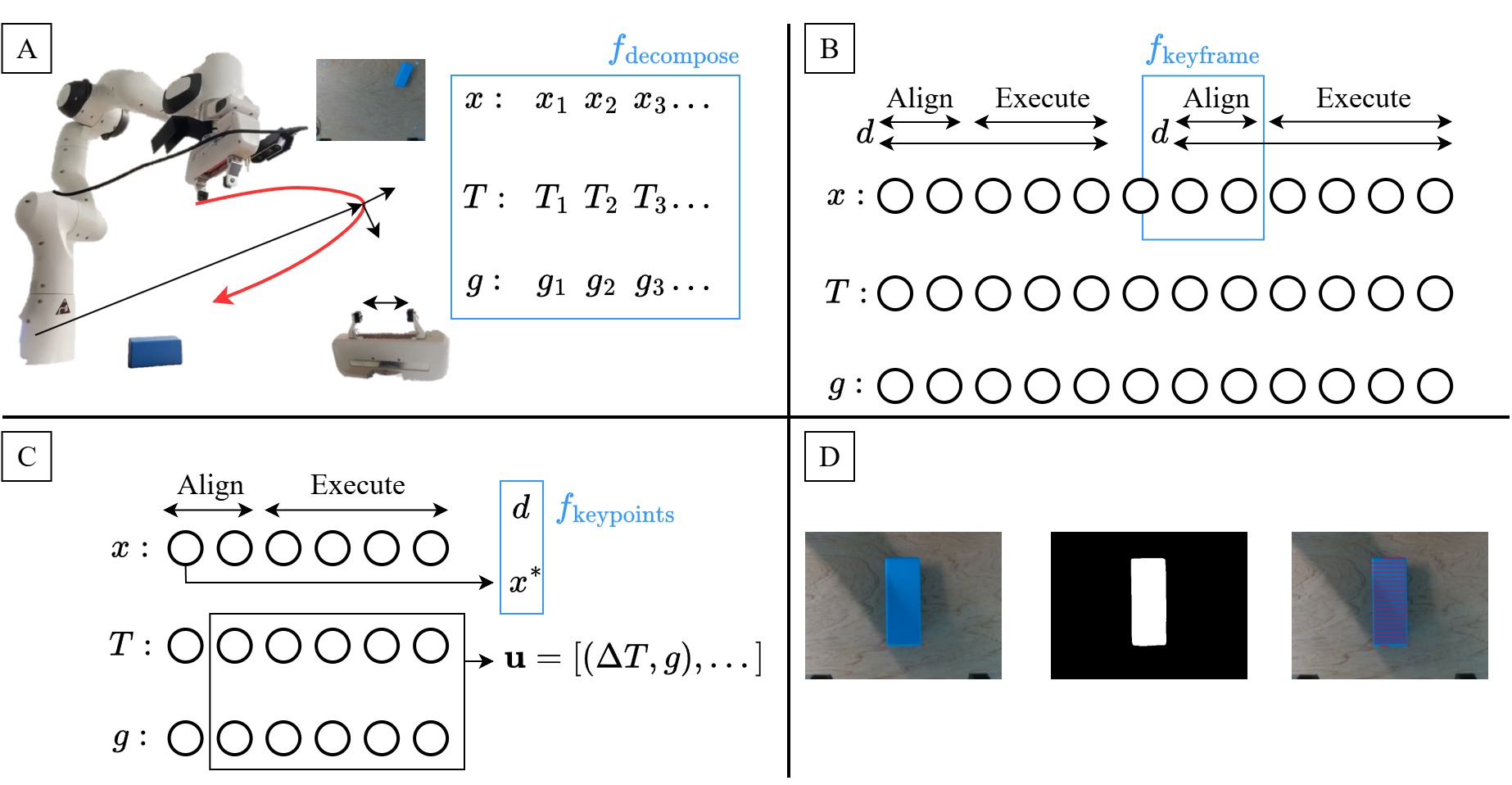

📊 实验亮点
实验结果表明,该方法在多步操作任务中取得了82.5%的平均成功率,在单步操作任务中取得了90%的平均成功率。与基线方法相比,该方法在两种任务中均表现出相当甚至更优的性能。此外,论文还比较了不同预训练特征提取器的性能和计算效率,为实际应用提供了有价值的参考。
🎯 应用场景
该研究成果可应用于各种需要机器人进行复杂操作的场景,例如:智能制造、医疗手术、家庭服务等。在智能制造中,机器人可以学习执行装配、搬运等任务;在医疗手术中,机器人可以辅助医生进行精准操作;在家庭服务中,机器人可以帮助人们完成家务。该研究具有重要的实际价值和广阔的应用前景,有望推动机器人技术的发展。
📄 摘要(原文)
Recent advances in one-shot imitation learning have enabled robots to acquire new manipulation skills from a single human demonstration. While existing methods achieve strong performance on single-step tasks, they remain limited in their ability to handle long-horizon, multi-step tasks without additional model training or manual annotation. We propose a method that can be applied to this setting provided a single demonstration without additional model training or manual annotation. We evaluated our method on multi-step and single-step manipulation tasks where our method achieves an average success rate of 82.5% and 90%, respectively. Our method matches and exceeds the performance of the baselines in both these cases. We also compare the performance and computational efficiency of alternative pre-trained feature extractors within our framework.