Unlocking the Potential of Soft Actor-Critic for Imitation Learning
作者: Nayari Marie Lessa, Melya Boukheddimi, Frank Kirchner
分类: cs.RO
发布日期: 2025-09-29
💡 一句话要点
提出AMP+SAC模仿学习框架,提升四足机器人运动生成的数据效率与泛化性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 模仿学习 强化学习 软演员-评论家 对抗运动先验 机器人运动控制
📋 核心要点
- 现有模仿学习方法主要依赖PPO等在线算法,样本效率和策略泛化能力存在不足。
- 本文提出AMP+SAC框架,利用离线学习和熵正则化探索,提升数据效率和鲁棒性。
- 实验表明,在四足步态任务中,AMP+SAC相比AMP+PPO实现了更高的模仿奖励和稳定的任务执行。
📝 摘要(中文)
本文提出了一种新颖的模仿学习(IL)框架,该框架结合了对抗运动先验(AMP)与离线软演员-评论家(SAC)算法,旨在克服现有方法(主要依赖近端策略优化PPO)在样本效率和策略泛化方面的局限性。该集成利用了回放驱动学习和熵正则化探索,从而实现自然的行为和任务执行,同时提高数据效率和鲁棒性。我们在涉及多个参考运动和不同地形的四足步态上评估了所提出的方法(AMP+SAC)。实验结果表明,与广泛使用的AMP+PPO方法相比,该框架不仅保持了稳定的任务执行,而且获得了更高的模仿奖励。这些发现突出了离线IL公式在推进机器人运动生成方面的潜力。
🔬 方法详解
问题定义:现有的模仿学习方法,特别是应用于机器人运动控制时,通常依赖于在线策略优化算法,如PPO。这些算法虽然稳定,但样本效率较低,需要大量的交互数据才能学习到有效的策略。此外,在线算法的泛化能力也受到限制,难以适应复杂和多变的环境。
核心思路:本文的核心思路是将对抗运动先验(AMP)与离线强化学习算法软演员-评论家(SAC)相结合。AMP提供运动先验知识,引导策略学习,而SAC的离线特性允许从有限的数据集中高效地学习策略,并通过熵正则化鼓励探索,提高策略的鲁棒性。
技术框架:该框架主要包含以下几个模块:1)专家数据收集模块,用于收集高质量的专家演示数据;2)AMP模块,用于提取专家数据的运动先验信息;3)SAC模块,作为策略学习的核心算法,利用回放缓冲区存储经验数据,并使用软Q函数和策略网络进行迭代更新;4)奖励函数设计,结合模仿学习奖励和任务奖励,引导机器人学习期望的行为。
关键创新:最重要的技术创新点在于将AMP与SAC相结合,利用SAC的离线学习能力和熵正则化特性,克服了传统在线模仿学习算法的样本效率和泛化能力不足的问题。与直接使用PPO等在线算法相比,该方法能够更有效地利用有限的专家数据,学习到更鲁棒和自然的运动策略。
关键设计:关键的技术细节包括:1)SAC算法中的温度参数α的自适应调整,以平衡探索和利用;2)奖励函数的设计,需要仔细权衡模仿学习奖励和任务奖励的比例,以确保机器人既能模仿专家行为,又能完成特定的任务;3)网络结构的设计,包括策略网络和Q网络的结构,需要根据具体的任务进行调整,以提高学习效率和性能。
🖼️ 关键图片

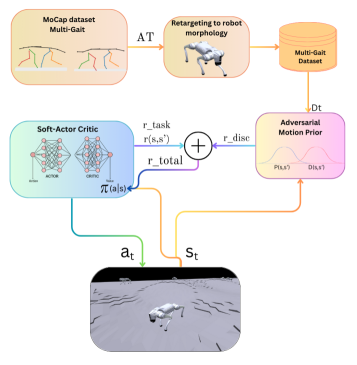

📊 实验亮点
实验结果表明,在四足步态任务中,与AMP+PPO方法相比,AMP+SAC框架在模仿奖励方面取得了显著提升。具体而言,AMP+SAC在多个参考运动和不同地形下均表现出更高的模仿奖励,同时保持了稳定的任务执行。这表明AMP+SAC能够更有效地利用专家数据,学习到更鲁棒和自然的运动策略。
🎯 应用场景
该研究成果可应用于各种机器人运动控制领域,例如四足机器人、人形机器人和机械臂。通过模仿学习,机器人可以学习到复杂的运动技能,从而在搜索救援、物流运输、医疗康复等领域发挥重要作用。此外,该方法还可以应用于游戏AI和虚拟角色控制,提升虚拟角色的自然性和智能性。
📄 摘要(原文)
Learning-based methods have enabled robots to acquire bio-inspired movements with increasing levels of naturalness and adaptability. Among these, Imitation Learning (IL) has proven effective in transferring complex motion patterns from animals to robotic systems. However, current state-of-the-art frameworks predominantly rely on Proximal Policy Optimization (PPO), an on-policy algorithm that prioritizes stability over sample efficiency and policy generalization. This paper proposes a novel IL framework that combines Adversarial Motion Priors (AMP) with the off-policy Soft Actor-Critic (SAC) algorithm to overcome these limitations. This integration leverages replay-driven learning and entropy-regularized exploration, enabling naturalistic behavior and task execution, improving data efficiency and robustness. We evaluate the proposed approach (AMP+SAC) on quadruped gaits involving multiple reference motions and diverse terrains. Experimental results demonstrate that the proposed framework not only maintains stable task execution but also achieves higher imitation rewards compared to the widely used AMP+PPO method. These findings highlight the potential of an off-policy IL formulation for advancing motion generation in robotics.