CEDex: Cross-Embodiment Dexterous Grasp Generation at Scale from Human-like Contact Representations
作者: Zhiyuan Wu, Rolandos Alexandros Potamias, Xuyang Zhang, Zhongqun Zhang, Jiankang Deng, Shan Luo
分类: cs.RO, cs.CV
发布日期: 2025-09-29
💡 一句话要点
提出CEDex以解决跨躯体灵巧抓取生成问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting)
关键词: 跨躯体抓取 灵巧抓取 条件变分自编码器 机器人运动学 数据集构建 物理约束 抓取优化
📋 核心要点
- 现有方法在生成灵巧抓取时缺乏人类运动学理解,且手动数据收集过程繁琐且局限于类人结构。
- CEDex通过将机器人运动学与人类接触表示对齐,利用条件变分自编码器生成接触表示,从而实现灵巧抓取合成。
- CEDex构建了500K个物体和20M个抓取的跨躯体抓取数据集,实验结果显示其性能超过了现有最先进的方法。
📝 摘要(中文)
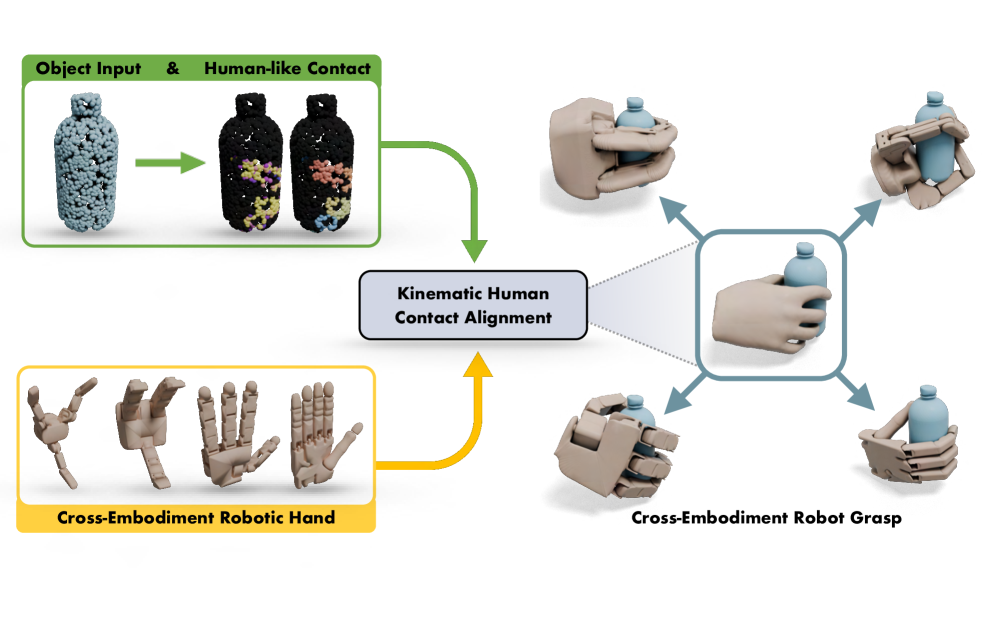
跨躯体灵巧抓取合成是指为不同形态的机器人手适应性地生成和优化抓取。这一能力对于实现多样化的机器人操作至关重要,但现有方法要么依赖缺乏人类运动学理解的物理优化,要么需要大量手动数据收集。本文提出CEDex,一种新颖的跨躯体灵巧抓取合成方法,通过将机器人运动学模型与生成的人类接触表示对齐,解决了这一问题。CEDex构建了迄今为止最大的跨躯体抓取数据集,包含500K个物体和20M个抓取,实验表明其性能优于现有方法。
🔬 方法详解
问题定义:论文要解决的问题是如何为不同形态的机器人手生成灵巧抓取,现有方法在物理优化和数据收集上存在局限性,无法有效适应多样化的抓取需求。
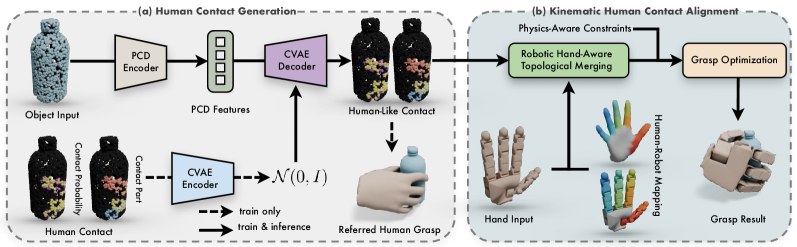
核心思路:CEDex的核心思路是通过对齐机器人运动学模型与生成的人类接触表示,利用条件变分自编码器生成高质量的抓取表示,从而实现跨躯体的抓取合成。
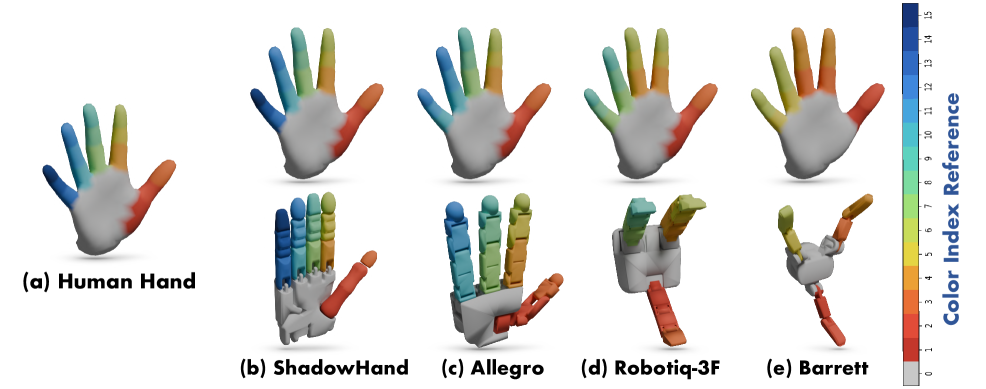
技术框架:CEDex的整体架构包括三个主要模块:首先,利用条件变分自编码器生成基于人类接触的数据;其次,通过拓扑合并实现运动学对齐;最后,基于符号距离场进行抓取优化,确保抓取的物理可行性。
关键创新:CEDex的关键创新在于将人类抓取运动学与机器人抓取模型有效结合,形成了一种新的抓取生成框架,显著提升了抓取的多样性和适应性。
关键设计:在设计上,CEDex采用了条件变分自编码器进行接触表示生成,并通过拓扑合并技术整合多个手部部件,优化过程中引入了物理约束以提高抓取的稳定性。
🖼️ 关键图片
📊 实验亮点
CEDex在实验中表现出色,构建了500K个物体和20M个抓取的跨躯体抓取数据集,性能超过了现有最先进的方法,显示出在抓取多样性和适应性上的显著提升。
🎯 应用场景
CEDex的研究成果在机器人操作、自动化制造、服务机器人等领域具有广泛的应用潜力。通过提供高质量的抓取数据,CEDex能够帮助机器人在复杂环境中实现更灵活的操作,提升其在实际应用中的表现和效率。
📄 摘要(原文)
Cross-embodiment dexterous grasp synthesis refers to adaptively generating and optimizing grasps for various robotic hands with different morphologies. This capability is crucial for achieving versatile robotic manipulation in diverse environments and requires substantial amounts of reliable and diverse grasp data for effective model training and robust generalization. However, existing approaches either rely on physics-based optimization that lacks human-like kinematic understanding or require extensive manual data collection processes that are limited to anthropomorphic structures. In this paper, we propose CEDex, a novel cross-embodiment dexterous grasp synthesis method at scale that bridges human grasping kinematics and robot kinematics by aligning robot kinematic models with generated human-like contact representations. Given an object's point cloud and an arbitrary robotic hand model, CEDex first generates human-like contact representations using a Conditional Variational Auto-encoder pretrained on human contact data. It then performs kinematic human contact alignment through topological merging to consolidate multiple human hand parts into unified robot components, followed by a signed distance field-based grasp optimization with physics-aware constraints. Using CEDex, we construct the largest cross-embodiment grasp dataset to date, comprising 500K objects across four gripper types with 20M total grasps. Extensive experiments show that CEDex outperforms state-of-the-art approaches and our dataset benefits cross-embodiment grasp learning with high-quality diverse grasps.