U-DiT Policy: U-shaped Diffusion Transformers for Robotic Manipulation
作者: Linzhi Wu, Aoran Mei, Xiyue Wang, Guo-Niu Zhu, Zhongxue Gan
分类: cs.RO
发布日期: 2025-09-29
💡 一句话要点
提出U-DiT Policy,融合U-Net和Transformer优势,提升机器人操作任务的扩散策略性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 扩散模型 Transformer U-Net 视觉运动控制 深度学习 策略学习
📋 核心要点
- 现有基于扩散模型的U-Net架构在机器人视觉运动控制中存在全局上下文建模不足和过度平滑的问题。
- U-DiT Policy融合了U-Net的多尺度特征融合和Transformer的全局上下文建模能力,增强表征和策略表达。
- 实验表明,U-DiT在仿真和真实机器人任务中均优于现有方法,泛化性和鲁棒性显著提升。
📝 摘要(中文)
本文提出了一种新的U型扩散Transformer框架,名为U-DiT Policy,用于解决机器人端到端视觉运动控制中,现有基于扩散模型的U-Net架构(DP-U)存在的全局上下文建模能力有限和过度平滑问题。U-DiT保留了U-Net的多尺度特征融合优势,同时集成了Transformer的全局上下文建模能力,从而增强了表征能力和策略表达性。在仿真和真实机器人操作任务中进行了广泛的评估。在仿真中,U-DiT的平均性能比基线方法提高了10%,并且在可比参数预算下,超过了使用AdaLN块的基于Transformer的扩散策略(DP-T)6%。在真实机器人任务中,U-DiT表现出卓越的泛化性和鲁棒性,平均比DP-U提高了22.5%。此外,在干扰和光照变化下的鲁棒性和泛化性实验进一步突出了U-DiT的优势。这些结果突出了U-DiT Policy作为基于扩散的机器人操作新基础的有效性和实际潜力。
🔬 方法详解
问题定义:论文旨在解决机器人操作任务中,现有基于扩散模型的策略(特别是基于U-Net的DP-U)在全局上下文建模方面的不足,以及由此导致的过度平滑问题。这些问题限制了策略的表达能力和泛化性能,尤其是在复杂和动态的环境中。
核心思路:论文的核心思路是将U-Net的多尺度特征融合能力与Transformer的全局上下文建模能力相结合。U-Net擅长提取不同尺度的局部特征,而Transformer能够捕捉长距离依赖关系。通过融合两者的优势,可以构建更强大的策略,从而更好地理解环境并生成更精确的动作。
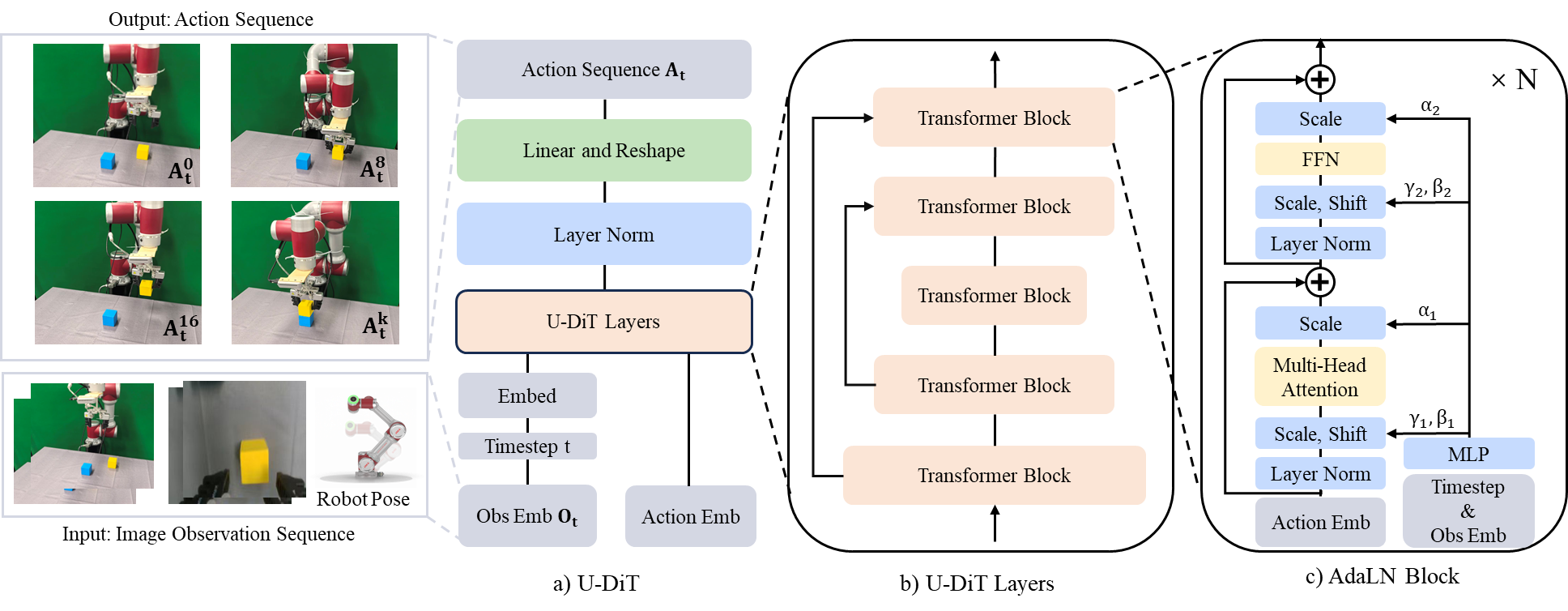
技术框架:U-DiT Policy采用U型架构,类似于U-Net,但其核心构建块是Transformer。编码器部分逐步提取图像特征,并使用Transformer层进行全局上下文建模。解码器部分将特征逐步恢复到原始分辨率,并使用Transformer层进行动作预测。跳跃连接(skip connections)将编码器特征传递到解码器,以保留细节信息。
关键创新:U-DiT的关键创新在于将Transformer引入到U-Net架构中,从而在保留多尺度特征融合的同时,实现了全局上下文建模。与传统的DP-U相比,U-DiT能够更好地理解场景中的长距离依赖关系,从而生成更合理的动作。与纯Transformer架构(DP-T)相比,U-DiT通过U型结构和跳跃连接,更好地保留了局部细节信息。
关键设计:U-DiT使用Transformer块作为其主要构建块,每个Transformer块包含自注意力机制和前馈网络。损失函数通常是预测动作与真实动作之间的均方误差。在训练过程中,使用扩散模型生成噪声数据,并训练模型预测原始数据。具体的参数设置(如Transformer块的数量、注意力头的数量、学习率等)需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
U-DiT在仿真环境中比基线方法平均提升10%,比基于Transformer的扩散策略(DP-T)提升6%。在真实机器人任务中,U-DiT比DP-U平均提升22.5%。在干扰和光照变化下,U-DiT表现出更强的鲁棒性和泛化能力,验证了其在实际应用中的潜力。
🎯 应用场景
U-DiT Policy在机器人操作领域具有广泛的应用前景,例如物体抓取、装配、导航等。它可以应用于工业自动化、家庭服务机器人、医疗机器人等领域,提高机器人的智能化水平和工作效率。该研究的成果有助于推动机器人技术的发展,使其能够更好地适应复杂和动态的环境。
📄 摘要(原文)
Diffusion-based methods have been acknowledged as a powerful paradigm for end-to-end visuomotor control in robotics. Most existing approaches adopt a Diffusion Policy in U-Net architecture (DP-U), which, while effective, suffers from limited global context modeling and over-smoothing artifacts. To address these issues, we propose U-DiT Policy, a novel U-shaped Diffusion Transformer framework. U-DiT preserves the multi-scale feature fusion advantages of U-Net while integrating the global context modeling capability of Transformers, thereby enhancing representational power and policy expressiveness. We evaluate U-DiT extensively across both simulation and real-world robotic manipulation tasks. In simulation, U-DiT achieves an average performance gain of 10\% over baseline methods and surpasses Transformer-based diffusion policies (DP-T) that use AdaLN blocks by 6\% under comparable parameter budgets. On real-world robotic tasks, U-DiT demonstrates superior generalization and robustness, achieving an average improvement of 22.5\% over DP-U. In addition, robustness and generalization experiments under distractor and lighting variations further highlight the advantages of U-DiT. These results highlight the effectiveness and practical potential of U-DiT Policy as a new foundation for diffusion-based robotic manipulation.