From Code to Action: Hierarchical Learning of Diffusion-VLM Policies
作者: Markus Peschl, Pietro Mazzaglia, Daniel Dijkman
分类: cs.RO, cs.LG
发布日期: 2025-09-29
备注: 19 pages including references, 6 figures. Accepted to CoRL LEAP 2025
💡 一句话要点
提出基于扩散-VLM策略的分层学习框架,提升机器人操作模仿学习的泛化性和数据效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 视觉语言模型 扩散模型 分层学习
📋 核心要点
- 机器人操作模仿学习面临泛化能力有限和数据稀缺的挑战,尤其是在复杂的长时程任务中。
- 论文提出一种分层框架,利用视觉语言模型生成代码,并结合扩散策略来模仿机器人行为,从而实现任务分解和泛化。
- 实验表明,该方法能够实现可解释的策略分解,提高泛化能力,并支持对高级规划和低级控制的独立评估。
📝 摘要(中文)
本文提出了一种分层框架,该框架利用代码生成的视觉语言模型(VLM)与低级扩散策略相结合,以有效地模仿和泛化机器人行为。核心思想是将开源机器人API不仅视为执行接口,还视为结构化监督的来源:相关的子任务函数(如果公开)可以作为模块化的、语义上有意义的标签。我们训练VLM将任务描述分解为可执行的子程序,然后通过训练扩散策略来模仿相应的机器人行为,从而实现子程序的落地执行。为了处理代码执行和某些现实世界任务(如对象交换)的非马尔可夫性质,我们的架构包含一种记忆机制,用于维护跨时间的子任务上下文。结果表明,这种设计能够实现可解释的策略分解,与扁平策略相比提高了泛化能力,并能够对高级规划和低级控制进行单独评估。
🔬 方法详解
问题定义:机器人操作的模仿学习任务,特别是在长时程任务中,面临着泛化能力不足和数据稀缺的问题。现有的方法通常难以处理复杂任务的分解和非马尔可夫性质,导致策略难以泛化到新的场景和任务。
核心思路:论文的核心思路是将任务分解为可执行的子程序,并利用视觉语言模型(VLM)生成这些子程序的代码。然后,通过训练扩散策略来模仿每个子程序的机器人行为。这种分层的方法可以提高策略的可解释性和泛化能力,并允许对高级规划和低级控制进行独立评估。
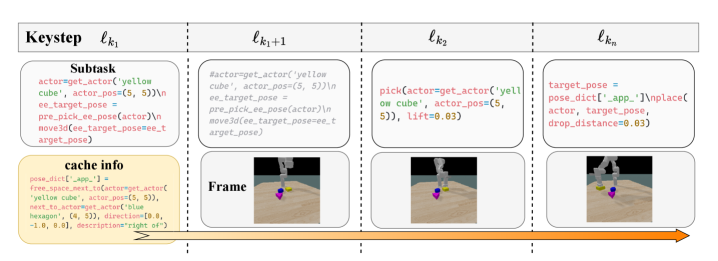
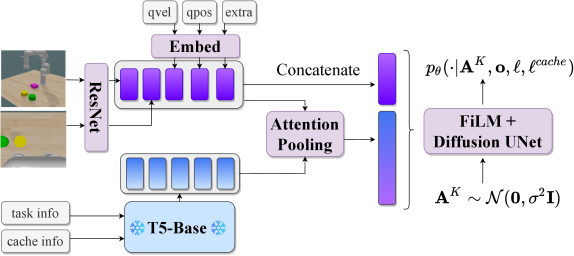
技术框架:该框架包含两个主要模块:1) VLM代码生成器:将任务描述分解为一系列可执行的子程序代码。2) 扩散策略:根据VLM生成的代码,控制机器人执行相应的动作。此外,为了处理非马尔可夫性质,该框架还包含一个记忆模块,用于维护子任务的上下文信息。整体流程是:给定任务描述,VLM生成子程序代码,然后扩散策略根据代码和上下文信息控制机器人执行动作,并更新记忆模块。
关键创新:该方法最重要的创新点在于将开源机器人API视为结构化监督的来源,利用API中的子任务函数作为语义标签来训练VLM。这使得VLM能够生成更准确和可执行的代码,从而提高了策略的泛化能力。与传统的扁平策略相比,该方法能够实现可解释的策略分解,并允许对高级规划和低级控制进行独立评估。
关键设计:VLM使用预训练的视觉语言模型,并针对机器人操作任务进行微调。扩散策略使用条件扩散模型,以VLM生成的代码和上下文信息作为条件。记忆模块使用循环神经网络(RNN)来维护子任务的上下文信息。损失函数包括VLM的代码生成损失和扩散策略的模仿学习损失。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在机器人操作任务中取得了显著的性能提升。与扁平策略相比,该方法能够实现更好的泛化能力和更高的成功率。此外,实验还验证了该方法能够实现可解释的策略分解,并允许对高级规划和低级控制进行独立评估。具体的性能数据和对比基线在论文中有详细展示。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如自动化装配、物体抓取和放置、以及更复杂的长时程任务。通过利用视觉语言模型和分层学习,可以显著提高机器人的自主性和适应性,降低对人工干预的依赖,从而在工业自动化、服务机器人等领域具有广泛的应用前景。
📄 摘要(原文)
Imitation learning for robotic manipulation often suffers from limited generalization and data scarcity, especially in complex, long-horizon tasks. In this work, we introduce a hierarchical framework that leverages code-generating vision-language models (VLMs) in combination with low-level diffusion policies to effectively imitate and generalize robotic behavior. Our key insight is to treat open-source robotic APIs not only as execution interfaces but also as sources of structured supervision: the associated subtask functions - when exposed - can serve as modular, semantically meaningful labels. We train a VLM to decompose task descriptions into executable subroutines, which are then grounded through a diffusion policy trained to imitate the corresponding robot behavior. To handle the non-Markovian nature of both code execution and certain real-world tasks, such as object swapping, our architecture incorporates a memory mechanism that maintains subtask context across time. We find that this design enables interpretable policy decomposition, improves generalization when compared to flat policies and enables separate evaluation of high-level planning and low-level control.