PROFusion: Robust and Accurate Dense Reconstruction via Camera Pose Regression and Optimization
作者: Siyan Dong, Zijun Wang, Lulu Cai, Yi Ma, Yanchao Yang
分类: cs.RO, cs.CV
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
PROFusion:结合相机位姿回归与优化的鲁棒精确稠密重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 稠密重建 RGB-D SLAM 相机位姿估计 深度学习 优化算法
📋 核心要点
- 现有RGB-D SLAM系统在相机快速运动或剧烈抖动时性能下降,难以保证重建精度。
- PROFusion结合学习的初始化和优化的细化,利用相机位姿回归网络提供可靠的初始位姿估计。
- 实验表明,该方法在具有挑战性的数据集上优于现有方法,并在稳定运动序列中保持了相当的精度,且能实时运行。
📝 摘要(中文)
在不稳定的相机运动下进行实时稠密场景重建对于机器人技术至关重要。然而,当前的RGB-D SLAM系统在相机经历大视角变化、快速运动或突然抖动时会失效。传统的基于优化的方法虽然能提供高精度,但在大运动期间由于初始化不良而失败;而基于学习的方法虽然具有鲁棒性,但缺乏足够的稠密重建精度。本文通过结合基于学习的初始化和基于优化的细化来解决这一挑战。该方法采用相机位姿回归网络从连续的RGB-D帧预测度量感知的相对位姿,作为随机优化算法的可靠起点,进一步将深度图像与场景几何对齐。大量实验表明了有希望的结果:我们的方法在具有挑战性的基准测试中优于最佳竞争对手,同时在稳定的运动序列中保持了相当的精度。该系统实时运行,表明结合简单而有原则的技术可以实现不稳定运动的鲁棒性和稠密重建的准确性。
🔬 方法详解
问题定义:论文旨在解决在相机运动不稳定(例如快速运动、剧烈抖动)的情况下,RGB-D SLAM系统难以进行鲁棒且精确的稠密场景重建的问题。现有基于优化的方法对初始位姿敏感,在大运动情况下容易失败;而基于学习的方法虽然鲁棒性较好,但精度不足以进行高质量的稠密重建。
核心思路:论文的核心思路是结合基于学习的相机位姿回归和基于优化的深度图对齐,利用学习方法提供一个较好的初始位姿估计,然后通过优化方法进一步提升重建精度。这种混合方法旨在兼顾鲁棒性和精度,从而在各种运动条件下都能实现高质量的稠密重建。
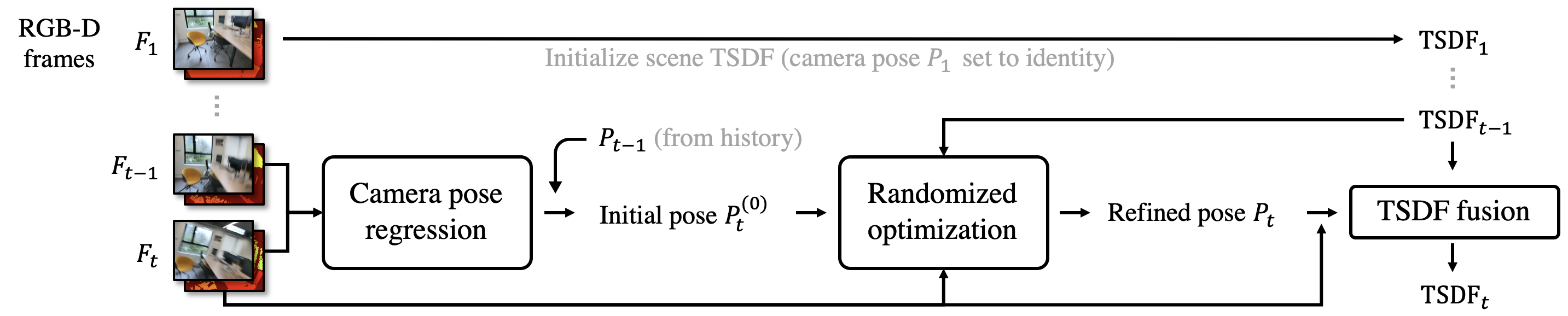
技术框架:PROFusion的整体框架包含两个主要阶段:1) 相机位姿回归:使用一个深度神经网络,输入连续的RGB-D帧,预测相机之间的相对位姿。这个网络经过训练,能够预测度量感知的位姿,为后续的优化提供一个良好的初始值。2) 深度图对齐优化:使用预测的位姿作为初始值,运行一个随机优化算法,将深度图像与场景几何进行对齐。这个优化过程旨在最小化深度图之间的差异,从而进一步提高重建精度。
关键创新:该方法最重要的创新点在于将学习和优化相结合,利用学习方法提供鲁棒的初始位姿估计,然后利用优化方法进行精细的调整。这种结合克服了传统方法在不稳定运动下的局限性,同时避免了纯学习方法精度不足的问题。此外,使用度量感知的位姿回归网络也是一个关键创新,它能够提供更准确的初始位姿估计。
关键设计:相机位姿回归网络的设计细节未知,但可以推测其损失函数可能包含位姿误差和旋转误差的加权和。优化算法的具体选择未知,但可能是基于ICP(Iterative Closest Point)或其变种的随机优化算法。关键参数可能包括优化迭代次数、采样策略、以及深度图对齐的损失函数权重等。这些参数需要根据具体场景进行调整,以达到最佳的重建效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PROFusion在具有挑战性的基准测试中优于最佳竞争对手,尤其是在相机运动不稳定时,重建精度提升显著。在稳定的运动序列中,PROFusion保持了与现有方法相当的精度。此外,该系统能够实时运行,证明了其在实际应用中的可行性。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
PROFusion在机器人导航、增强现实、虚拟现实等领域具有广泛的应用前景。该方法能够提高机器人在复杂环境中的定位和建图能力,从而实现更智能的自主导航。在AR/VR应用中,该方法可以提供更稳定和精确的场景重建,从而提升用户体验。此外,该方法还可以应用于三维重建、文物数字化等领域,具有重要的实际价值和潜在的社会影响。
📄 摘要(原文)
Real-time dense scene reconstruction during unstable camera motions is crucial for robotics, yet current RGB-D SLAM systems fail when cameras experience large viewpoint changes, fast motions, or sudden shaking. Classical optimization-based methods deliver high accuracy but fail with poor initialization during large motions, while learning-based approaches provide robustness but lack sufficient accuracy for dense reconstruction. We address this challenge through a combination of learning-based initialization with optimization-based refinement. Our method employs a camera pose regression network to predict metric-aware relative poses from consecutive RGB-D frames, which serve as reliable starting points for a randomized optimization algorithm that further aligns depth images with the scene geometry. Extensive experiments demonstrate promising results: our approach outperforms the best competitor on challenging benchmarks, while maintaining comparable accuracy on stable motion sequences. The system operates in real-time, showcasing that combining simple and principled techniques can achieve both robustness for unstable motions and accuracy for dense reconstruction. Project page: https://github.com/siyandong/PROFusion.